여기서는 R의 가장 중요한 데이터 구조라 할 수 있는 데이터프레임(data.frame)에 대해서 설명한다.
현장에서 엑셀 파일로 데이터를 수집하여 사용하는 경우가 많아, R에서 엑셀 파일을 읽는 일을 흔히 보게 된다. 이런 엑셀 파일을 읽으면 R 데이터프레임으로 읽는다. 그래서 엑셀 파일을 읽는 방법과 데이터프레임의 기초에 대해서 순서대로 설명한다.
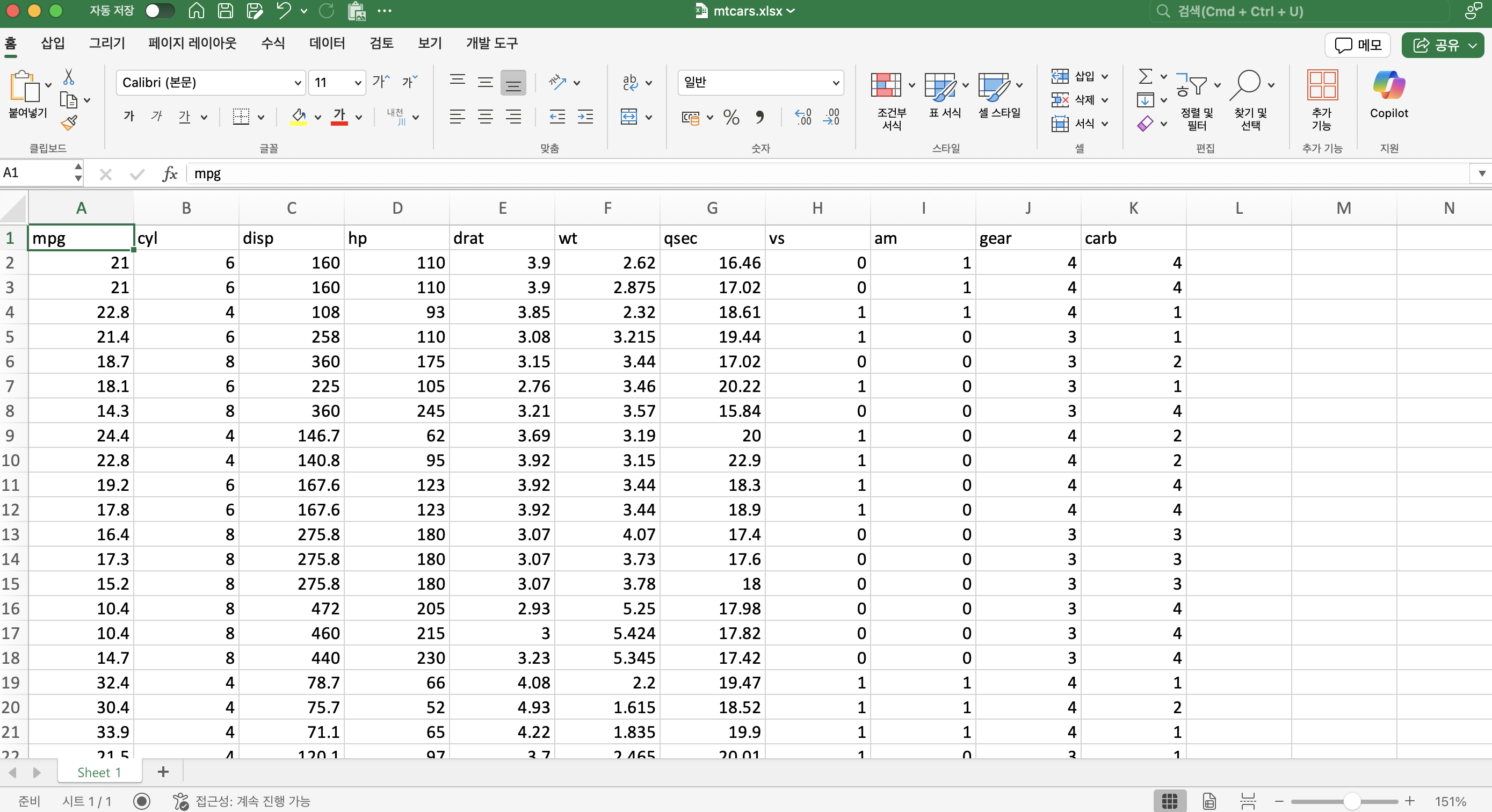
다음 엑셀 파일이 워킹 디렉터리의 excel-data 폴더에서 mtcars.xlsx 파일로 존재하다고 가정한다. 파일을 다운로드하여 현재 디렉터리에 excel-data 폴더를 만들고 그 안에 저장하자.
엑셀 파일 열어서 보기
이 파일에 들어 있는 데이터는 R을 설치할 때 함께 포함되는 mtcars라는 데이터를 엑셀로 만들어 저장한 것이다.
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
R (또는 Python)과 같은 언어를 통해 데이터를 분석할 것을 고려한다면 엑셀 데이터가 어떤 식으로 정리되어야 하는지 생각해 보자. 엑셀에서는 많은 사용자가 그러하듯이 사용자가 유연하게 데이터를 입력하고, 계산을 하고, 그래프나 표를 만들어 쓸 수 있다. 만약에 하나의 엑셀 시트에서 이런 것들이 뒤섞여 있으면 R과 같은 도구로 데이터를 불러올 때 원 데이터를 읽어올 위치 등을 상세하게 지정해 주어야 한다. 따라서 R 언어를 사용하여 분석할 데이터는 다음 그림과 같이 내용을 구성할 것을 권한다.
첫 행은 열 이를으로 사용한다.
제목을 쓰고, (보기 편하게) 빈 행을 만들거나 하지 않는다.
열 이름을 (한글 이름 대신) 알파벳으로 빈칸 없이 만든다. 나중에 이것을 변수의 이름으로 사용해야 하기 때문에 다시 다른 이름으로 바꾸거나 하는 등의 작업이 필요할 수 있다.
두 번째 행부터 바로 데이터가 채워진다.
메타 정보는 별도의 시트나 파일로 따로 정리하여 사용하는 것이 좋다.
이 파일이 excel-data 폴더에 mtcars.xlsx으로 있고 이제 이것을 읽어보자.
RStudio에서 엑셀 파일 읽기
R에는 인터넷만 연결되어 있으면 데이터에 어디에 있던 어떤 포맷으로 되어 있던 데이터를 읽는 도구들이 개발되어 있다.
여기선 가장 기초적인 현재 컴퓨터에 있는 엑셀 파일을 읽어보자. RStudio에는 이런 작업을 쉽게 할 수 있는 기능이 내장되어 있다.
RStudio를 실행하고 따라해 보자.
이 기능은 readxl이라는 패키지를 이용하는데, 만약 현재 컴퓨터에 이 패키지가 설치되어 있지 않다면 이 패키지를 다운로드하라는 안내를 보게 될 것이다. 다운로드하여 설치한다.
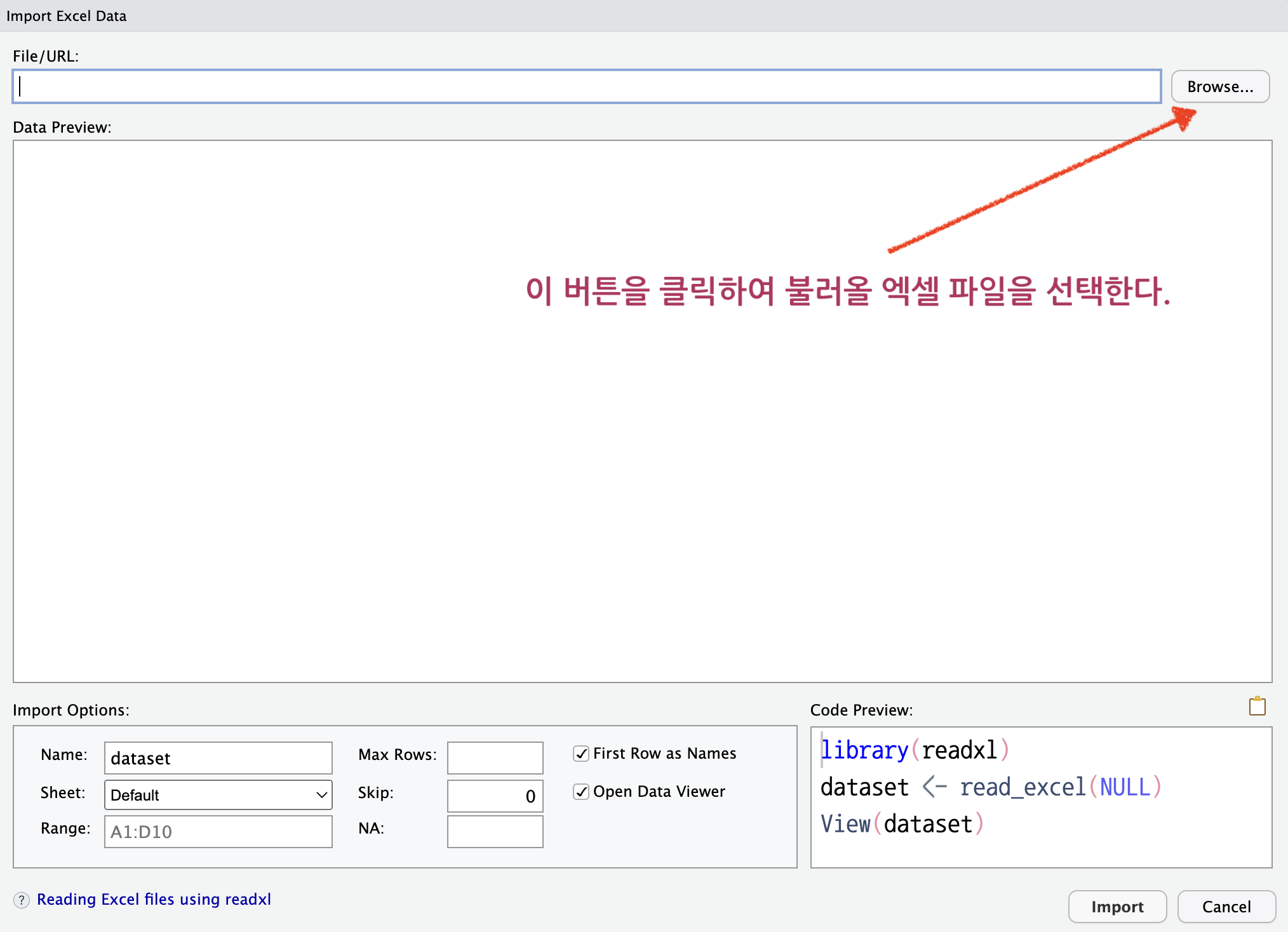
“From Excel…” 을 클릭하면 그림 4.3 창이 열린다. 여기서 Browse… 버턴을 클릭하여 읽을 파일을 찾아서 선택한다.
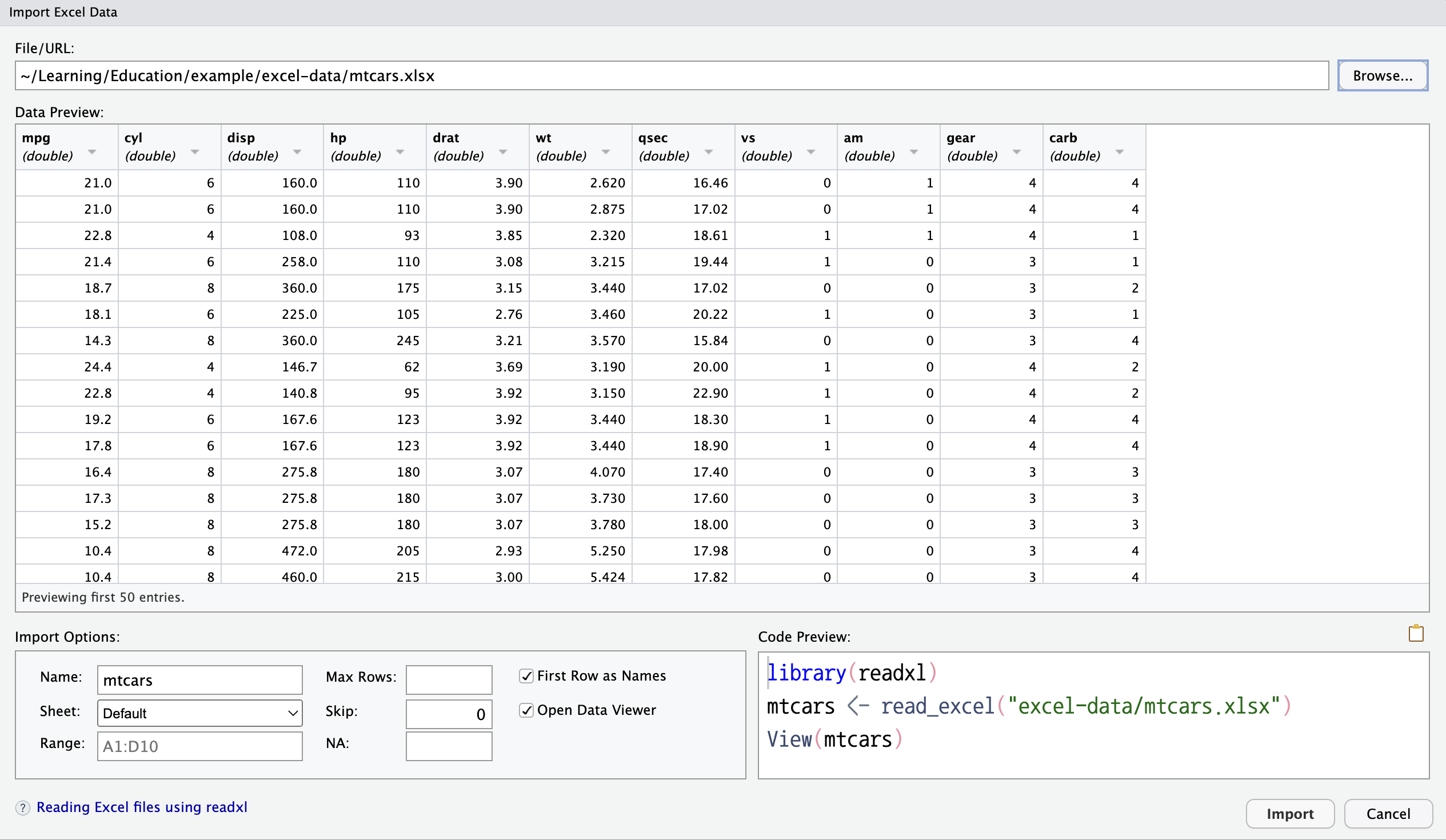
만약 읽을 때 문제가 없을 경우 그림 4.4 창과 같이 보인다.
여기서 데이터를 잘 읽었는지 확인한다. 오른쪽 아래에 이 과정을 코드로 만들어 주고 있다. 이것을 클릭보드에 복사하여 스크립트 등에 사용하면 편리한다.
여기서 오른쪽 아래 Import 버튼을 클릭하면 이 데이터를 mtcars라는 데이터프레임으로 읽어 온다. 이 방법은 엑셀 파일 이름과 같은 이름으로 데이터프레임으로 읽어 온다(정확히는 tibble이라는 데이터 구조로 읽는데, 전통적인 데이터프레임을 강화한 형태의 데이터프레임이다). 이제 R 세션에 mtcars라는 데이터프레임이 만들어졌다.
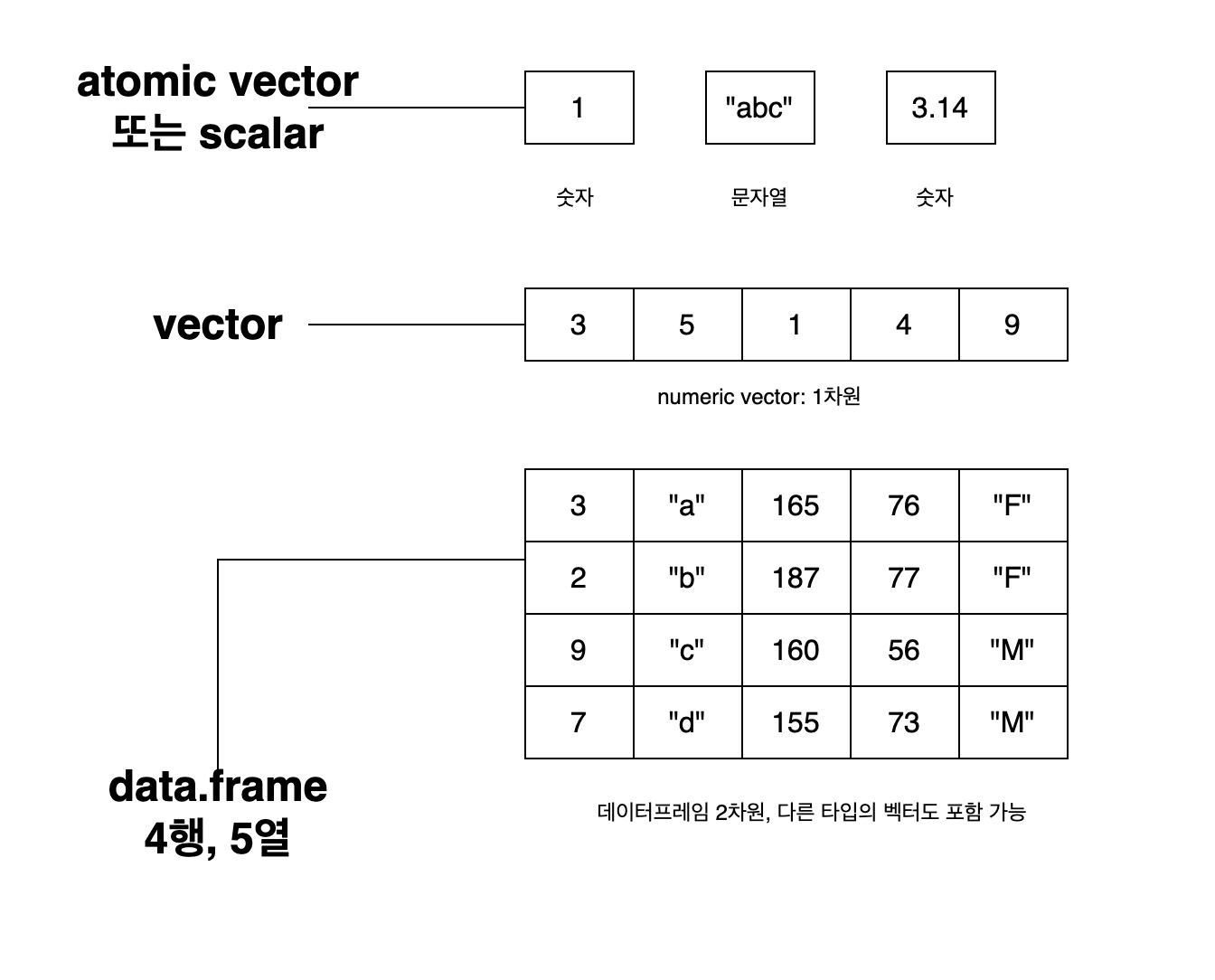
데이터프레임
R 데이터프레임(data.frame)은 엑셀 시트와 비슷한 2차원으로 된 데이터 구조이다. 다음과 같이 데이터를 읽었을 때 tibble 데이터프레임으로 저장하는 데 설명을 위해서, 원래의 데이터프레임으로 만든다(그 이름은 df로 줬다).
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
str() num)으로 되어 있다는 것을 알 수 있다.
'data.frame': 32 obs. of 11 variables:
$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
$ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
$ disp: num 160 160 108 258 360 ...
$ hp : num 110 110 93 110 175 105 245 62 95 123 ...
$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
$ wt : num 2.62 2.88 2.32 3.21 3.44 ...
$ qsec: num 16.5 17 18.6 19.4 17 ...
$ vs : num 0 0 1 1 0 1 0 1 1 1 ...
$ am : num 1 1 1 0 0 0 0 0 0 0 ...
$ gear: num 4 4 4 3 3 3 3 4 4 4 ...
$ carb: num 4 4 1 1 2 1 4 2 2 4 ...
변수, 즉 열 일이름은 names()
[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear"
[11] "carb"
데이터프레임에서 앞 부분을 볼 때는 head() tail()
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
mpg cyl disp hp drat wt qsec vs am gear carb
27 26.0 4 120.3 91 4.43 2.140 16.7 0 1 5 2
28 30.4 4 95.1 113 3.77 1.513 16.9 1 1 5 2
29 15.8 8 351.0 264 4.22 3.170 14.5 0 1 5 4
30 19.7 6 145.0 175 3.62 2.770 15.5 0 1 5 6
31 15.0 8 301.0 335 3.54 3.570 14.6 0 1 5 8
32 21.4 4 121.0 109 4.11 2.780 18.6 1 1 4 2
데이터프레임은 벡터를 하나로 모은 것
데이터프레임은 1차원 벡터를 세워서 2차원으로 만든 것이라 보면 된다. 하나의 벡터를 구성하는 값의 데이터 타입은 모두 같아야 하는데(homogeneous), 데이터프레임을 구성하는 벡터는 타입이 달라도 상관없다(heterogeneous).
값들을 c() data.frame()
id <- 1 : 3 p_name <- c ( "A" , "B" , "C" ) p_wt <- c ( 90 , 76 , 67 ) p_ht <- c ( 185 , 179 , 160 ) p_df <- data.frame ( id , p_name , p_wt , p_ht ) p_df
id p_name p_wt p_ht
1 1 A 90 185
2 2 B 76 179
3 3 C 67 160
이것을 하나의 데이터프레임으로 묶을 수 있는 이유는 4개의 벡터의 길이가 모두 3이기 때문이다.
벡터에서는 []라는 사용한 인덱싱 방법으로 값에 접근했다. 데이터프레임도 같은 방법으로 해당 데이터프레임에 있는 벡터나 또는 개별 값을 가지고 올 수 있다. 이 방법에 대해 알아보자.
먼저 $를 사용하는 방법이 있다. 다음과 같이 데이터프레임이름$열이름이라는 문법을 사용하여 데이터프레임에서 벡터를 가지고 올 수 있다.
앞 절에서 엑셀 데이터로 만든 df 데이터프레임에서 mpg라는 변수를 가지고 올 때는 다음과 같이 실행한다.
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4
[16] 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7
[31] 15.0 21.4
어쩔 수 없이 데이터프레임의 열 이름이 띄어쓰기 있다고 가정해 보자. 벡터에서 값의 이름을 바꾸는 경우와 값이 names()
names ( p_df ) [ 4 ] <- "환자 키" p_df
id p_name p_wt 환자 키
1 1 A 90 185
2 2 B 76 179
3 3 C 67 160
이렇게 된 경우에는 다음과 같이 따옴표를 사용해야 한다.
[] 또는 [[]]을 사용한 세브셋팅
벡터의 서브셋팅을 다룰 때 다음과 같이 정리했었다.
하나의 정수, 또는 정수형 벡터: 해당 위치의 값
음의 정수 또는 정수형 벡터 앞에 마이너스: 해당 위치의 값을 제외
아무 것도 없음: All
불리언 또는 불리언 벡터: TRUE의 위치의 있는 값들을 추출
이 원리를 2차원 벡터에 적용할 수 있다. 다만 [행, 열]과 같이 코마로서 행의 조건과 열의 조건을 다르게 지정할 수 있다는 점이 다르다.
또 약간 다른 점은 벡터에서는 값에 이름을 붙여서 사용하는 경우가 드물기 때문에 [] 안에 인덱스 숫자를 많이 사용하지만, 데이터프레임의 경우에는 행은 보통 행 번호 인덱스롤, 열은 보통 열 이름을 사용한다.
다음 코드를 보자. 이 경우에는 행의 조건을 주는 부분이 빈 채로 되어 있어서 “모든 행”을 의미한다. 그러고 열의 자리에 "mpg"라는 열 이름을 주었다. 열을 기준으로 보면 "mpg"라는 열의 값을 가지고 오는데 모든 행의 값을 가지고 오라는 뜻이다.
[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4
[16] 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7
[31] 15.0 21.4
다음은 "mpg"라는 열에서 1번에서 5번 행까지의 값만 가지고 오라는 뜻이다.
[1] 21.0 21.0 22.8 21.4 18.7
다음 경우에는 "mpg", "wt" 열을 가지고 오는 1번에서 5번까지의 행만 가지고 오라는 뜻이 된다.
mpg wt
1 21.0 2.620
2 21.0 2.875
3 22.8 2.320
4 21.4 3.215
5 18.7 3.440
다음은 p_df에서 3번째 행의 값을 보는데, 열 조건이 빈 상태이기 때문에 “모든 열”이 된다.
id p_name p_wt 환자 키
3 3 C 67 160
다음은 df의 4행, 10열의 값을 가지고 오는 코드이다.
주의 깊게 살펴보면 사실 인덱싱의 결과가 어떤 때는 하나의 값(atomic vector)가 되고, 어떤 경우에는 벡터, 어떤 경우에는 2차원 데이터프레임을 유지한다. 이런 경우들은 처음 배울 때는 넘어가고, 나중에 하나씩 고민해도 된다.