library(tidyverse)
df <- tibble(
group = c("A", "A", "B", "B", "B"),
value = c(10, 20, 10, 30, 20)
)
df# A tibble: 5 × 2
group value
<chr> <dbl>
1 A 10
2 A 20
3 B 10
4 B 30
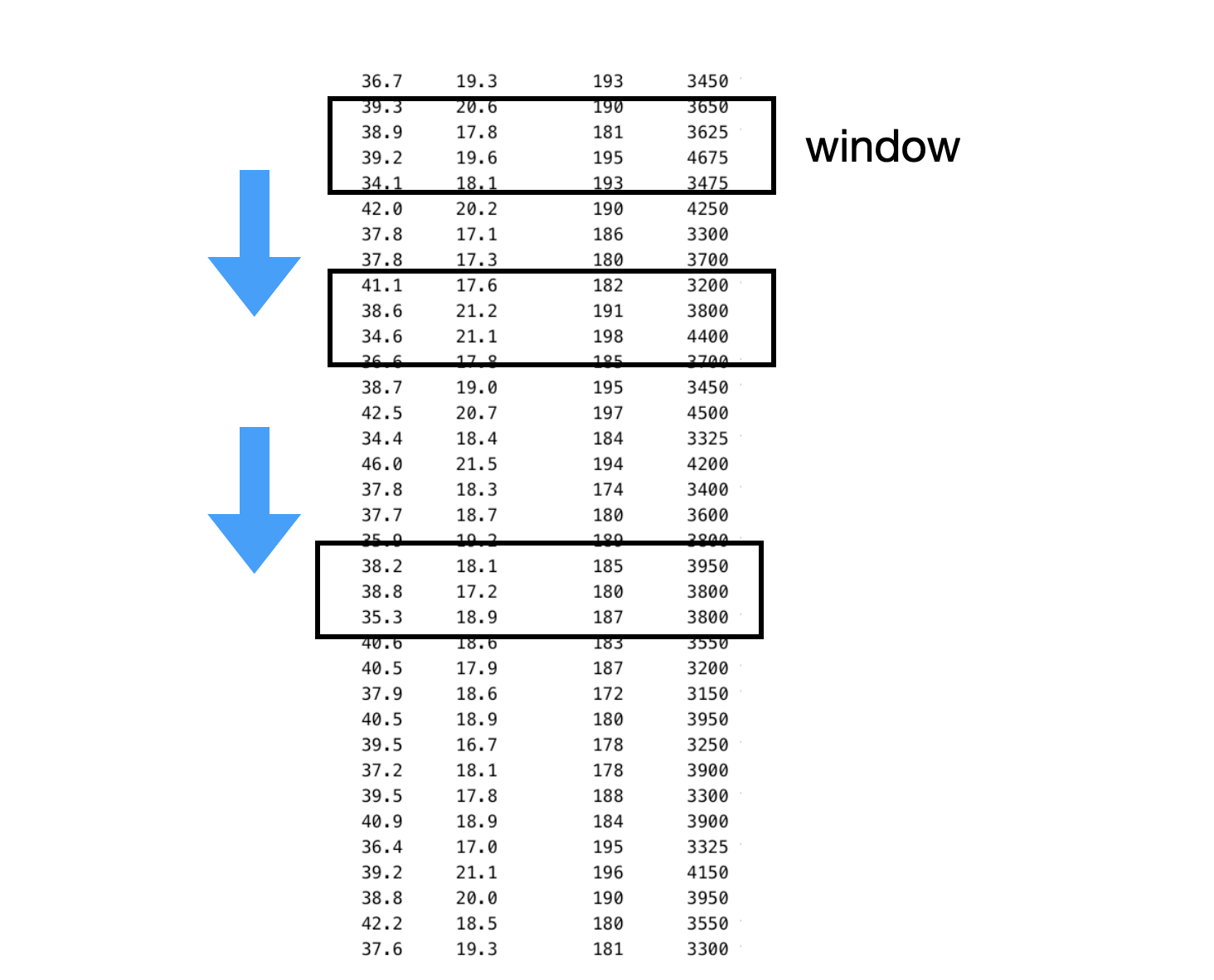
5 B 20윈도우 함수(window function)는 그림 15.1와 같이 행 집합에 대해 계산을 수행하는 함수들로, 다음과 같은 계산에 사용된다.
간단한 데이터셋을 만들어 윈도우 함수의 작동 방식을 이해하자.
library(tidyverse)
df <- tibble(
group = c("A", "A", "B", "B", "B"),
value = c(10, 20, 10, 30, 20)
)
df# A tibble: 5 × 2
group value
<chr> <dbl>
1 A 10
2 A 20
3 B 10
4 B 30
5 B 20누적 합계는 cumsum() 함수를 사용한다.
# A tibble: 5 × 3
group value cumsum
<chr> <dbl> <dbl>
1 A 10 10
2 A 20 30
3 B 10 40
4 B 30 70
5 B 20 90만약에 그룹화 데이터프레임을 사용하면 그룹별로 누적 합계를 계산한다.
# A tibble: 5 × 3
# Groups: group [2]
group value cumsum
<chr> <dbl> <dbl>
1 A 10 10
2 A 20 30
3 B 10 10
4 B 30 40
5 B 20 60앞, 뒤의 값을 참조할 때는 lag(), lead() 함수를 사용한다.
# A tibble: 5 × 4
group value previous_value next_value
<chr> <dbl> <dbl> <dbl>
1 A 10 NA 20
2 A 20 10 10
3 B 10 20 30
4 B 30 10 20
5 B 20 30 NA만약 그룹화 데이터프레임을 사용하면 그룹별로 앞, 뒤의 값을 참조한다.
# A tibble: 5 × 4
# Groups: group [2]
group value previous_value next_value
<chr> <dbl> <dbl> <dbl>
1 A 10 NA 20
2 A 20 10 NA
3 B 10 NA 30
4 B 30 10 20
5 B 20 30 NA순위를 부여하는 함수들이 있다.
row_number(): 순위를 부여하는 데 값이 같으면 데이터 순서대로 순위를 부여한다.min_rank(): 순위를 부여하는 데 값이 같으면 같은 순위를 부여하고, 그 다음 순위는 건너뛴다.dense_rank(): 순위를 부여하는 데 값이 같으면 같은 순위를 부여하고, 그 다음 순위는 건너뛰지 않는다.df %>%
mutate(
row_number_value = row_number(value),
rank_value = min_rank(value),
dense_rank_value = dense_rank(value)
)# A tibble: 5 × 5
group value row_number_value rank_value dense_rank_value
<chr> <dbl> <int> <int> <int>
1 A 10 1 1 1
2 A 20 3 3 2
3 B 10 2 1 1
4 B 30 5 5 3
5 B 20 4 3 2만약 그룹화 데이터프레임을 사용하면 그룹별로 순위를 부여한다.
df %>%
group_by(group) %>%
mutate(
row_number_value = row_number(value),
rank_value = min_rank(value),
dense_rank_value = dense_rank(value)
)# A tibble: 5 × 5
# Groups: group [2]
group value row_number_value rank_value dense_rank_value
<chr> <dbl> <int> <int> <int>
1 A 10 1 1 1
2 A 20 2 2 2
3 B 10 1 1 1
4 B 30 3 3 3
5 B 20 2 2 2