22 ggplot2 레이어(layers)와 통계적 변환(stats)
이 장에서는 ggplot2 패키지의 ggplot2의 레이어(layer)에 대해서 설명하고, Statistical Transformation 개념을 이해하고 활용하는 방법을 소개한다.
22.1 ggplot2의 레이어(layer)
ggplot2는 레이어를 + 연산자를 사용하여 하나씩 쌓아올리면서 그래프를 만든다.
ggplot2에서 레이어는 다음 5가지 구성요소를 가지고 있다. 이 5가지 요소가 모두 갖춰어져야 하나의 레이어가 완성된다.
- 매핑(mapping)
- 데이터(data)
- 지옴(geom)
- 통계학적 변환(stat)
- 위치(position)
layer()라는 함수를 가지고 이 5가지 요소를 모두 지정하여 레이어를 만들 수 있다. 그러나 이런 방법으로 작업하기는 시간과 노력이 많이 소요된다. 대신 ggplot2는 보통 다음 2가지 방법으로 레이어를 만든다.
-
geom_*()함수 -
stat_*()함수
geom_*() 함수는 레이어의 구성 요소 가운데 기하학적 요소인 지옴에서 시작한다.
ggplot(mtcars) +
geom_point(aes(wt, mpg))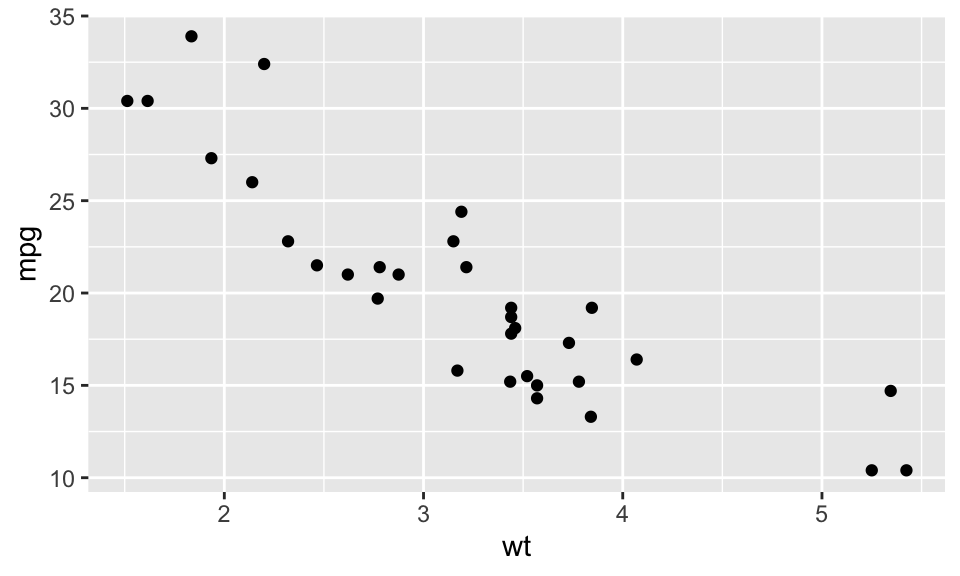
반면 stat_*() 함수는 통계학적 변환(stat)에서 시작한다.
ggplot(mtcars) +
stat_identity(aes(wt, mpg))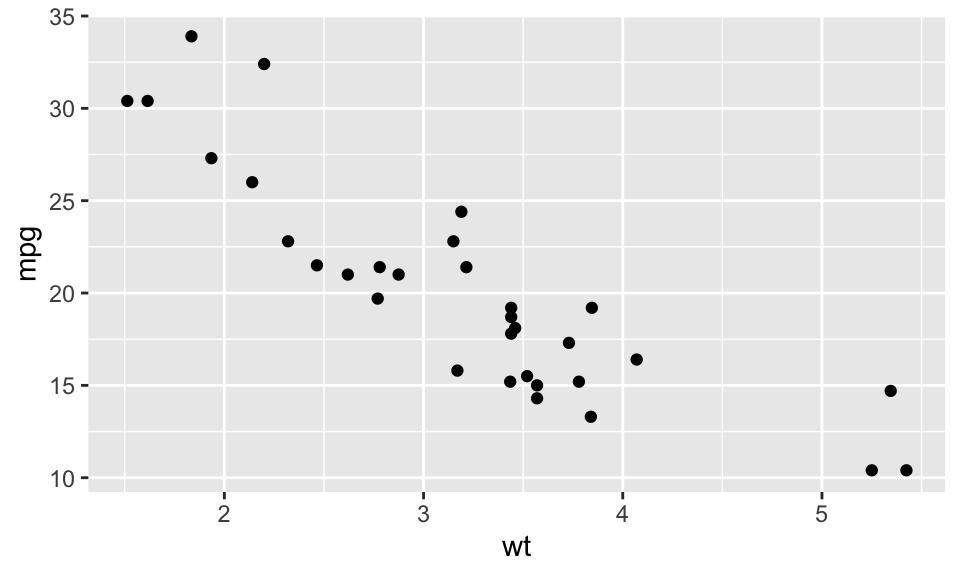
두 함수가 시작하는 지점은 다르지만 결과는 같다. 5가지가 다 충족하지 않는 것 같지만 빠진 부분은 ggplot2가 설정해 놓은 디폴트를 사용하기 때문에 보이지 않는 것일 뿐이다.
ggplot(mtcars) +
geom_point(aes(wt, mpg))위 코드에서 geom_point()가 생성하는 레이어의 데이터는 ggplot()이라는 모 함수의 것을 그대로 사용하고 있다(data). 매핑은 보이는 바와 같이 aes(wt, mpg)로 x, y position aesthetics에 매핑되고 있다(mapping). 당연히 point 지옴이 사용되고 있다(geom). geom_point()는 stat = "identity"(항등 함수)라는 통계적 변환을 사용한다(stat). 그리고 position = "identity"라는 위치(position) 요소를 디폴트로 사용한다. 따라서 이런 5가지 요소가 갖추어지기 때문에 산점도가 완성된다.
다음 코드도 마찬가지이다. 다만 stat에서 시작하고, stat_identity() 함수의 디폴트인 point 지옴이 사용된다. 나머지도 위와 같은 개념이 적용된다.
ggplot(mtcars) +
stat_identity(aes(wt, mpg))이 장에서 주로 설명할 stat_*() 모양의 함수들을 통계적 변환에서 시작하여, 하나의 레이어를 완성해 나간다. 함수 자체로 레이어를 완성하든 아니면 앞의 ggplot() 함수의 것을 가지고 오든 레이어가 완성되려면 앞에서 설명한 5가지 요소가 다 갖춰야 한다는 점을 주의할 필요가 있다.
22.2 Statistical Transformation의 역할 이해
보통 처음 ggplot2() 패키지를 배울 때는 기존 통계나 수학 지식을 바탕으로 히스토그램을 만들 때는 geom_histogram(), 박스 플롯을 만들 때는 geom_boxplot(), 산점도(scatter plot)을 만들 때는 geom_point() 등으로 접근하는 것이 직관적이기 때문에 이 방법으로 접근한다. 이 경우에도 보이지는 않지만 다음과 같이 statistical transformation이 사용된다.
-
geom_point():stat = "identity" -
geom_bar():stat = "count" -
geom_histogram():stat = "bin"
예를 들어, 막대 그래프를 만들 때 우리는 다음과 같이 시작한다.
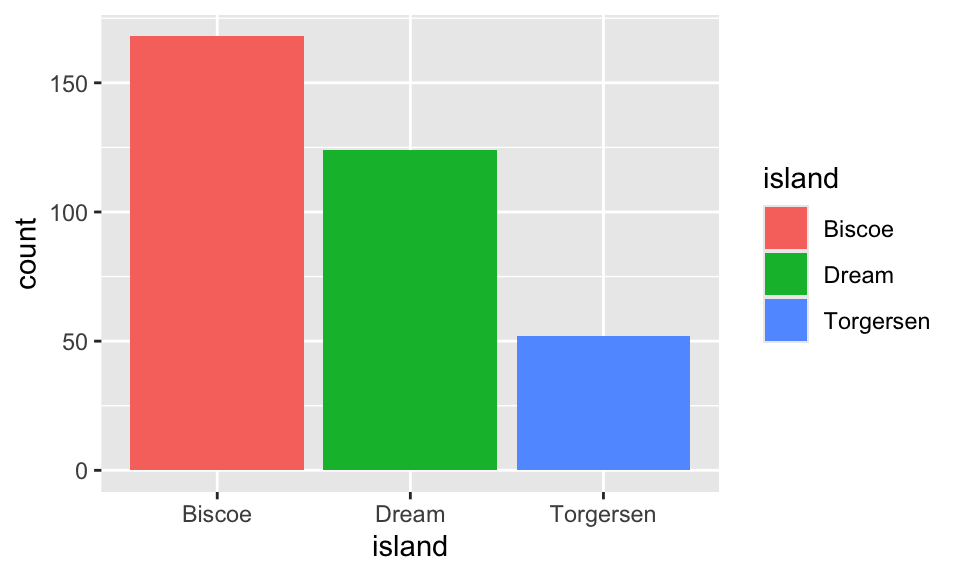
이 경우 우리는 x aesthetic만 island 변수에 매핑시켰는데도 막대 그래프가 완성된다. 그것은 내부에서 stat = "count"에 의해서 각 섬(island)의 값들을 카운트하고 이 값을 막대의 높이 매핑하기 대문이다. dplyr 패키지로 이것을 계산해 보면 다음과 같을 것이다. 내부에서 이와 비슷한 계산을 해 주는 것인 statistical transformation이다.
# A tibble: 3 × 2
# Groups: island [3]
island count
<fct> <int>
1 Biscoe 168
2 Dream 124
3 Torgersen 52만약 "count"가 아니라 비율(portion) 값으로 그래프를 만들려면 geom_bar()의 매핑에서 이것을 선택하면 된다. after_scale() 함수의 사용법은 뒤에서 설명한다. group = 1은 전체 그룹에 대하여 island의 카운트를 고려하라는 뜻이다. 지옴(geom)에 따라 어떤 statistical transformation을 사용할 수 있는지는 해당 지옴의 도움말을 보면 computed variables 항목을 보면 알 수 있다.
penguins |>
ggplot(aes(x = island)) +
geom_bar(aes(y = after_stat(prop), group = 1))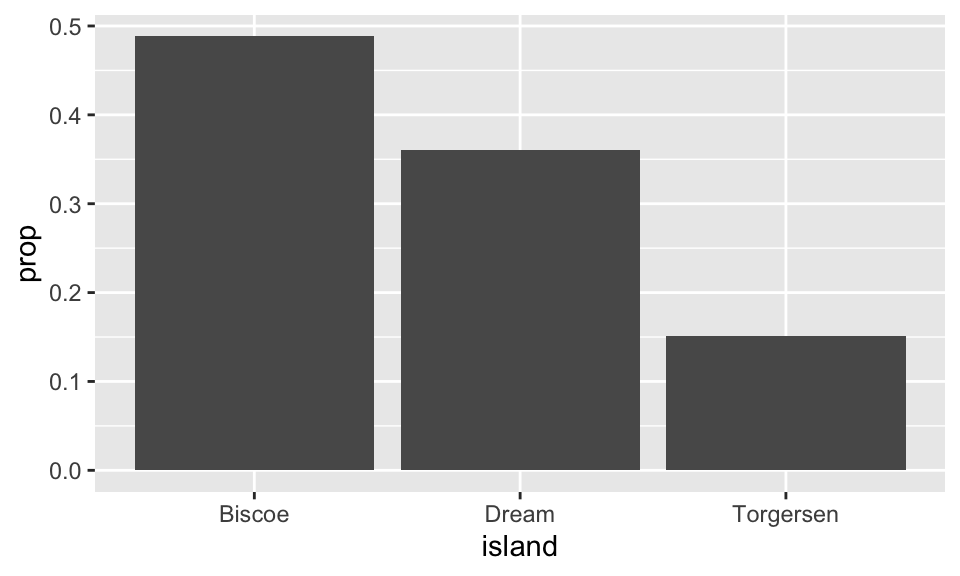
이것은 다음 값들을 폴롯팅한 결과이다.
# A tibble: 3 × 3
island count prop
<fct> <int> <dbl>
1 Biscoe 168 0.488
2 Dream 124 0.360
3 Torgersen 52 0.151ggplot2 패키지로 그래프를 만들다 보면 어떤 경우에는 어떻게 매핑해야 하는지 헷갈릴 수 있다. 그런 경우에는 dplyr 패키지 등을 사용하여 데이터프레임으로 데이터를 명확히 하고, ggplot2 코드는 가급적 간단하게 하는 것도 한 가지 방법일 수 있다.
22.3 통계 써머리 데이터를 가지고 그래프를 만들기
어떤 경우에는 기하학적 객체(지옴)가 아니라 statistical summary 등이 우선 머리에 떠오를 때가 있다. 다음 예를 보자.
ggplot(mtcars, aes(x = factor(cyl), y = mpg)) +
geom_boxplot()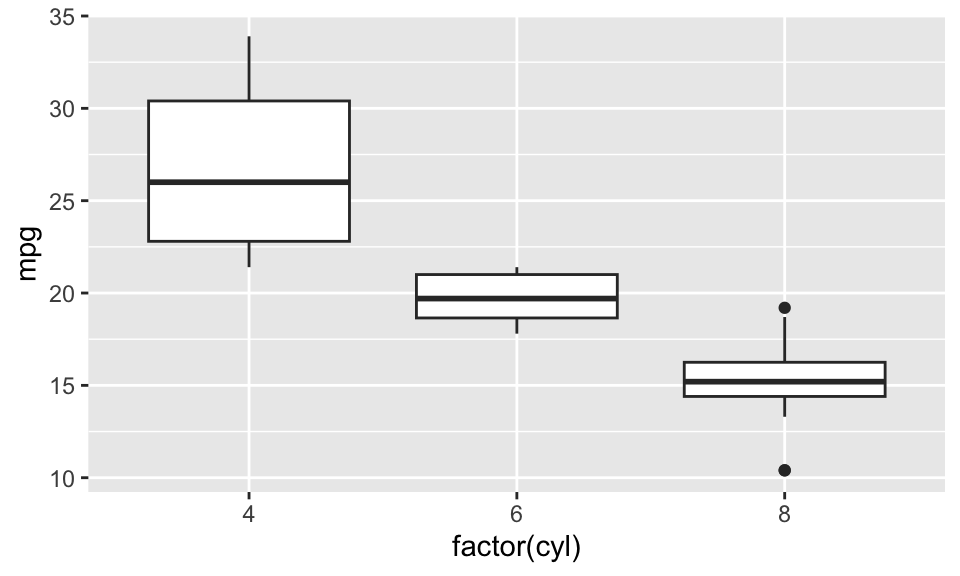
박스 플롯의 가운데 가로 막대는 중앙값(median)을 표시한다. 만약 우리가 평균값을 해당 위치에 점으로 표시하고 싶을 수 있다. 필요한 정보를 생각해 보자.
- 일단
cyl별로 평균값이 필요하겠다. 이 값은 점의y위치가 될 것이다. - 점의
x위치는 위의x축의 위치가 같다.
이럴 때 유용하게 사용되는 함수가 stat_summary()이다. 이 함수는 다음과 같이 사용한다.
ggplot(mtcars, aes(x = factor(cyl), y = mpg)) +
geom_boxplot() +
stat_summary(fun = "mean", geom = "point", shape = 8, color = "red", size = 2)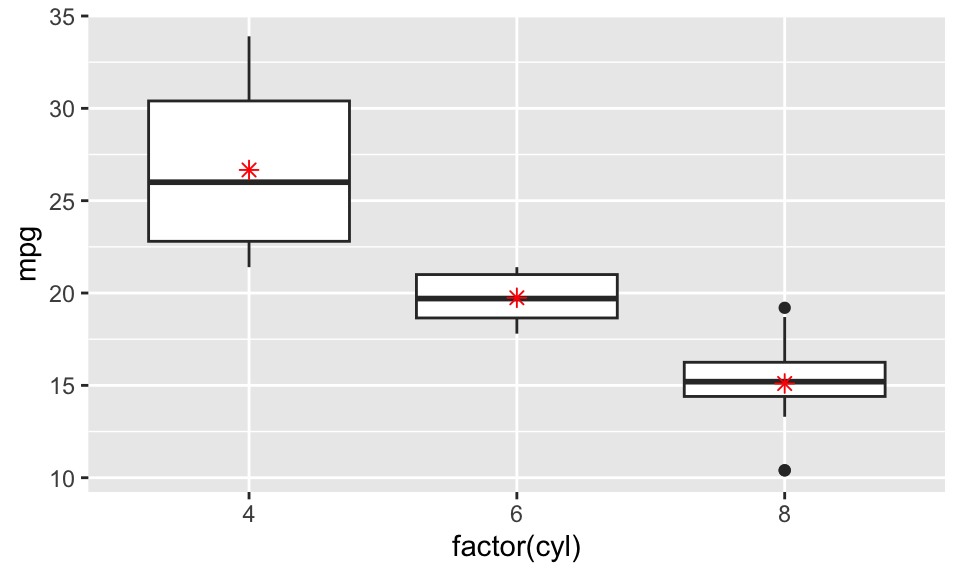
위 코드를 쪼개서 생각해 보자.
fun = "mean"은mean()함수를 사용하라는 뜻이다.stat_summary()함수는 주어진x에 대하여y의 통계량을 계산한다. 즉cyl팩터가4인 경우에는 이것의 평균값을y의 위치로 매핑한다.x매핑을ggplot()에서 정의하였기 때문에 이것을 가지고 온다. 따라서x,y위치가 결정된다.geom = "point"를 통해서 점 geom을 선택했다. 이 점의 색깔과 형태를 (매핑이 아닌) 셋팅으로 지정했다.
다음은 cyl 그룹별로 카운팅한 값을 일정한 위치에 표시해 본 예이다. 설명을 위해서 약간 꼬아 놓은 예로, stat_summary()를 사용하면서 이것은 text 지옴으로 표시하고자 하였다. text 지옴의 x, y, label aesthetic이 필요하기 때문에 label을 만들기 위해 미리 데이터프레임에 계산을 했다.
# A tibble: 32 × 12
mpg cyl disp hp drat wt qsec vs am gear carb cyl_count
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
1 21 6 160 110 3.9 2.62 16.5 0 1 4 4 7
2 21 6 160 110 3.9 2.88 17.0 0 1 4 4 7
3 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1 11
4 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1 7
5 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2 14
6 18.1 6 225 105 2.76 3.46 20.2 1 0 3 1 7
7 14.3 8 360 245 3.21 3.57 15.8 0 0 3 4 14
8 24.4 4 147. 62 3.69 3.19 20 1 0 4 2 11
9 22.8 4 141. 95 3.92 3.15 22.9 1 0 4 2 11
10 19.2 6 168. 123 3.92 3.44 18.3 1 0 4 4 7
# ℹ 22 more rowsdf |>
ggplot(aes(factor(cyl), y = mpg, label = cyl_count)) +
geom_boxplot() +
stat_summary(aes(y = 35), geom = "text")No summary function supplied, defaulting to `mean_se()`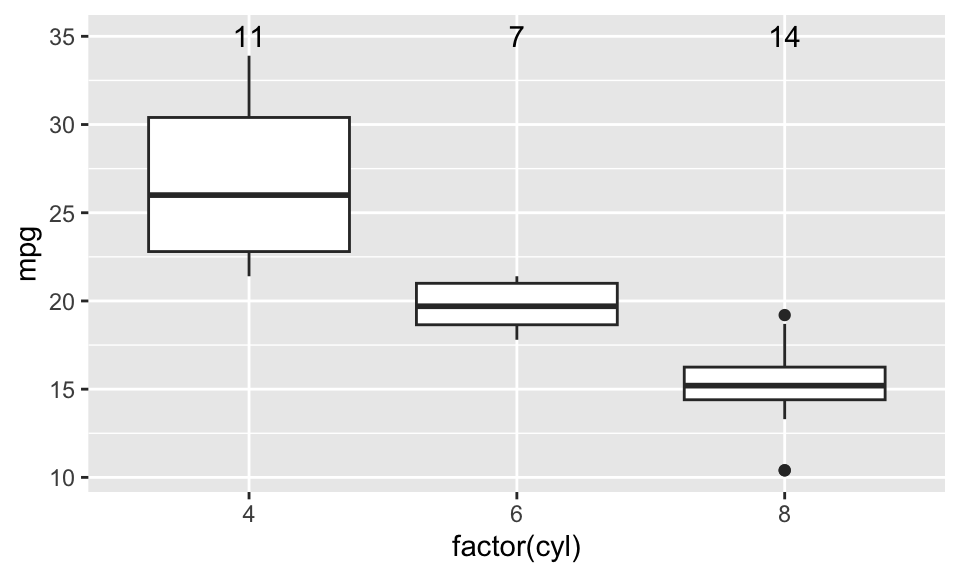
이 경우에는 stat_summary() 함수는 text 지옴을 사용했고, x, y, label 지옴을 사용하여 하나의 레이어를 완성했다.
22.4 stat_function() 함수로 수학 함수를 그래프로 그리기
stat_function() 함수는 우리가 알고 있는 수학 함수들을 만들 때 편리하다. fun 인자에는 수학 함수를 R 언어 형태로 기술한다. 여기서는 anonymous function으로 지정했다.
ggplot() +
stat_function(fun = \(x) x^2, xlim = c(-5, 5))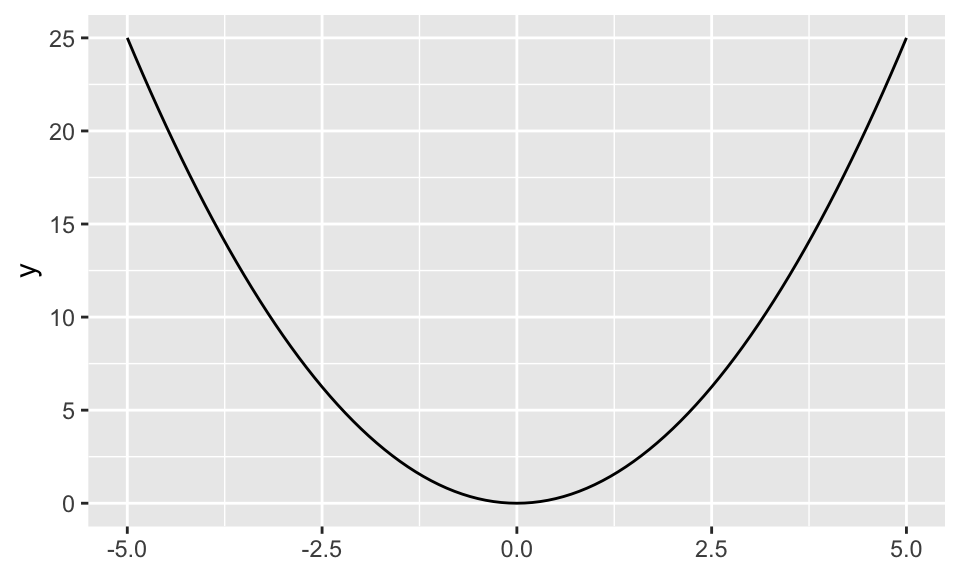
이 함수로 통계 분포 함수를 쉽게 그릴 수 있다.
# 표준 정규 분포
ggplot() +
stat_function(fun = dnorm, xlim = c(-5, 5))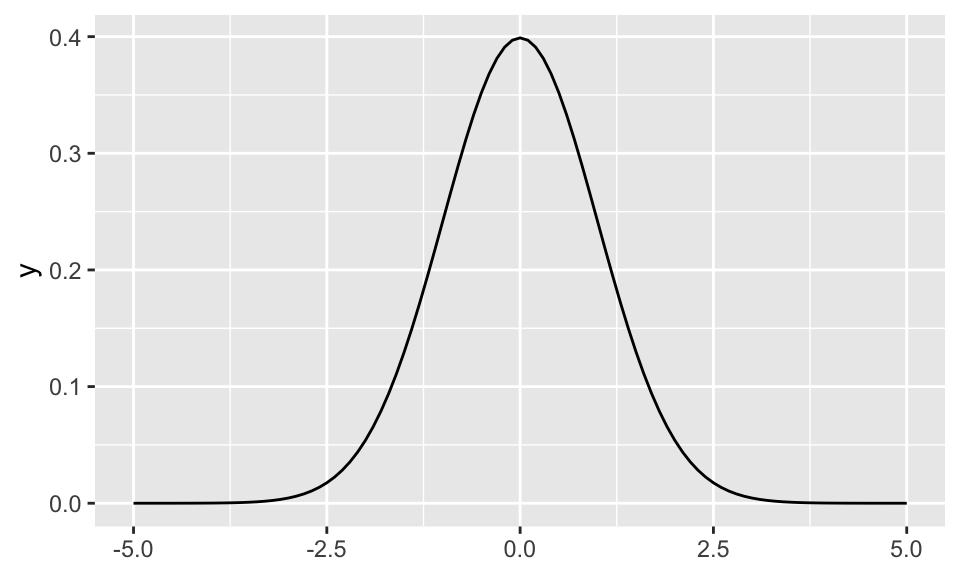
# 곡선 아래 면적으로 채움
ggplot() +
stat_function(fun = dnorm, geom = "polygon", xlim = c(-5, 5), fill = "steelblue")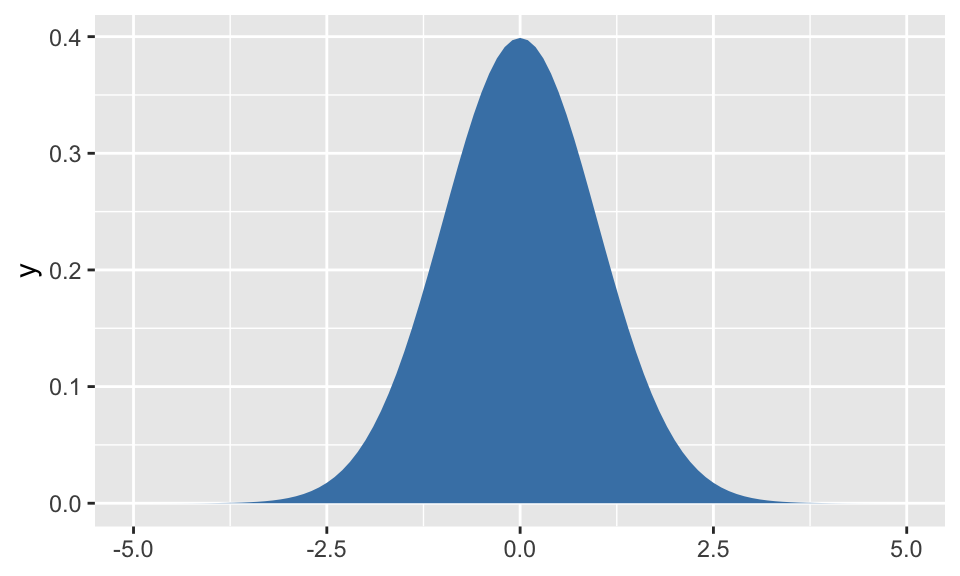
22.5 Stat을 사용하는 대표적인 경우: 불확실성에 대한 시각화
아마도 우리가 stat을 사용해야 하는 가장 흔한 경우는 불확실성에 대한 시각화일 것이다. 이런 목적을 위해 ggplot2는 다음과 같은 지옴 함수를 지원하다.
먼저 geom_errorbar()를 보자. 에러(error)라고 하는 것은 통계적 분석에서 예측된 값과 실제 값의 차이를 의미하지만, 어떤 에러를 사용해야 한다는 명확한 원칙은 없다. 불확실성에 대한 시각화에 대하여 다음 자료를 읽어 보길 권한다.
geom_errorbar()는 x, ymin, ymax라는 aesthetic이 필요한 레이어이다. 따라서 이 조건을 맞추어야 한다.
에러 값으로 사용할 SEM(Standard Error of the mean)을 아래 공식에 따라 준비한다.
\[ SEM = \frac{s}{\sqrt{n}} \]
df <- mtcars |>
group_by(cyl) |>
summarise(
mean_mpg = mean(mpg, na.rm = TRUE),
se_mpg = sd(mpg, na.rm = TRUE) / sqrt(n())
)
df# A tibble: 3 × 3
cyl mean_mpg se_mpg
<dbl> <dbl> <dbl>
1 4 26.7 1.36
2 6 19.7 0.549
3 8 15.1 0.684이 데이터프레임을 막대 그래프를 만들고, geom_errorbar()를 사용하여 에러 바를 추가한다.
ggplot(df, aes(factor(cyl), mean_mpg)) +
geom_bar(stat = "identity", fill = "steelblue") +
geom_errorbar(
aes(ymin = mean_mpg - se_mpg, ymax = mean_mpg + se_mpg),
width = 0.5,
color = "darkgreen"
) +
labs(x = "Cylinders", y = "Miles per Gallon")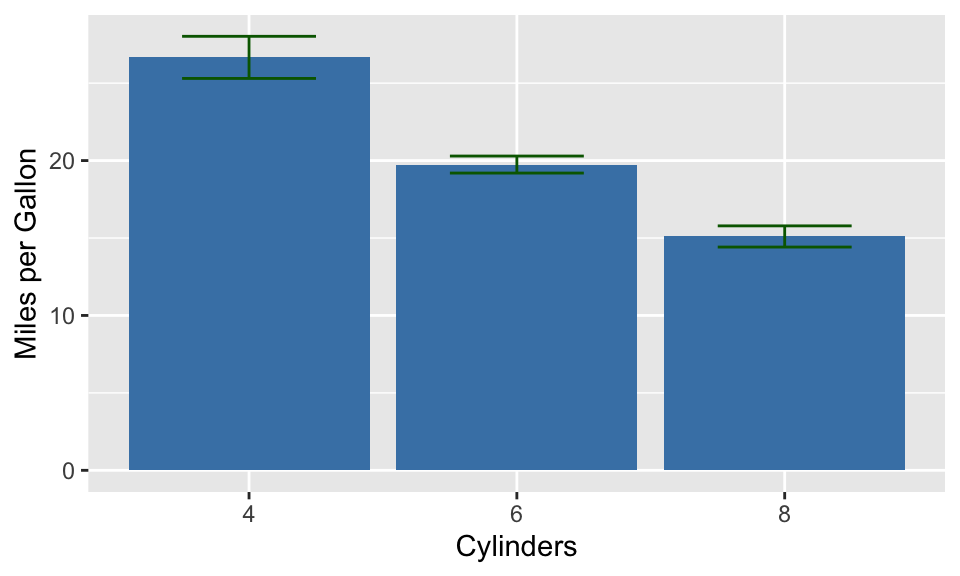
다음은 geom_linerange()를 사용한 경우이다.
ggplot(df, aes(factor(cyl), mean_mpg)) +
geom_bar(stat = "identity", fill = "steelblue") +
geom_linerange(
aes(ymin = mean_mpg - se_mpg, ymax = mean_mpg + se_mpg),
color = "darkgreen"
) +
labs(x = "Cylinders", y = "Miles per Gallon")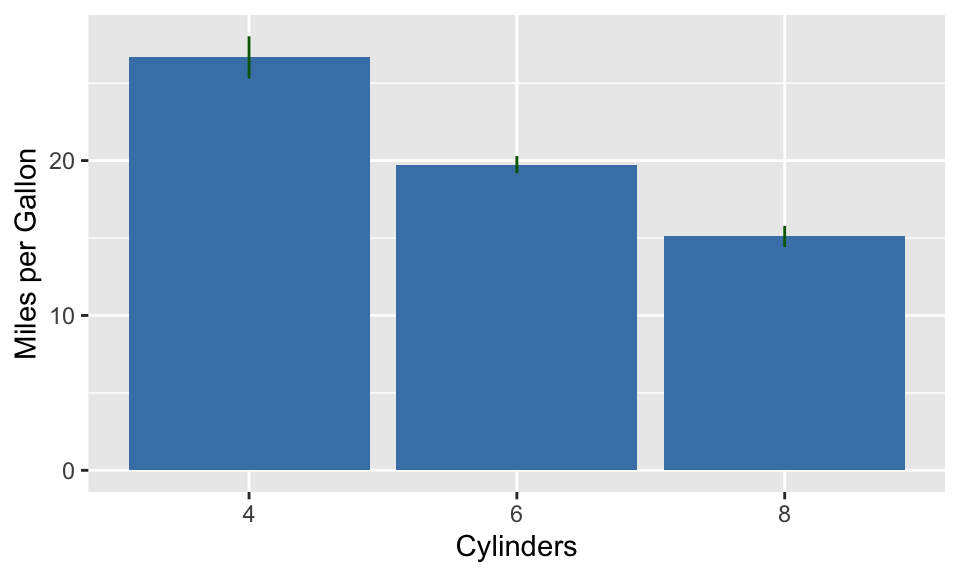
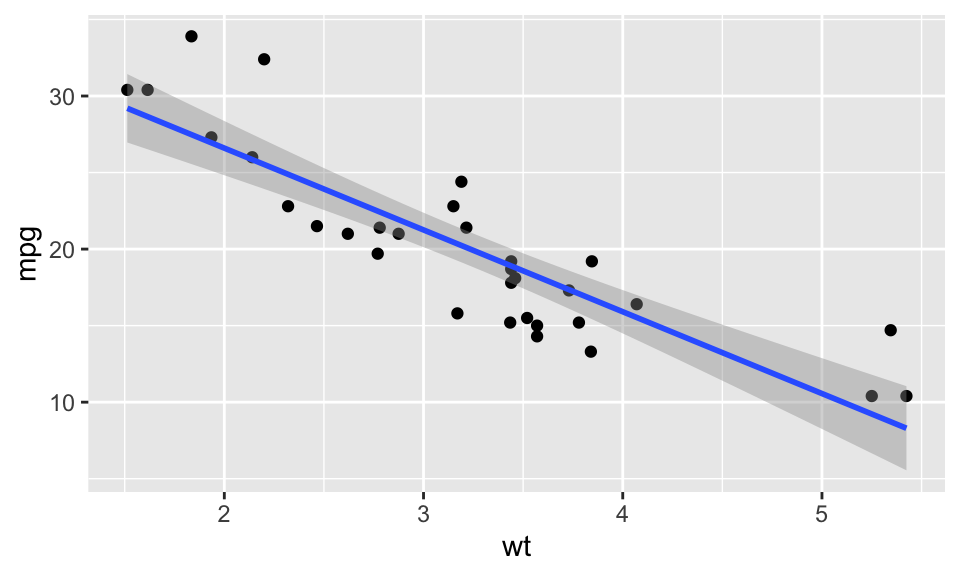
회귀 곡선을 그리는 경우에는 geom_smooth() 함수를 사용한다. 이 함수는 데이터가 1000개 미만인 경우에는 loess 방법을 사용하고, 1000개 이상인 경우에는 lm 방법을 사용한다. 95% 신뢰 구간을 표시하는데, 이것을 가리려면 se = FALSE를 지정한다.
ggplot(mtcars, aes(wt, mpg)) +
geom_point() +
geom_smooth(method = "lm")`geom_smooth()` using formula = 'y ~ x'