Rows: 5,110
Columns: 12
$ id <chr> "9046", "51676", "31112", "60182", "1665", "56669", …
$ gender <fct> Male, Female, Male, Female, Female, Male, Male, Fema…
$ age <dbl> 67, 61, 80, 49, 79, 81, 74, 69, 59, 78, 81, 61, 54, …
$ hypertension <fct> No, No, No, No, Yes, No, Yes, No, No, No, Yes, No, N…
$ heart_disease <fct> Yes, No, Yes, No, No, No, Yes, No, No, No, No, Yes, …
$ ever_married <fct> Yes, Yes, Yes, Yes, Yes, Yes, Yes, No, Yes, Yes, Yes…
$ work_type <fct> Private, Self-employed, Private, Private, Self-emplo…
$ residence_type <fct> Urban, Rural, Rural, Urban, Rural, Urban, Rural, Urb…
$ avg_glucose_level <dbl> 228.69, 202.21, 105.92, 171.23, 174.12, 186.21, 70.0…
$ bmi <dbl> 36.6, NA, 32.5, 34.4, 24.0, 29.0, 27.4, 22.8, NA, 24…
$ smoking_status <fct> formerly smoked, never smoked, never smoked, smokes,…
$ stroke <fct> Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes, Ye…35 명목 변수 분석의 시작: 분할표(contingency table)
이 장에서는 명목 변수(counting data)의 분석에서 가장 기본이 되는 분할표(contingency table)에 대해 알아본다. 분할표는 명목 변수의 기술 통계(descriptive statistics)의 기본이다.
분할표는 명목 변수가 취할 수 있는 값들에 대한 빈도(frequency)와 비율(proportion)을 계산하여 만든다. 빈도는 명목 변수의 각 범주(category)에 대해 관측된 횟수를 나타내고, 비율은 명목 변수의 각 범주에 대해 관측된 횟수를 전체 관측치의 수로 나눈 값을 나타낸다.
35.1 R 코드로 분할표 만들기
먼저 사용할 뇌졸중 데이터셋을 불러온다.
35.2 table()과 관련된 함수
명목 변수의 빈도와 비율을 계산하는 함수로 table()이 있다. table() 함수는 팩터 변수의 각 레벨(level)에 대해 관측된 횟수를 계산한다.
table(stroke_df$stroke)
No Yes
4861 249 table() 함수에 2개의 팩터 변수를 입력하면 두 변수의 모든 조합에 대한 빈도를 계산한다. table() 함수에 먼저 입력한 변수가 행으로 출력되고, 두 번째 변수가 열로 출력된다.
table(stroke_df$stroke, stroke_df$hypertension)
No Yes
No 4429 432
Yes 183 66이런 분할표에서 행/열에 대한 집계를 함께 계산하고 싶을 수 있다. 이런 경우에는 addmargins() 함수를 사용한다. 이 함수 안에 위에서 만든 분할표를 입력하면 행/열에 대한 집계를 함께 계산한다.
addmargins(table(stroke_df$stroke, stroke_df$hypertension))
No Yes Sum
No 4429 432 4861
Yes 183 66 249
Sum 4612 498 5110만약, 행들에 걸친 마진만 계산하고 싶다면 margin = 1을 사용하고(열 마진), 열들에 걸친 대한 마진만 계산하고 싶다면 margin = 2를 사용한다(행 마진).
addmargins(table(stroke_df$stroke, stroke_df$hypertension), margin = 1)
No Yes
No 4429 432
Yes 183 66
Sum 4612 498addmargins(table(stroke_df$stroke, stroke_df$hypertension), margin = 2)
No Yes Sum
No 4429 432 4861
Yes 183 66 249우리는 뇌졸중이 있는 환자군에서 고혈압 환자의 비율과 없는 환자군에서 고혈압 환자의 비율을 비교하고 싶다. 이런 경우에는 prop.table() 함수를 사용한다.
prop.table(table(stroke_df$stroke, stroke_df$hypertension), margin = 1)
No Yes
No 0.9111294 0.0888706
Yes 0.7349398 0.2650602만약, 고혈압이 있는 환자군에서의 뇌졸중이 있는 환자의 비율을 계산하고 싶다면 margin = 2를 사용한다.
prop.table(table(stroke_df$stroke, stroke_df$hypertension), margin = 2)
No Yes
No 0.9603209 0.8674699
Yes 0.0396791 0.1325301R xtabs() 함수도 분할표를 만든다. 이 함수에서는 R 포뮬러(formula)를 사용하여 분할표를 만든다.
xtabs(~ stroke + hypertension, stroke_df) hypertension
stroke No Yes
No 4429 432
Yes 183 663개 이상의 변수에 대한 분할표를 만들 때에는 xtabs() 함수를 사용할 수 있다.
tb <- xtabs(~ stroke + hypertension + smoking_status, stroke_df)
tb, , smoking_status = formerly smoked
hypertension
stroke No Yes
No 714 101
Yes 51 19
, , smoking_status = never smoked
hypertension
stroke No Yes
No 1602 200
Yes 58 32
, , smoking_status = smokes
hypertension
stroke No Yes
No 664 83
Yes 31 11
, , smoking_status = Unknown
hypertension
stroke No Yes
No 1449 48
Yes 43 4이런 고차원의 분할표를 좀 더 읽기 쉽게 만들고 싶다면 ftable() 함수를 사용한다. 여기서 f는 flatten을 의미한다.
ftable(tb) smoking_status formerly smoked never smoked smokes Unknown
stroke hypertension
No No 714 1602 664 1449
Yes 101 200 83 48
Yes No 51 58 31 43
Yes 19 32 11 4고차원 분할표를 데이터프레임으로 변환하고 싶다면 as.data.frame() 함수를 사용한다.
df_tbl <- as.data.frame(tb)
df_tbl stroke hypertension smoking_status Freq
1 No No formerly smoked 714
2 Yes No formerly smoked 51
3 No Yes formerly smoked 101
4 Yes Yes formerly smoked 19
5 No No never smoked 1602
6 Yes No never smoked 58
7 No Yes never smoked 200
8 Yes Yes never smoked 32
9 No No smokes 664
10 Yes No smokes 31
11 No Yes smokes 83
12 Yes Yes smokes 11
13 No No Unknown 1449
14 Yes No Unknown 43
15 No Yes Unknown 48
16 Yes Yes Unknown 4위 경우를 보면 팩터들의 조합에 따른 빈도를 계산하고 그 값을 Freq 변수에 저장하고 있다.
만약 이와 같은 데이터프레임을 가지고 시작할 때, 이것을 분할표로 변환하고 싶으면 xtabs() 함수를 사용하는데, 팩터의 조합에 따른 빈도 값을 포뮬러의 좌변에 둔다.
xtabs(Freq ~ stroke + hypertension + smoking_status, df_tbl), , smoking_status = formerly smoked
hypertension
stroke No Yes
No 714 101
Yes 51 19
, , smoking_status = never smoked
hypertension
stroke No Yes
No 1602 200
Yes 58 32
, , smoking_status = smokes
hypertension
stroke No Yes
No 664 83
Yes 31 11
, , smoking_status = Unknown
hypertension
stroke No Yes
No 1449 48
Yes 43 435.3 분할표를 그래프로 그리기
명목형 변수를 시각화하는 하는 대표적인 그래프는 막대 그래프(bar plot)이다. 이외에도 모자이크 그래프(mosaic plot)도 있고, 파이 차트(pie chart)도 있다.
tbl <- xtabs(~ stroke + hypertension, stroke_df)
tbl hypertension
stroke No Yes
No 4429 432
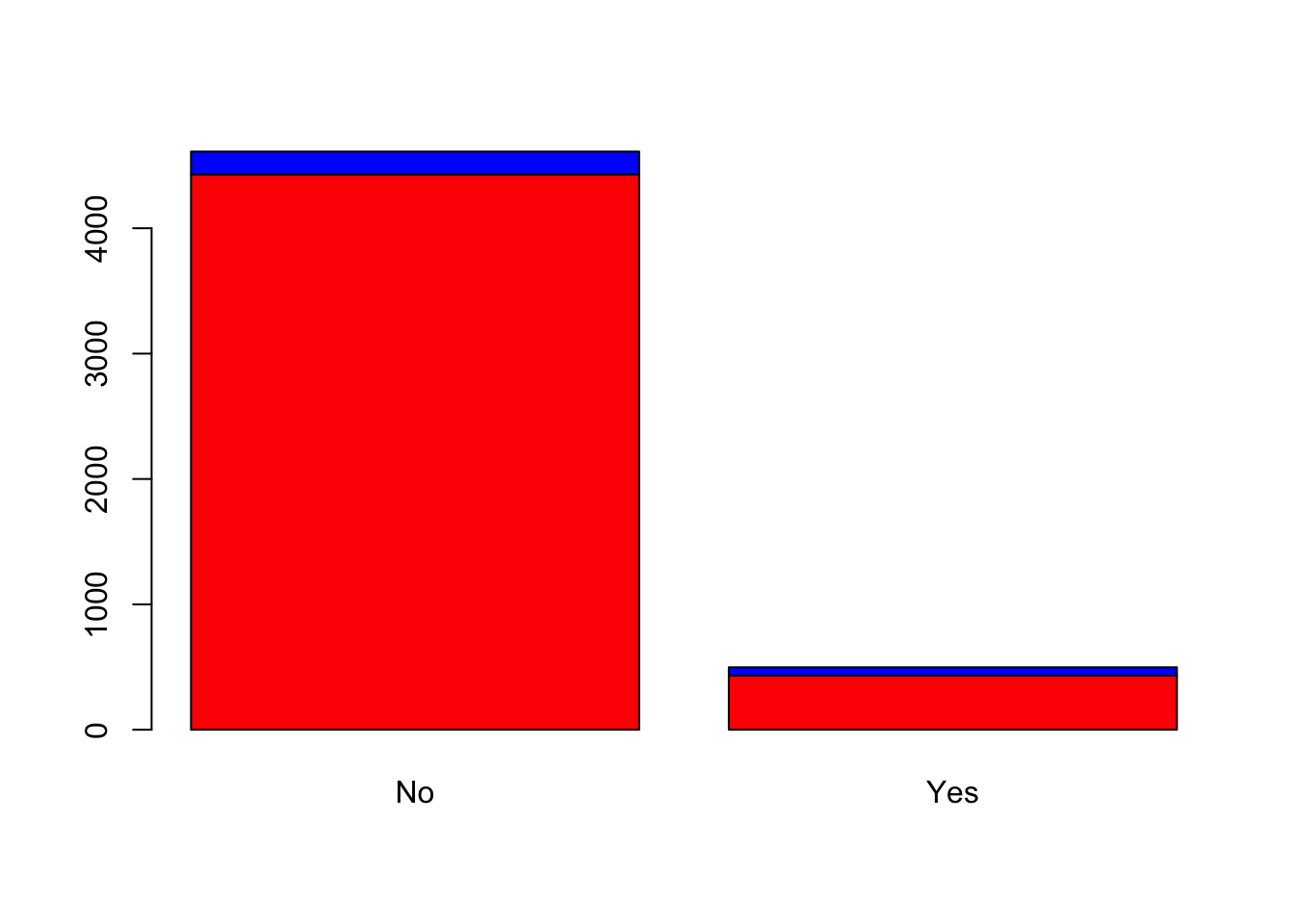
Yes 183 66베이스 R의 barplot() 함수를 사용하여 분할표를 그래프로 그릴 수 있다. 이 함수에는 분할표를 넣어서 사용한다.
ggplot2 패키지는 데이터프레임을 사용하기 때문에 이것을 데이터프레임으로 변환하여 사용한다.
df_tbl2 <- as.data.frame(tbl)
df_tbl2 stroke hypertension Freq
1 No No 4429
2 Yes No 183
3 No Yes 432
4 Yes Yes 66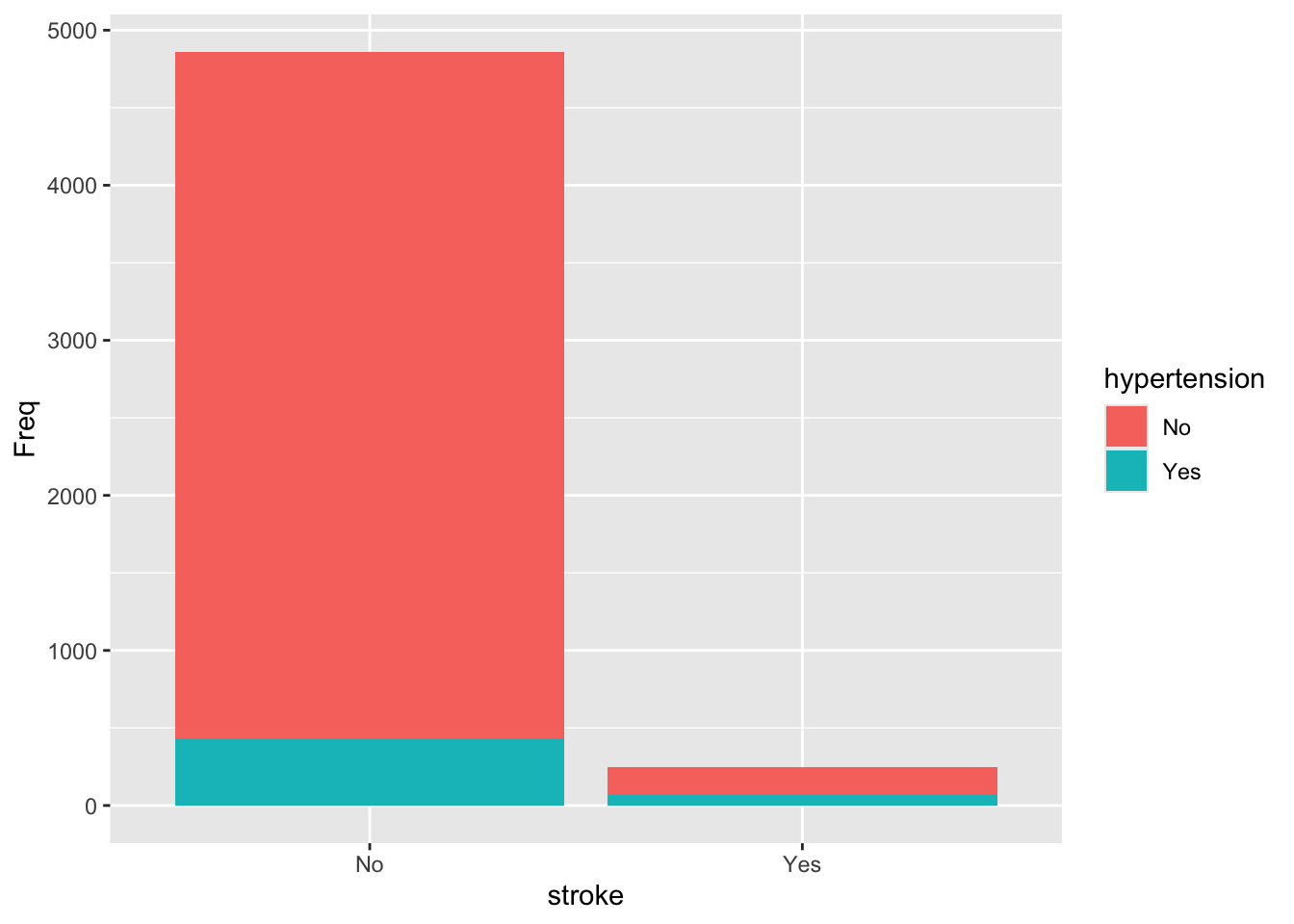
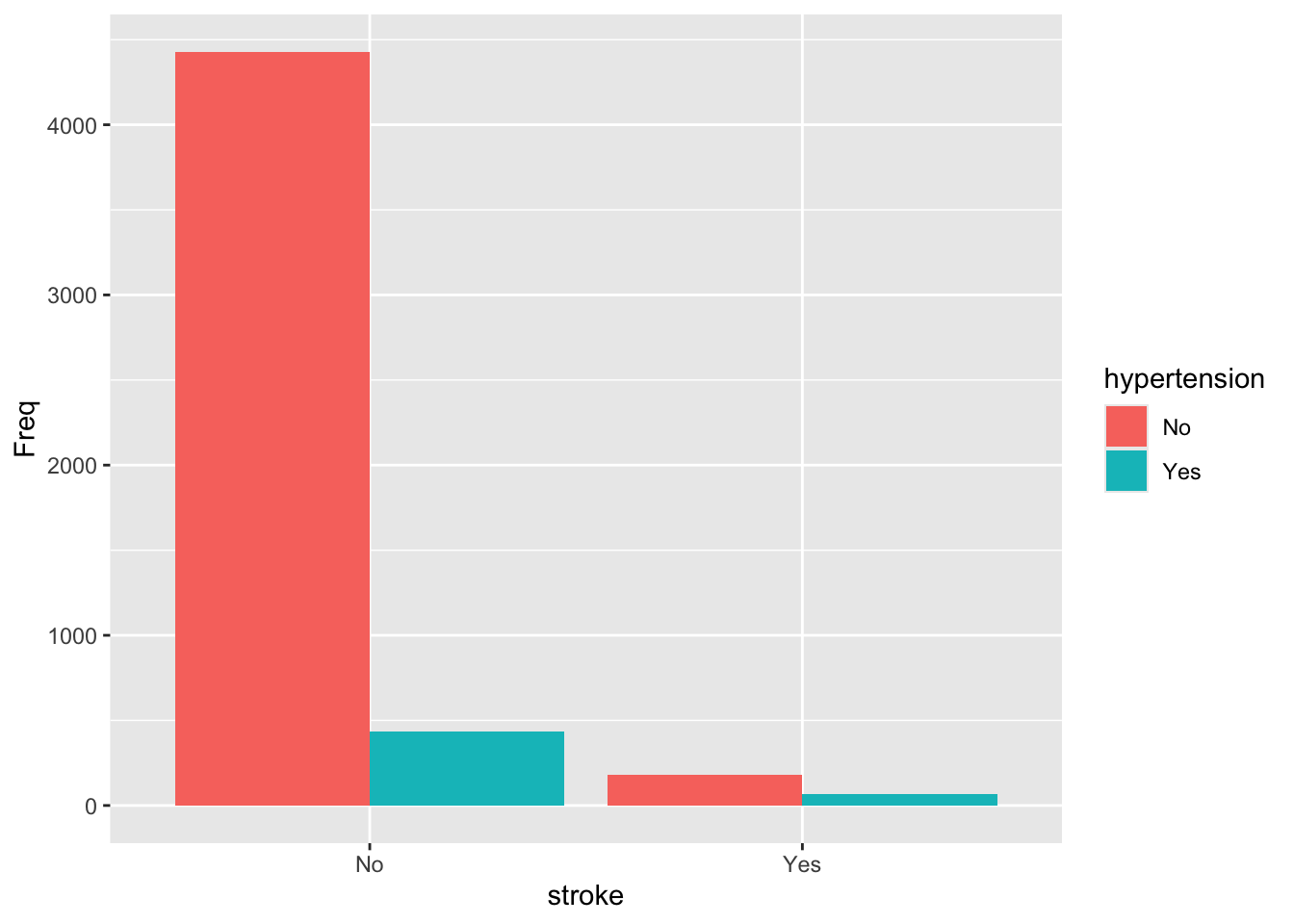
막대로 “stack” 형태가 아니라 분리하고 싶다면 geom_col() 함수에 position = "dodge" 옵션을 추가한다.
비율을 그래프로 그리고 싶다면 geom_col() 함수에 position = "fill" 옵션을 추가한다.
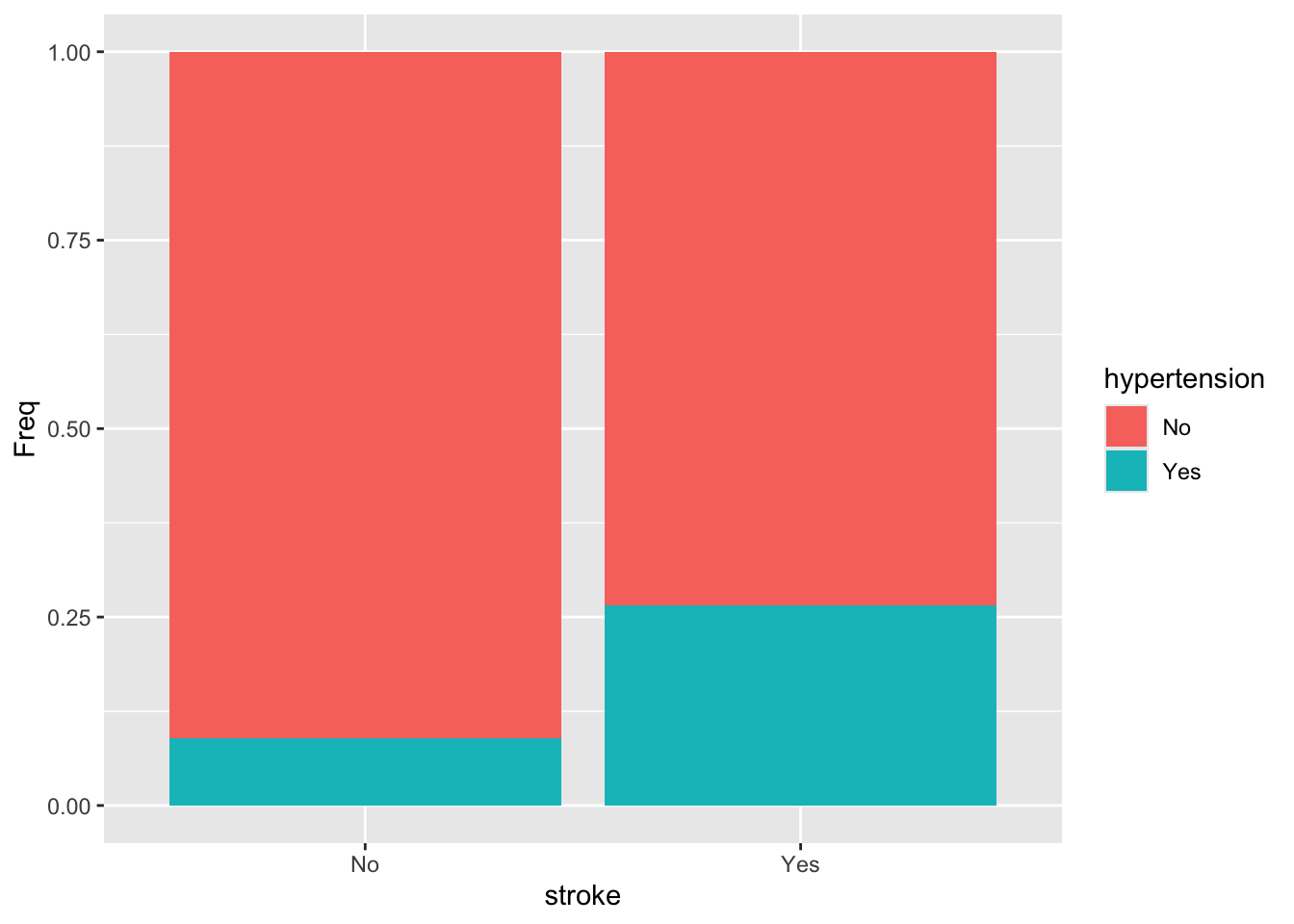
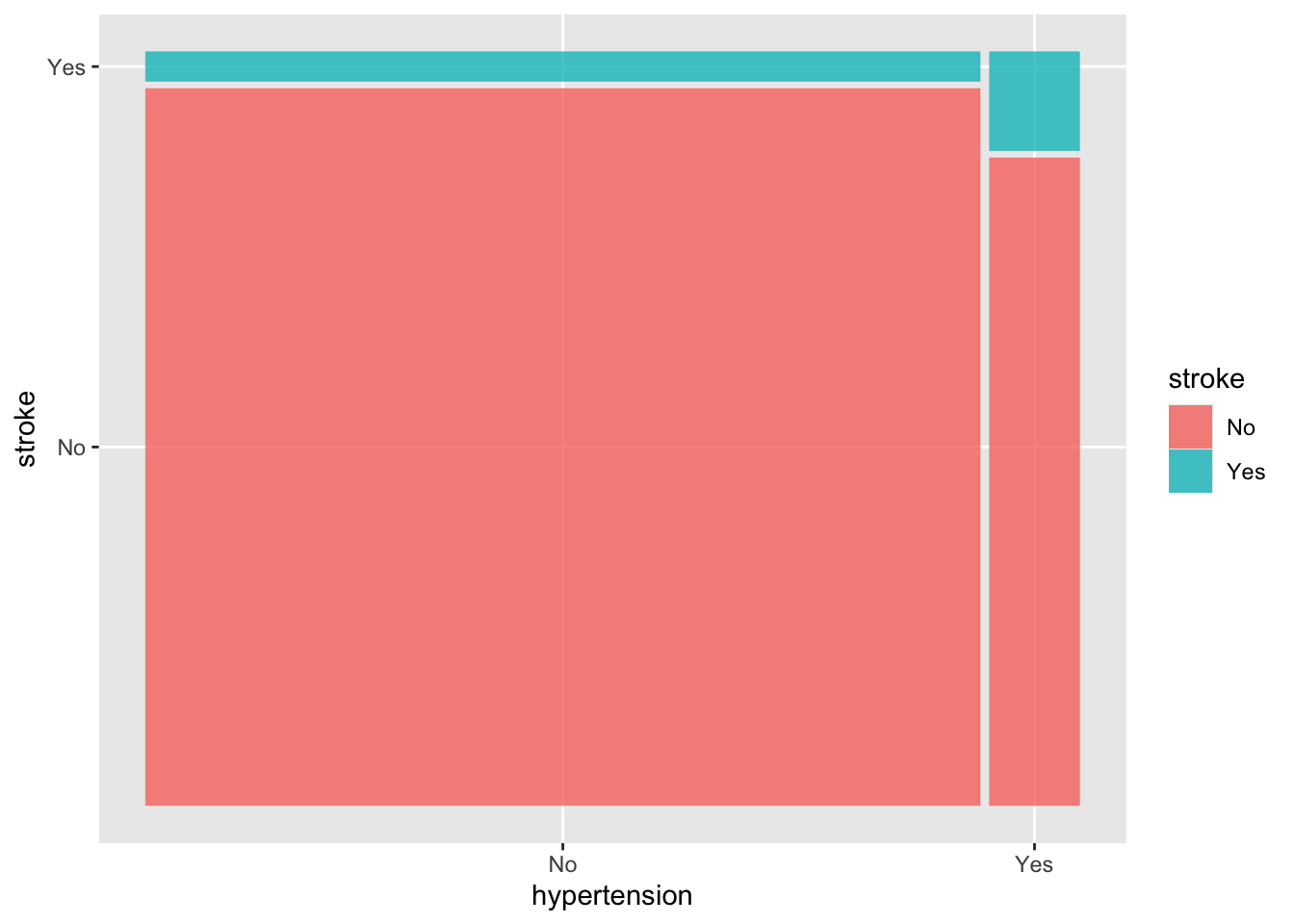
베이스 R의 mosaicplot() 함수를 사용하여 분할표를 그래프로 그릴 수 있다. 이 함수에는 분할표를 넣어서 사용한다.
mosaicplot(tbl)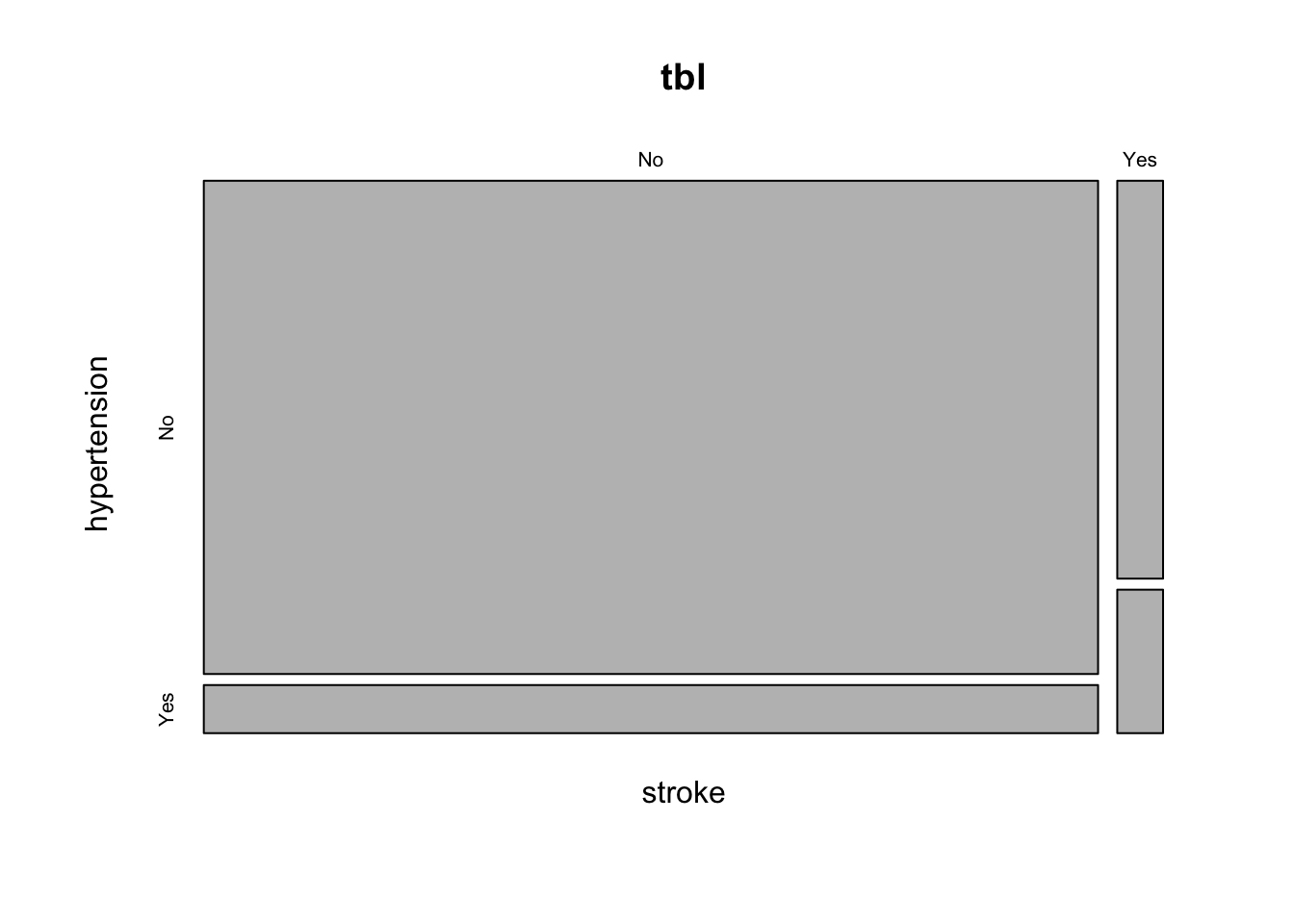
ggmosaic 패키지를 사용하여 분할표를 그래프로 그릴 수 있다. 이 패키지는 데이터프레임을 사용하기 때문에 원래의 데이터프레임을 가지고 시작한다.
library(ggmosaic)
ggplot(stroke_df) +
geom_mosaic(aes(x = product(stroke, hypertension), fill = stroke))