> 3 + 5[1] 8R을 설치하고 실행하면 그림 1.2과 같이 실행된다(실제는 안내문이 한글로 보일 것이다).
끝에 >을 볼 수 있다. 이것은 사용자의 명령을 기다린다는 뜻으로 “프롬프트(prompt)”라고 한다. 여기에 다음과 입력하여 엔터(Enter) 키를 치면 실행된다.
> 3 + 5[1] 8이와 같이 R은 기본적으로 사용자가 명령을 입력하면 R 해석기가 그것을 해석하고 실행한 다음 결과를 다시 출력해 주는 것을 반복하면서 실행된다. 이 과정을 Read-Evaluate-Print Loop라고 하고 REPL(레플)이라고 부른다. 또 이렇게 사용자가 R와 대화하듯이 작업하는 것을 대화형 모드(interactive mode)라고 부른다(나중에 R 명령들을 하나의 파일에 모아서 한꺼번에 실행시킬 수도 있는데 이것을 스크립트 모드(script mode)라고 한다).
출력에서 앞에 보이는 [1]은 첫 번째 위치라는 것을 의미하는데 일단 무시해도 된다.
그런데, R 콘솔만 사용하여 일하는 경우는 거의 없다. R 언어를 중심에 두고, 사용자를 위한 여러 편이 기능들을 갖춰 놓은 RStudio라는 프로그램을 사용하여 R을 사용하는 경우가 많다.
RStudio는 R 언어 사용의 편이를 제공하여 위해서 Posit.co라는 미국 회사가 개발하여 무료로(상용도 있지만) 배포하는 프로그램이다.
구글에서 “RStudio”라고 검색하여 “RStudio Desktop” 다운로드 사이트를 찾는다.
RStudio는 R 언어로 가지고 코드 작성, 패키지 제작, 각종 문서 만들기 등 다양한 일을 하는데 편리한 기능을 제공한다. 핵심은 코드를 작성하는 텍스트 에디터(text editor)이고 이외에도 아주 다앙한 기능을 제공한다. 이런 종류의 소프트웨어를 통합개발환경(integrated development environment)이라고 한다.
설치하고 RStudio를 실행하면, 왼도우인 경우 어떤 R을 사용할지 묻는 창이 보일 수도 있다.
64bit용 R을 사용한다고 선택하고 넘어가면 된다.RStudio를 실행하면 그림 1.4와 같이 실행된다.
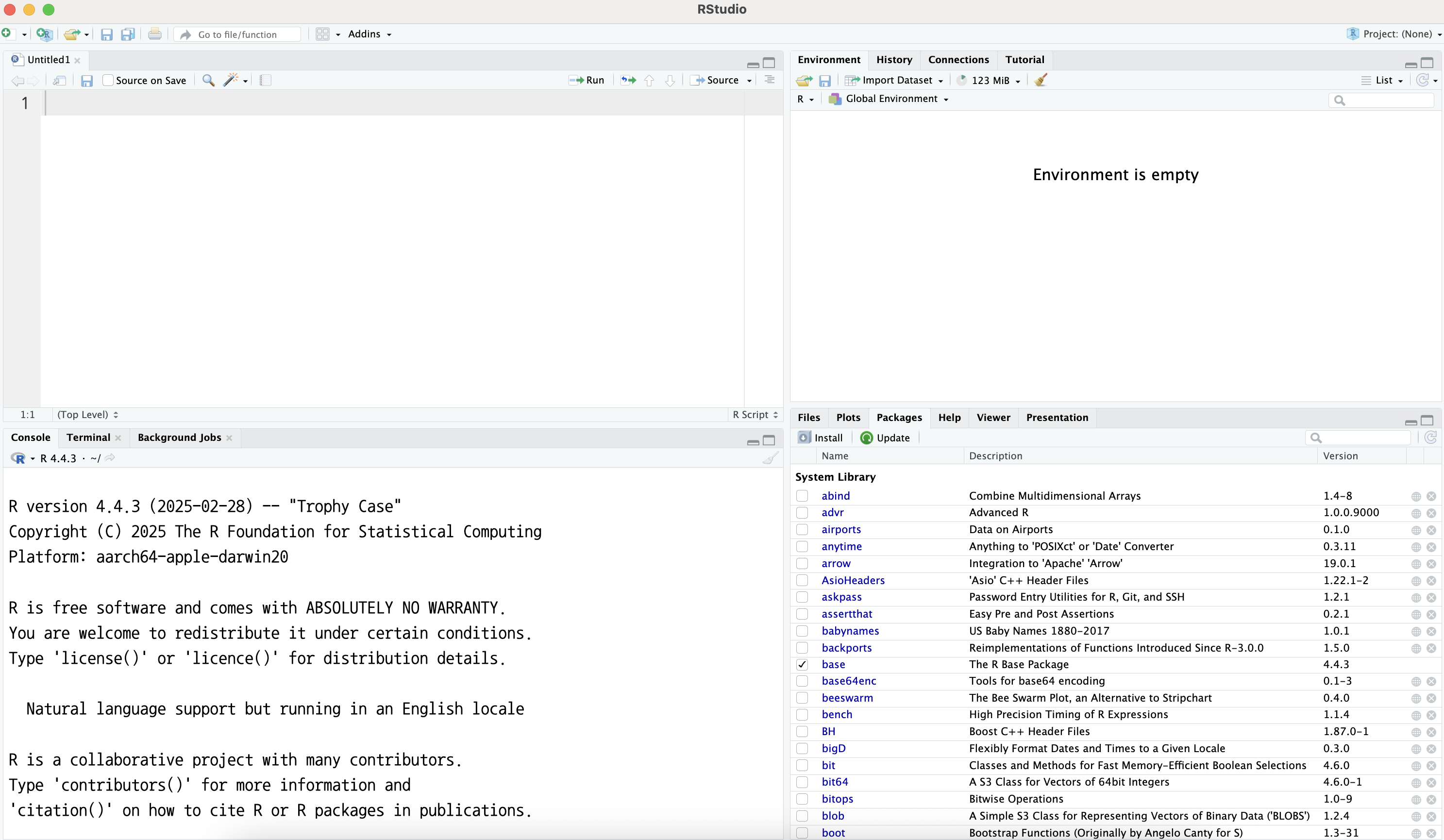
그림 1.4 같이 된 경우 - 왼쪽 아래가 앞에서 본 R 콘솔이다. - 왼쪽 위가 코드를 작성하는 텍스트 에디터이다. - 오른쪽에 현재 디렉터리의 파일을 관리하는 “Files”, 플롯을 보여주는 “Plots” 창, 패키지를 관리하는 “Packages” 창, 현재 R 환경에 있는 객체들을 보여주는 “Environment” 창 등이 있다.
R 콘솔에서 다음과 같이 코드를 입력하고 엔터(Enter) 키를 치면 실행해 보자. 이것은 표준 정규 분포(평균이 0이고 표준편차가 1인 정규분포)를 따르는 1000개의 난수 값을 생성한 다음, 그 값들의 분포를 히스토그램으로 만들어 본 예이다. 플롯은 “Plots” 창에서 보여준다.
> hist(rnorm(1000))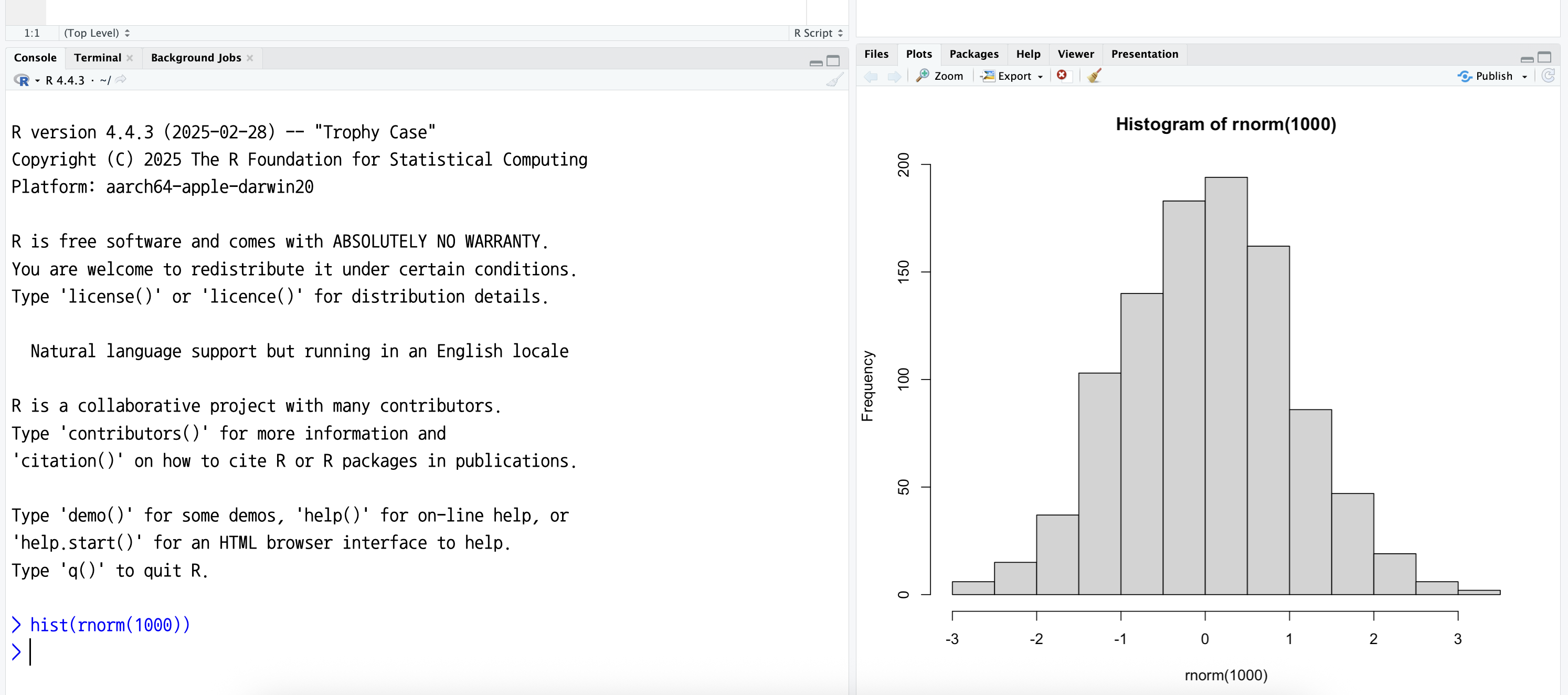
보통 우리가 데이터 분석이나 논문 작업을 할 때, 관련된 데이터 파일, 논문, 그림 등을 하나의 폴더에 모아서 관리하는 경우가 많다. 여기서 말하는 프로젝트란 이런 폴더를 의미한다. RStudio는 이런 폴더를 쉽게 관리할 수 있는 기능을 제공한다.
여기서 R 언어와 관련된 핵심 개념 하나를 알 필요가 있다. R이 실행되어 종료될 때까지를 R 세션이라고 한다. 또 R은 현재 실행된 디텍터리를 기준으로 어떤 일을 한다. 그러니까 실행된 디렉터리를 기준으로 엑셀에 있는 데이터를 읽을 수 있고, 이 실행된 디렉터리를 기준으로 데이터를 저장한다. 이처럼 R이 실행된 디렉터리로, 모든 일을 할 때 그 기준이 되는 디렉터리를 작업 디렉터리(working directory)라고 한다. getwd()라고 하면 현재 R 세션의 작업 디렉터리를 출력한다(보통 처음 시작할 때는 홈 디렉터리가 된다).
getwd()[1] "/Users/seokbumko/Learning/Education/cds-R"(물론 이런 개념을 이해하는 것이 중요할 수도 있지만…) RStudio 프로젝트 기능을 사용하면 굳이 이것에 신경쓰지 않아도 된다. 뒤에서 보면 알겠지만 RStudio가 자동으로 작업 디렉터리를 잡아 주기 때문이다.
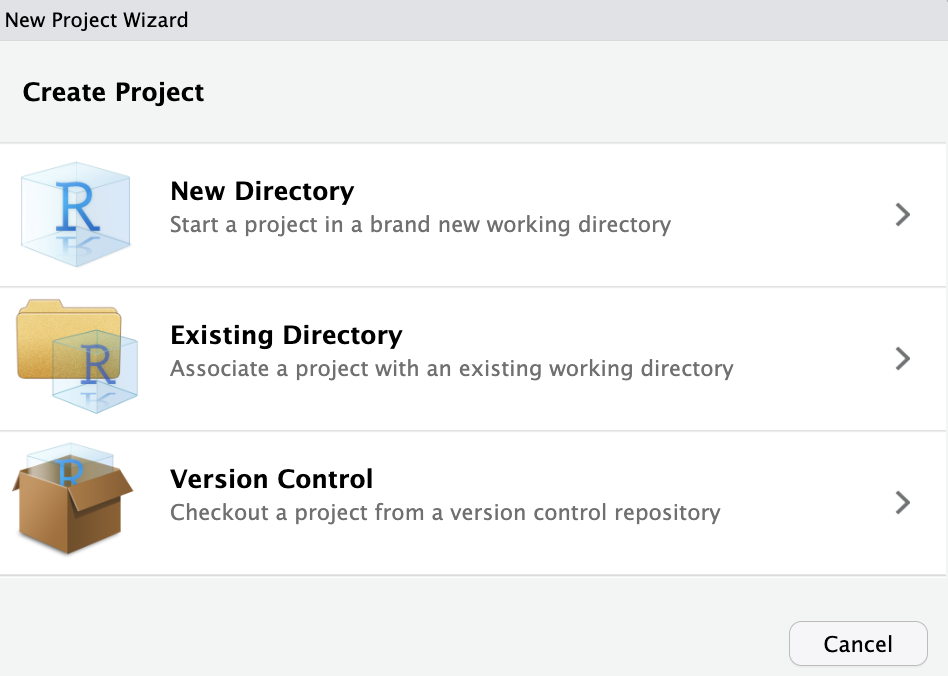
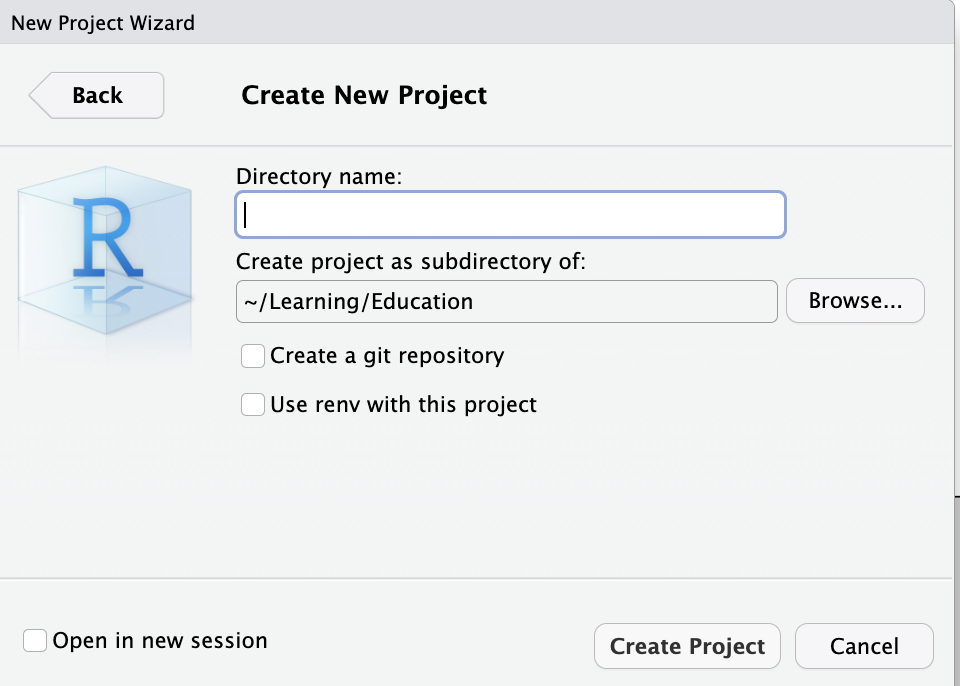
example이라는 프로젝트 이름을 줬기 때문에 해당 위치에 example이라는 폴더와 그 안에 example.Rproj라는 아이콘 파일이 만들어진다.![]()
** 이 아이콘 파일은 프로젝트를 대표하는 파일이다. 윈도우 탐색기에서 이것을 클릭하면, 이 파일이 있는 곳을 작업 디렉터리로 설정하면서 RStudio가 실행된다.
RStudio에서 특정 프로젝트는 여러 방법으로 열 수 있다.
윈도우 탐색기, 맥 파인더에서 폴더를 찾아서 앞에서 설명한 아이콘 파일을 클릭한다.
RStudio에서 오른쪽 위 Project 아이콘을 클릭하면 작업하던 디렉터리들이 보인다. 여기서 원하는 디렉터리를 클릭한다.
이 리스트에서 보이지 않는다면 여기서 “Open Project…”를 선택하여 앞에서 설명한 아이콘 파일을 클릭하면 된다.
컴퓨터에서 어떤 파일은 전체 파일시스템의 어떤 폴더 안에 존재한다. 윈도우나 맥이나 이런 파일시스템은 거꾸로 된 나무(tree) 모양으로 구성된다. 가장 상단에 뿌리(root)가 있고, 그 안에 여러 폴더가 있고, 그 폴더 안에 여러 폴더가 있는 식이다. 이런 시스템에서 파일의 위치를 해당 파일에 대한 경로(path)라고 한다.
폴더(folder)나 디렉터리(directory)는 같은 뜻을 가진 용어이다.
다음과 같이 폴더가 구성되어 있다고 해 보자. C: 폴더 안에 ABC, DEF라는 폴더가 있고, ABC 폴더 안에 Stroke, Peripheral, Dementia 등의 폴더가 있고, Stroke 폴더 안에 Embolic이라는 폴더가 있고 그 안에 embolic.data라는 폴더가 있는 구조이다.
- C:
- ABC
- Stroke
- Embolic
- raw-data
- embolic.data
- analysis.R
- Peripheral
- Dementia
- Movements
- Headache
- Epilepsy
- NeuroOpthalmo-Otology
- DEF
- Hello
- World이 경우 emolic.data를 루트(root) C:에서 시작하여 찾아가는 경로는 C:\ABC\Stroke\Embolic\raw-data\ embolic.data가 된다.
\를 사용하여 디렉터리를 구분한다.C:나 D:와 같은 여러 개의 루트 디레터리를 가진다./ABC/Stroke/Embolic/raw-data/embolic.data라고 사용한다.
/로 표시한다./로 구분한다.이와 같이 루트에서 시작하여 어떤 파일을 표기하는 경우를 절대 경로(absolute path)라고 한다
이 경우는 다르게 현재 작업 디렉터리를 기준으로 어떤 파일의 위치를 지목하는 것을 상대 경로(relative path)라고 한다. 상대 경로를 잘 사용하기 위해서는 윈도우/맥오에스 관계없이 다음 약어를 기억할 필요가 있다.
.: 현재 디렉터리..: 부모 디렉터리위에서 analysis.R이라는 코드에서 embolic.data를 어떻게 표시할지 생각해 보자. analysis.R 파일과 raw-data 폴더는 모두 Embolic 디렉터리에 동급으로 존재한다. analysis.R 입장에서 현재 디렉터리에 있는 raw-data 폴더를 찾고, 그 안에 embolic.data를 찾아가면 된다. 따라서 이 경우에는(맥오에스에서처럼 슬래쉬를 사용한다면) ./raw-data/embolic.data라고 써주면 되는 것이다.
R에서 경로를 잡을 때는 윈도우 방식 보다는 맥오에스 방식으로 잡는 것이 보편적이다. 왜냐하면 윈도우에서 쓰는 역슬래쉬를 문자열 안에서 쓰려면 이것이 다른 의미가 있는 역슬래쉬가 아닌 문자 그대로의 역슬래쉬를 표현해야 해서 역슬래쉬를 하나 더 써서 escaping을 해야 하기 때문이다.
프로젝트 안에서 자기가 원하는 방식대로 폴더 등을 구성해서 사용하면 된다. 다음과 같은 형태로 자신이 원하는 대로 하면 된다.
excel-data 폴더clean-data 폴더analysis-code 폴더results 폴더images 폴더 …excel-data 폴더에 mtcars.xlsx라는 데이터 파일이 있다고 가정해 보자. 이 파일을 읽고, 결과를 results 폴더에 저장하는 예이다.
아직 R 패키지에 대한 개념을 설명하지 않고, dplyr 패키지를 사용한 데이터 핸들링 등을 설명하지 않았다. 자세히 볼 것은 이 파일의 입장에서 읽어올 파일의 위치나 결과를 저장할 파일의 위치를 지정하는 방법이다.
궁금한 분들을 위해서 이 코드가 하는 일은 다음과 같다.
# 엑셀 파일을 읽어와서 df 데이터프레임에 할당
df <- read_excel("./excel-data/mtcars.xlsx")
head(df) # 처음 6개의 행을 보여준다.# A tibble: 6 × 11
mpg cyl disp hp drat wt qsec vs am gear carb
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 21 6 160 110 3.9 2.62 16.5 0 1 4 4
2 21 6 160 110 3.9 2.88 17.0 0 1 4 4
3 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
4 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1
5 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2
6 18.1 6 225 105 2.76 3.46 20.2 1 0 3 1# 각 열 이름 아래 <dbl> 등은 해당 열의 데이터 타입이다.# 표로 출력
knitr::kable(result)| cyl | n | mean_mpg |
|---|---|---|
| 4 | 11 | 26.66364 |
| 6 | 7 | 19.74286 |
| 8 | 14 | 15.10000 |
# 그 결과를 results 폴더에 rds 포맷으로 저장
saveRDS(result, file = "./results/cars-by-cyl.rds")