6 조건, 반복, 함수
이 장에서는 R 언어에서의 Control flow, 즉 조건부 실행과 반복 실행에 대해서 설명한다. 또 가끔 반복된 코드를 사용하는 경우 함수를 만들어 사용하는 것이 편리한 경우들이 있다. 그래서 사용자 정의 함수를 만들고 사용하는 방법에 대해서도 설명한다.
6.1 조건부 실행
R 언어는 벡터(vector)를 기본 데이터로 사용한다. 그리고 벡터화라는 방식을 통해서 작동하기 때문에 보통의 프로그래밍 언어와는 달리 이런 조건, 반복을 잘 사용하지는 않지만, 그래도 가끔 필요할 때가 있다.
6.1.1 if/else 문
if 문(statement)의 문법은 다음과 같다.
if (조건) 문장1
if (조건) 문장1 else 문장2첫 번째인 경우에는 조건이 TRUE인 경우에만 문장1이 실행된다. 두 번째인 경우에는 조건이 TRUE인 경우에는 문장1이 실행되고, 그렇지 않은 경우(조건 == FALSE)에는 문장2가 실행된다. 만약 여러 문장을 사용할 필요가 있는 경우에는 그것들을 문장1, 문장2를 {}로 감싸면 된다.
어떤 사람의 나이 데이터가 있을 때 이 값이 50 이상이면 50 이상이라고 출력하도록 만들어 보자.
위 경우에는 age >= 50이 TRUE이기 때문에 그 다음 print() 문이 실행되었다.
위 경우에는 age >=50이 FALSE이기 때문에 print() 문이 실행되지 않고 바로 다음 문장이 실행된다.
이번에는 50 이상이면 50 이상이라고 출력하고, 50 보다 작으면 50 미만이라고 출력해 보는 코드를 만들어 본다. age >= 50이 FALSE이기 때문에 첫 번째 print() 문을 실행되지 않고 나중 print() 문만 실행된다.
6.1.2 벡터화된 if: ifelse() 함수
R의 ifelse()라는 함수는 벡터화된 if라고 한다. 예를 들어 스코어가 70 이상이면 pass이고 70 미만이면 fail이라고 코딩해 보고 싶을 수 있다.
기본 문법은 다음과 같다.
ifelse(조건, 참일때값, 거짓일때값)다음과 같이 6명의 점수가 있다고 해 보자.
scores <- c(78, 67, 80, 90, 83, 59)이 값을 바탕으로 Pass, Fail로 된 새로운 벡터를 만들어 보자.
pass_fail <- ifelse(scores >=70, "Pass", "Fail")
pass_fail[1] "Pass" "Fail" "Pass" "Pass" "Pass" "Fail"위 코드는 다음과 같이 단계별로 생각해야 한다.
먼저 ifelse 함수의 첫 번째 인자가 scores >= 70이다.
scores >= 70[1] TRUE FALSE TRUE TRUE TRUE FALSE이렇게 만들어진 벡터를 가지고 ifelse() 함수가 TRUE인 위치에는 "Pass" 값으로, FALSE인 위치에는 "Fail" 값으로 대체한다.
ifelse() 함수는 조건에 따라 데이터를 2진(2개)로 나눌 때 편리하게 사용된다. 만약, 어떤 값에 따라 "mild", "moderate", "severe", "catastrophic"이라고 나누는 것처럼 3개 이상으로 그룹화할 필요가 있는 경우에는 dplyr 패키지의 case_when()을 고려한다. A general vectorised if-else를 참고한다.
6.2 반복
6.2.1 for 문: 정해진 개수만큼 반복 실행
for 문을 사용하면 정해진 개수만큼 코드를 반복한다. 기본 문법은 다음과 같다.
for (v in 데이터) {
문장들
}이 문장은 데이터에 포함된 값들을 하나씩 꺼내서 v(이름은 마음대로 정할 수 있음)에 할당하고 그것을 가지고 문자들을 가지고 어떤 일을 할 수 있게 한다. 첫 번째 값을 가지고 와서 일을 하고, 그 다음은 두 번째 값을 가지고 와서 일을 하고, 그 다음은 세 번째 값을 가지고 와서 일을 한다. 쭉 이어진다.
다음은 아주 간단한 예로, 값들을 하나씩 꺼내서 출력한다.
다음은 좋은 코드는 아닌데, for문 이해를 돕기 위해 사용한다. 1에서 10까지 값을 제곱하여 새로운 벡터를 만드는 것이다. vector() 함수는 빈 벡터를 만든다. for 문 안에서 result <- c(result, i^2) 코드를 통해서 이 벡터에 값들이 추가된다.
[1] 1 4 9 16 25 36 49 64 81 100사실 위와 같이 하면 코드의 효율성이 떨어지고, 무엇보다 코드를 다른 사람들이 보았을 때 무엇을 하려고 하는지 이해하는 것이 쉽지 않다. 가독성이 떨어진다. R 언어는 벡터화(vectorization)를 기본으로 사용하기 때문에 다음과 같이 x^2 코드를 통해 벡터 x의 각 요소의 값을 제곱하라는 의도를 쉽게 전달하고 실행한다. 그래서 R 언어에서는 for 문이 필요한 경우 이와 같은 방식으로 가능한지 한번 더 생각하는 것이 권장된다.
x <- 1:10
x
## [1] 1 2 3 4 5 6 7 8 9 10
y <- x^2
y
## [1] 1 4 9 16 25 36 49 64 81 1006.2.2 더 자세한 내용
6.3 사용자 정의 함수
R에서 사용자 정의 함수를 만드는 방법은 다음과 같다.
func_name <- function(인자1, 인자2) {
문장들
}function() 이라는 키워드 안에 사용할 파라미터를 정하고, {} 블록안에서 그 값들을 사용할 코드를 작성하면 된다. R 함수는 맨 마지막 표현식이 그 함수의 호출값이 된다. 함수 호출(실행시킨다고도 한다)은 이름 끝에 ()를 쓰고, 그 안에서 파라미터에 대응하는 값을 주면 된다. 이것을 func_name이라는 변수(이름은 사용자 마음대로 정한다)에 할당하면 func_name이 이 함수의 이름이 된다.
그래서 다음 함수는 x, y라는 파라미터를 가지고 있고, 마지막 표현식이 x + y여서 이 값이 함수를 호출했을 때이 반환하는 값(return value, 결과값)이 된다.
my_sum <- function(x, y) {
x + y
}
my_sum(1, 5)[1] 6Python 언어도 마찬가지이지만 R 언어에서 어떤 함수는 (1) 값을 반환하거나 (2) 부수효과(side effect)를 낼 수 있다. 어떤 경우에는 2가지 모두 하는 경우도 있다. 부수 효과는 실행되는 함수를 기준으로 그 외부에 영향을 주는 것을 말한다. 출력, 데이터베이스 기록, 플롯팅 등을 말한다. 값은 그야말로 값이다. 함수는 하나의 값만을 반환할 수 있다. 만약 여러 개의 값을 반환할 필요가 있는 경우에는 이것들을 하나로 묶어서 하나의 벡터로 반환시키면 된다. 벡터는 하나의 값이기 때문이다.
값을 반환하고 또 부수효과를 내는 함수 가운데 하나가 base R의 히스토그램을 만들어 주는 hist()이다.
다음 예를 보자.
id gender age hypertension heart_disease ever_married work_type
1 9046 Male 67 No Yes Yes Private
2 51676 Female 61 No No Yes Self-employed
3 31112 Male 80 No Yes Yes Private
4 60182 Female 49 No No Yes Private
5 1665 Female 79 Yes No Yes Self-employed
6 56669 Male 81 No No Yes Private
residence_type avg_glucose_level bmi smoking_status stroke
1 Urban 228.69 36.6 formerly smoked Yes
2 Rural 202.21 NA never smoked Yes
3 Rural 105.92 32.5 never smoked Yes
4 Urban 171.23 34.4 smokes Yes
5 Rural 174.12 24.0 never smoked Yes
6 Urban 186.21 29.0 formerly smoked Yes# 히스토그램 만들기
hist(stroke_df$age[stroke_df$stroke == "Yes"],
main = "Patient Age Distribution(with Stroke)",
xlab = "Age",
ylab = "Frequency",
col = "lightblue",
border = "black")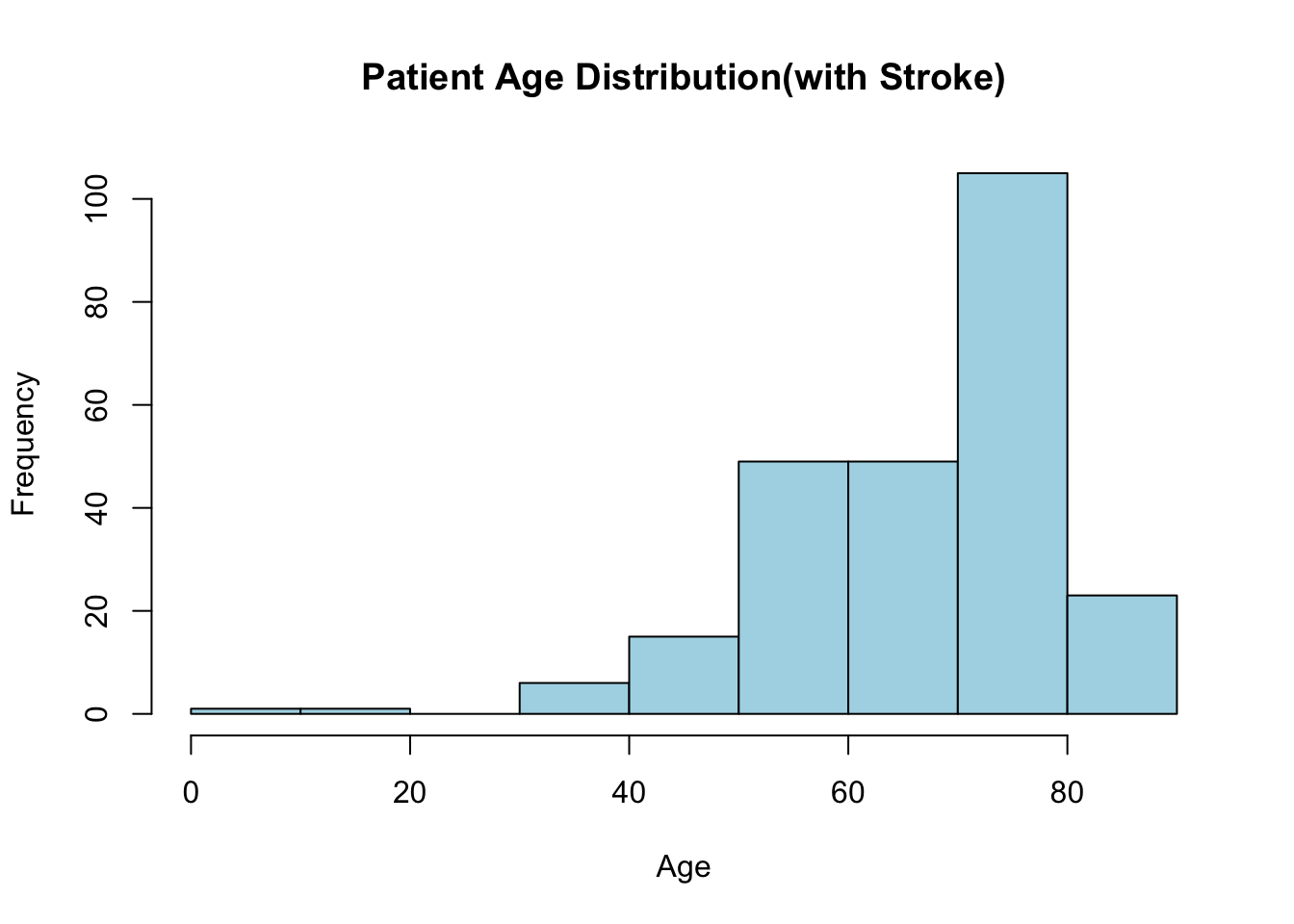
위와 같이 해서 히스토그램을 만들 수 있는데, 실은 이렇게 하는 것은 hist() 함수가 반환하는 값들을 무시하는 셈이다. hist() 함수는 빈(bin)을 정하고 그 빈에 속하는 값들의 개수를 막대의 높이로 표시한 것이다. 이런 정보들이 함수를 값을 받아서 보면 알 수 있게 되어 있다.
hist_info <- hist(stroke_df$age[stroke_df$stroke == "Yes"],
main = "Patient Age Distribution(with Stroke)",
xlab = "Age",
ylab = "Frequency",
col = "lightblue",
border = "black")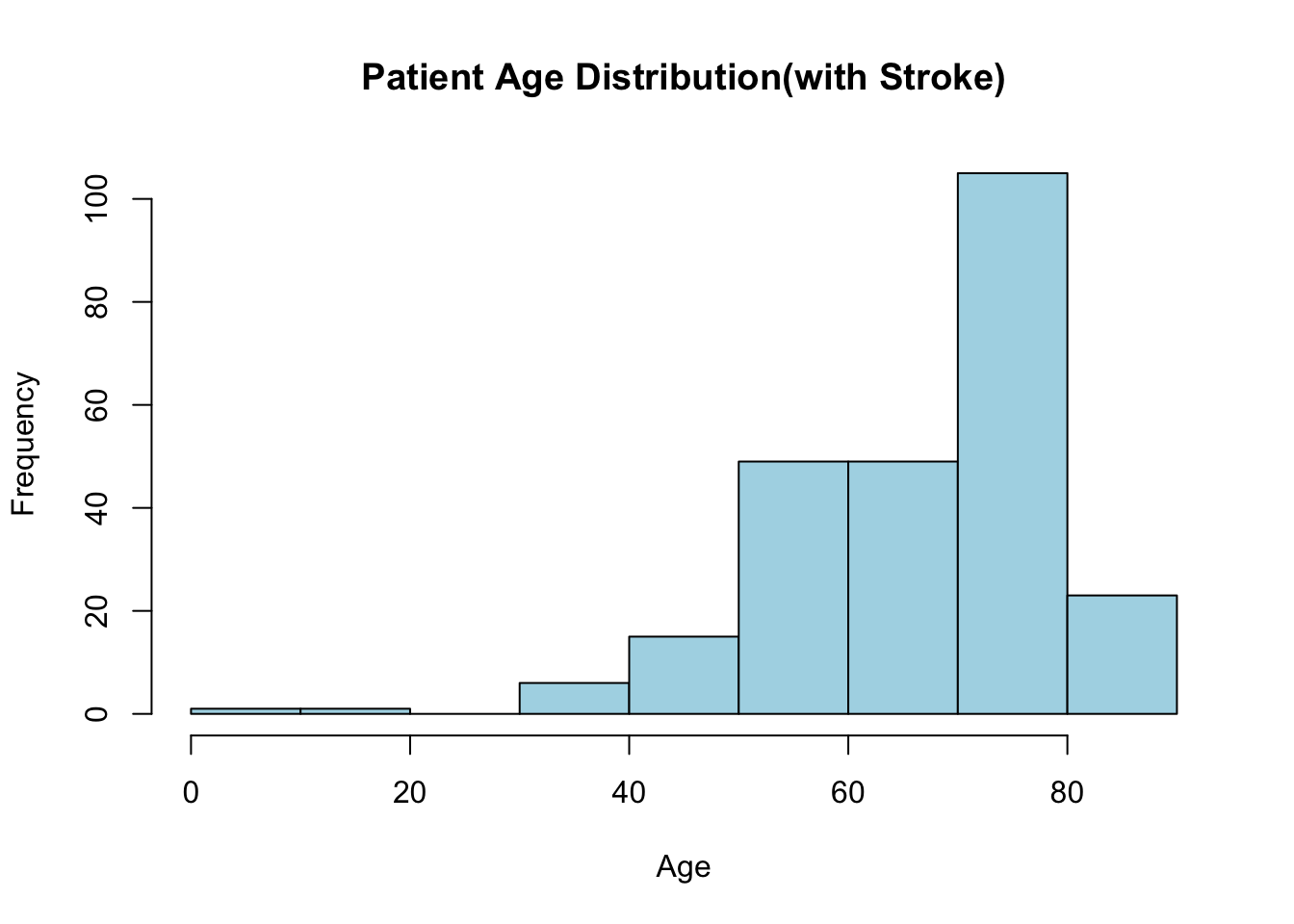
hist_info$breaks
[1] 0 10 20 30 40 50 60 70 80 90
$counts
[1] 1 1 0 6 15 49 49 105 23
$density
[1] 0.0004016064 0.0004016064 0.0000000000 0.0024096386 0.0060240964
[6] 0.0196787149 0.0196787149 0.0421686747 0.0092369478
$mids
[1] 5 15 25 35 45 55 65 75 85
$xname
[1] "stroke_df$age[stroke_df$stroke == \"Yes\"]"
$equidist
[1] TRUE
attr(,"class")
[1] "histogram"? 여기서 counts라는 속성을 꺼내서 다시 사용할 수 있다.
hist_info$counts[1] 1 1 0 6 15 49 49 105 236.3.1 함수형 언어의 특징을 이해하면
R 언어에서는 함수가 하나의 데이터로 취급된다. 변수에 저장할 수도 있고, 리스트나 다른 벡터로 저장할 수도 있고, 함수 안에서 다른 함수를 반환할 수도 있다. 이런 특징들을 처음부터 이해할 수도 없다고 하더라도 이해하면 할수록 복잡한 코드를 더욱 간결하게 만들 수 있다.
아주 간단한 예로 lappy()(결과를 리스트로), sapply()(결과를 가급적 간단하게) 함수를 사용법을 소개한다.
lapply(함수를적용할리스트, 함수이름, 이함수가필요한인자들)
sapply(함수를적용할리스트, 함수이름, 이함수가필요한인자들)예를 들어 다음과 같은 데이터프레임이 있을 때, 이 데이터프레임을 구성하는 벡터들의 데이터 타입을 한꺼번에 계산할 수 있다.
sapply(stroke_df, typeof) id gender age hypertension
"character" "integer" "double" "integer"
heart_disease ever_married work_type residence_type
"integer" "integer" "integer" "integer"
avg_glucose_level bmi smoking_status stroke
"double" "double" "integer" "integer" 이런 함수를 결합하여 사용자 정의 함수를 하나 만들어 기술 통계를 한꺼번에 출력하게 할 수도 있다.
# 양적인 변수
q_vars <- c("age", "avg_glucose_level", "bmi")
stats <- function(x, na.omit=FALSE) {
if (na.omit)
x <- x[!is.na(x)]
m <- mean(x)
n <- length(x)
s <- sd(x)
skew <- sum( (x-m)^3/s^3) / n
kurt <- sum((x-m)^4/s^4)/n - 3
return(c(n=n, mean=m, stdev=s, skew=skew, kurtosis=kurt))
}
# 양적인 변수를 골라서, `stats`라는 함수를 적용한다.
sapply(stroke_df[q_vars], stats, na.omit=TRUE) age avg_glucose_level bmi
n 5110.0000000 5110.000000 4909.000000
mean 43.2266145 106.147677 28.893237
stdev 22.6126467 45.283560 7.854067
skew -0.1369789 1.571361 1.054695
kurtosis -0.9920009 1.675830 3.355423이런 식으로 프로그래밍하는 것을 함수형 프로그래밍이라고 한다. purrr 패키지는 R 함수형 프로그래밍을 지원하는 훌륭한 패키지이다.
6.3.2 더 자세한 내용
Advanced R 책에 함수형 프로그래밍에 대한 설명이 자세히 되어 있다.
R for Data Science(25장)에 실제 용도에 맞는 함수를 어떻게 정의하는지 등에 관해 자세히 설명한다.