gender <- c("female", "female", "female")23 팩터의 레벨에 따른 순서 조정(forcats 패키지를 중심으로)
5 장에서도 간단히 설명했지만, R에서는 팩터(factor)는 보통 범주형(categorical) 변수를 표현하는 특수한 종류의 벡터이다. 이런 팩터는 통계 분석에서 아주 중요한 역할을 한다.
ggplot2를 사용하여 그래프를 만들 때 가장 흔히 부딪히는 문제 중 하나는 팩터형(factor) 변수의 순서를 정하는 것이다. ggplot2에서는 팩터형(factor) 변수에 대한 지옴을 배치하는 순서는 팩터의 레벨(level)에 의해 결정되는 데 가끔 이것을 수정하고 싶을 때가 생긴다.
이 장에서는 팩터에 대하여 더 자세히 알아보고, 팩터를 다루는 데 아주 큰 도움을 주는 forcats 패키지를 설명하고, ggplot2에서 어떻게 또 활용되어 우리가 원하는 그래프를 얻을 수 있는지 설명한다.
23.1 팩터
팩터는 벡터의 한 종류로, 벡터의 각 요소가 취할 수 있는 값이 제한되어 있는 경우에 사용한다. 문자열
23.1.1 문자열 벡터와 팩터가 다른 점
예를 들어, 성별이라는 정보를 다음과 같이 정리했다. 모두 "female"이다.
달(month)이라는 정보를 다음과 같이 정리했다.
months <- c("Jan", "Feb", "Feb", "Jan", "Mar", "Mar", "Mar", "Aug", "Sep", "Oct", "Apr", "Dec")위 두 벡터는 아직 문자열 벡터이지 팩터가 아니다. 그래서 이것을 팩터가 바꾸지 않은 채로 분석하면 여러 가지 문제가 생길 수 있다. (Contigency) table을 만들면 다음과 같다.
정렬을 해 보자.
sort(gender)[1] "female" "female" "female"sort(months) [1] "Apr" "Aug" "Dec" "Feb" "Feb" "Jan" "Jan" "Mar" "Mar" "Mar" "Oct" "Sep"months 벡터를 가지고 막대그래프를 만들어 보자.
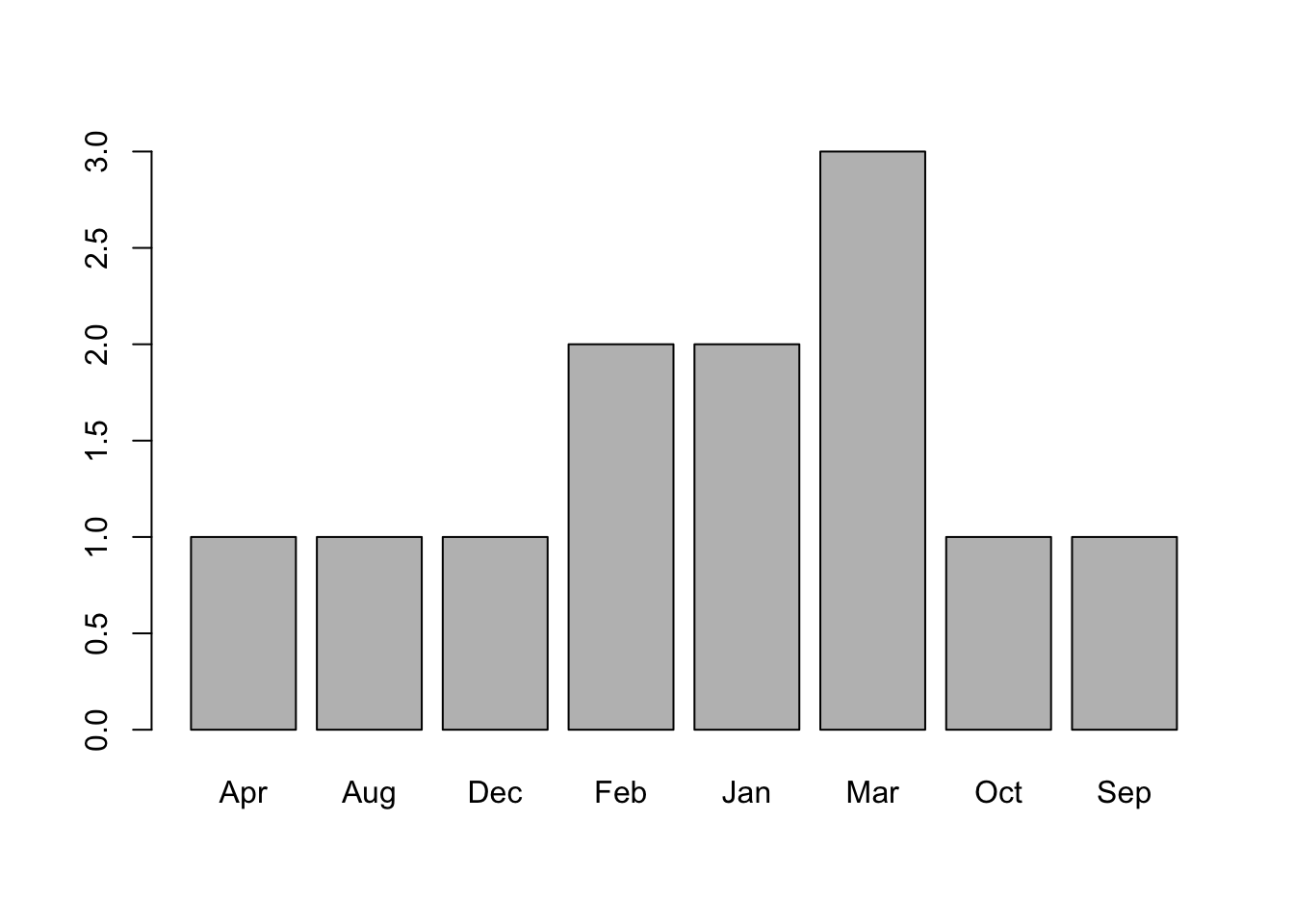
table() 함수, sort() 함수, barplot() 함수 실행 결과를 보면 알파벳 순서대로 출력되는 것을 확인할 수 있다.
팩터는 각 요소가 취할 수 있는 값이 제한되어 있는 경우를 표현한다고 했다. 이 말을 성별 데이터를 모은 벡터에는 "male"과 "female"만 존재한다(제3의 성을 무시하면). 달 데이터는 “Jan”, “Feb”, “Mar”, “Apr”, “May”, “Jun”, “Jul”, “Aug”, “Sep”, “Oct”, “Nov”, “Dec” 중 하나만 존재할 것이다. 이것을 팩터의 레벨(levels)이라고 한다.
실제로 팩터는 각 레벨에 대하여 번호를 붙이고 내부에서 이 번호를 사용하여 데이터를 저장한다. 그래서 원래 문자열을 저장하는 것보다 메모리를 적게 사용한다. 그래서 “male”과 “female”을 레벨로 가지는 팩터는 “male”들은 1이고 “female”들은 2로 저장되고, 달을 레벨로 가지는 팩터는 “Jan”들은 1이고 “Feb”들은 2 등으로 저장한다.
그리고 팩터를 출력했을 때는 숫자가 아니라 문자열로 출력된다. 이것은 팩터의 레이블(labels)이라고 한다.
문자열을 팩터로 변환하는 factor() 함수를 사용하여 레벨과 레이블을 지정할 수 있다. 그렇지만 factor() 함수를 디폴트 옵션으로 그대로 사용했을 때 그냥 원하는 팩터가 되는 것은 아니다.
mfactor <- factor(months)
mfactor [1] Jan Feb Feb Jan Mar Mar Mar Aug Sep Oct Apr Dec
Levels: Apr Aug Dec Feb Jan Mar Oct Sep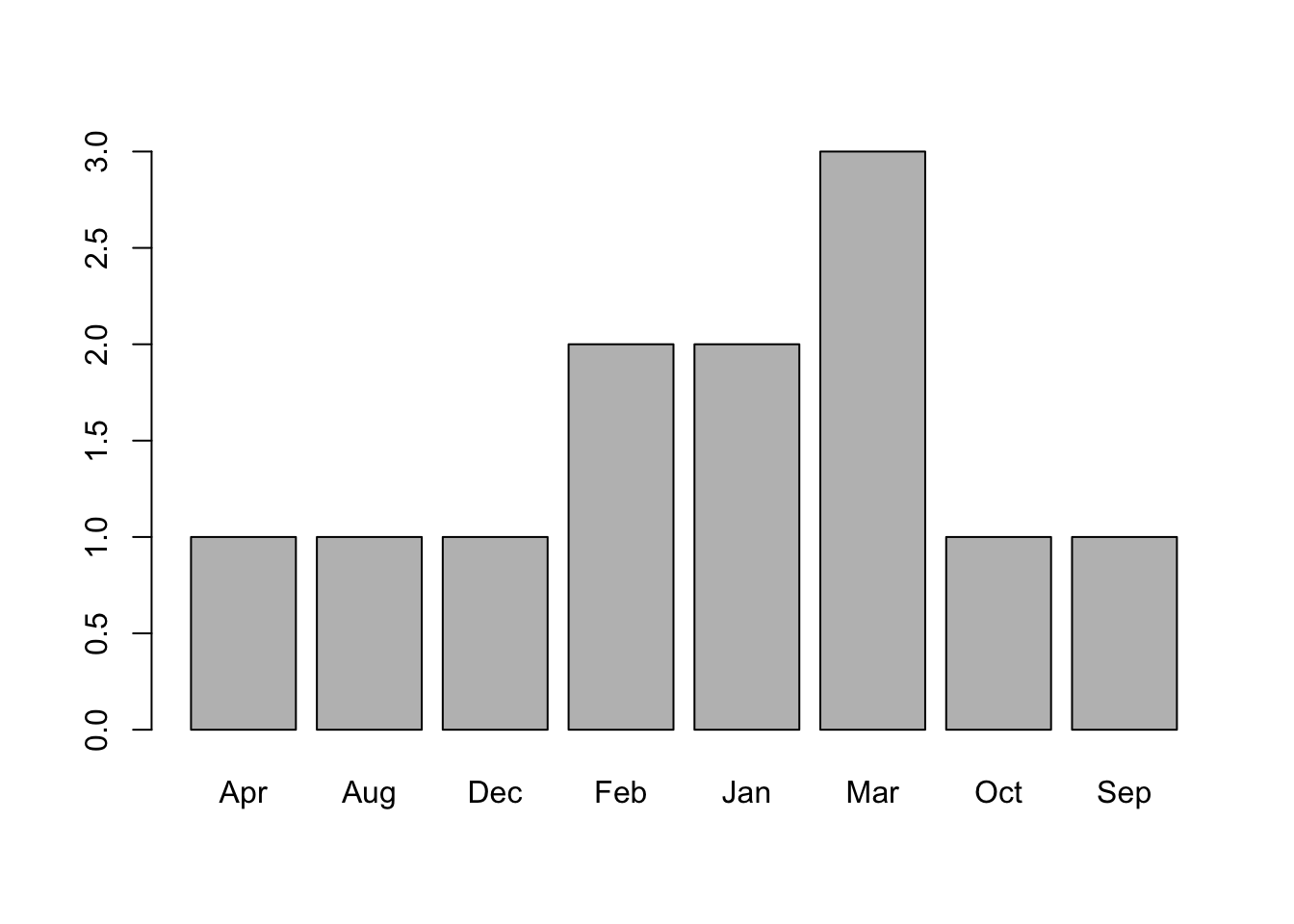
위 결과를 보면 레벨이 생성되기는 하지만, 레벨의 문자열 알파벳 순서대로 따라가는 것을 볼 수 있다. 이 문제를 해결하려면 추가 타이핑을 하는 수고가 필요하다.
gender_factor <- factor(gender,
levels = c("male", "female"),
labels = c("남자", "여자")
)
gender_factor[1] 여자 여자 여자
Levels: 남자 여자months_factor <- factor(months,
levels = c("Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"),
labels = c("Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec")
)
months_factor [1] Jan Feb Feb Jan Mar Mar Mar Aug Sep Oct Apr Dec
Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec이렇게 만들어진 months_factor를 사용하여 막대그래프를 만들면 다음과 같다.
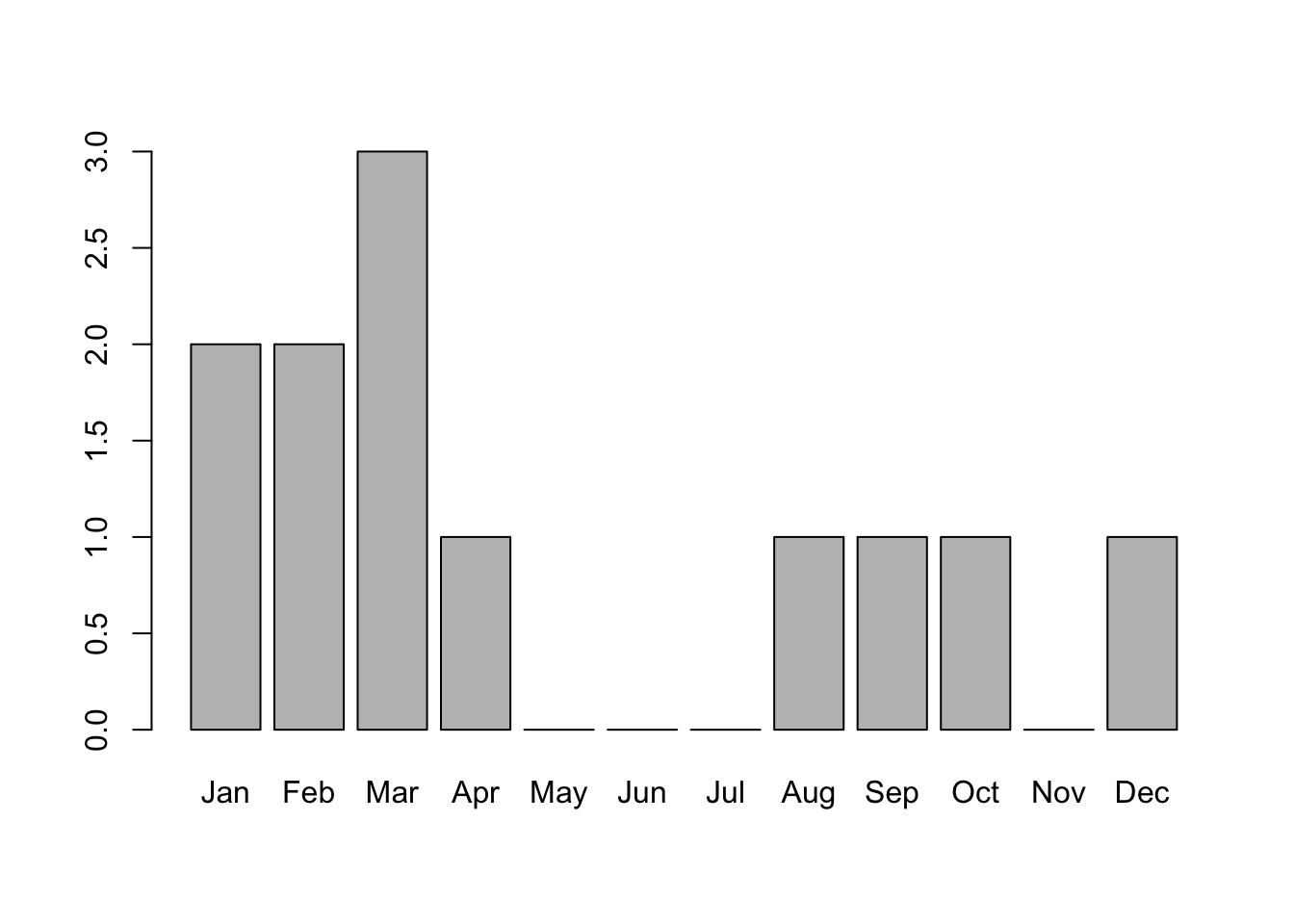
결과를 보면 알파벳 순서대로가 아니라 레벨에 지정된 순서대로 출력되는 것을 확인할 수 있다.
정확한 팩터 데이터를 사용하는 문제는 순서형 팩터 데이터를 가지고 회귀분석을 할 때도 중요하다. 어찌되었든, 단순히 문자열 벡터를 팩터로 변환하는 것을 넘어서, 해당 데이터의 의도와 목적에 맞게 팩터를 만들어 사용하는 것이 중요하다.
23.2 ggplot2 그래프도 같은 로직을 따른다.
ggplot2 그래프도 베이스 R의 팩터 처리 로직을 그대로 따른다. 다음 사례를 보자.
Rows: 344
Columns: 8
$ species <fct> Adelie, Adelie, Adelie, Adelie, Adelie, Adelie, Adelie, Ad…
$ island <fct> Torgersen, Torgersen, Torgersen, Torgersen, Torgersen, Tor…
$ bill_len <dbl> 39.1, 39.5, 40.3, NA, 36.7, 39.3, 38.9, 39.2, 34.1, 42.0, …
$ bill_dep <dbl> 18.7, 17.4, 18.0, NA, 19.3, 20.6, 17.8, 19.6, 18.1, 20.2, …
$ flipper_len <int> 181, 186, 195, NA, 193, 190, 181, 195, 193, 190, 186, 180,…
$ body_mass <int> 3750, 3800, 3250, NA, 3450, 3650, 3625, 4675, 3475, 4250, …
$ sex <fct> male, female, female, NA, female, male, female, male, NA, …
$ year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007…팩터의 레벨을 확인해 보자.
levels(penguins$species)[1] "Adelie" "Chinstrap" "Gentoo" ggplot2 그래프를 하나 만들어 보자. 오른쪽 레전의 순서에 주목하자.
penguins %>%
ggplot() +
geom_point(aes(x = bill_len, y = bill_dep, color = species, shape = species))Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_point()`).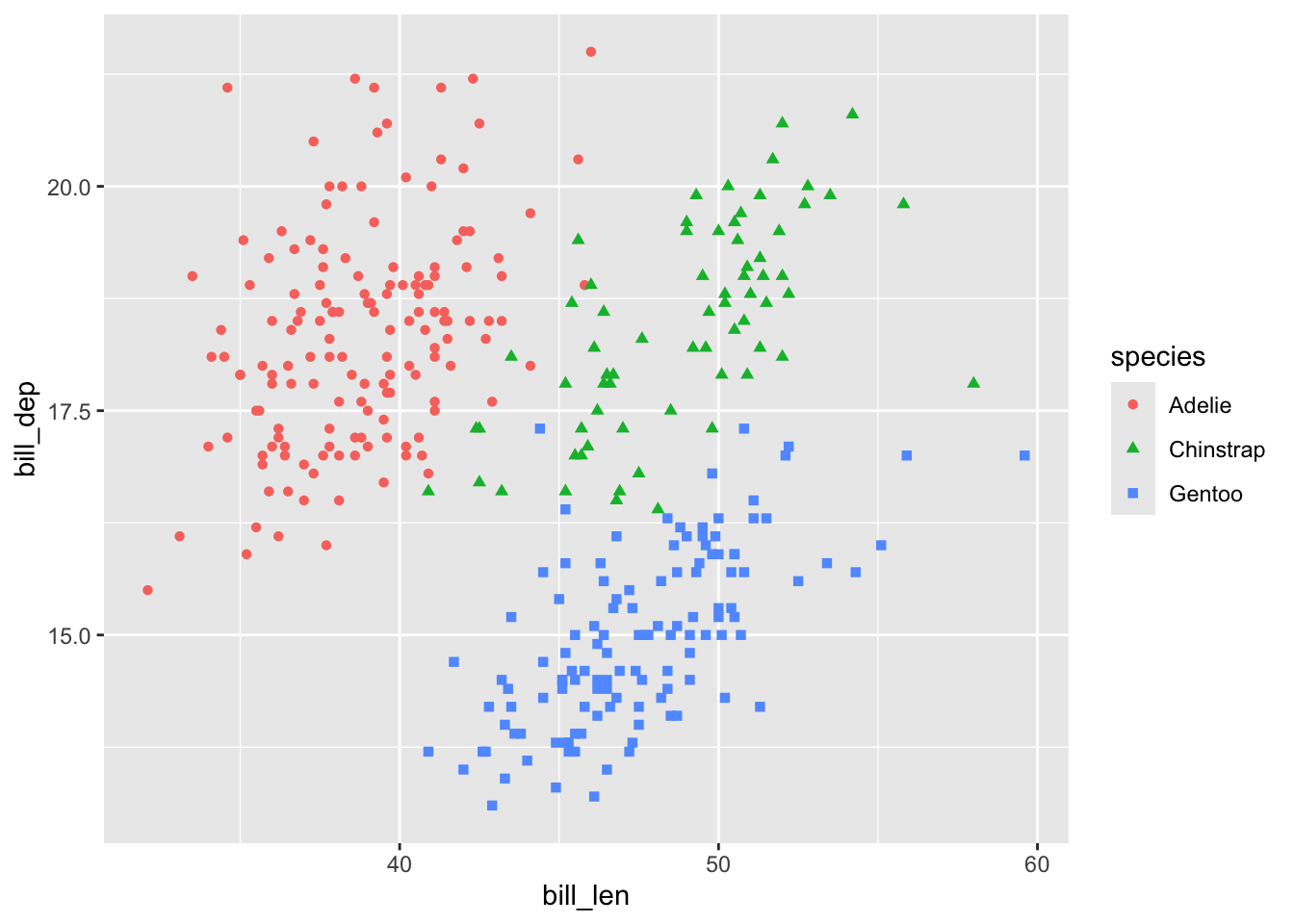
막대그래프를 만들어 보자. 역시 레벨 순서대로 표시된다.
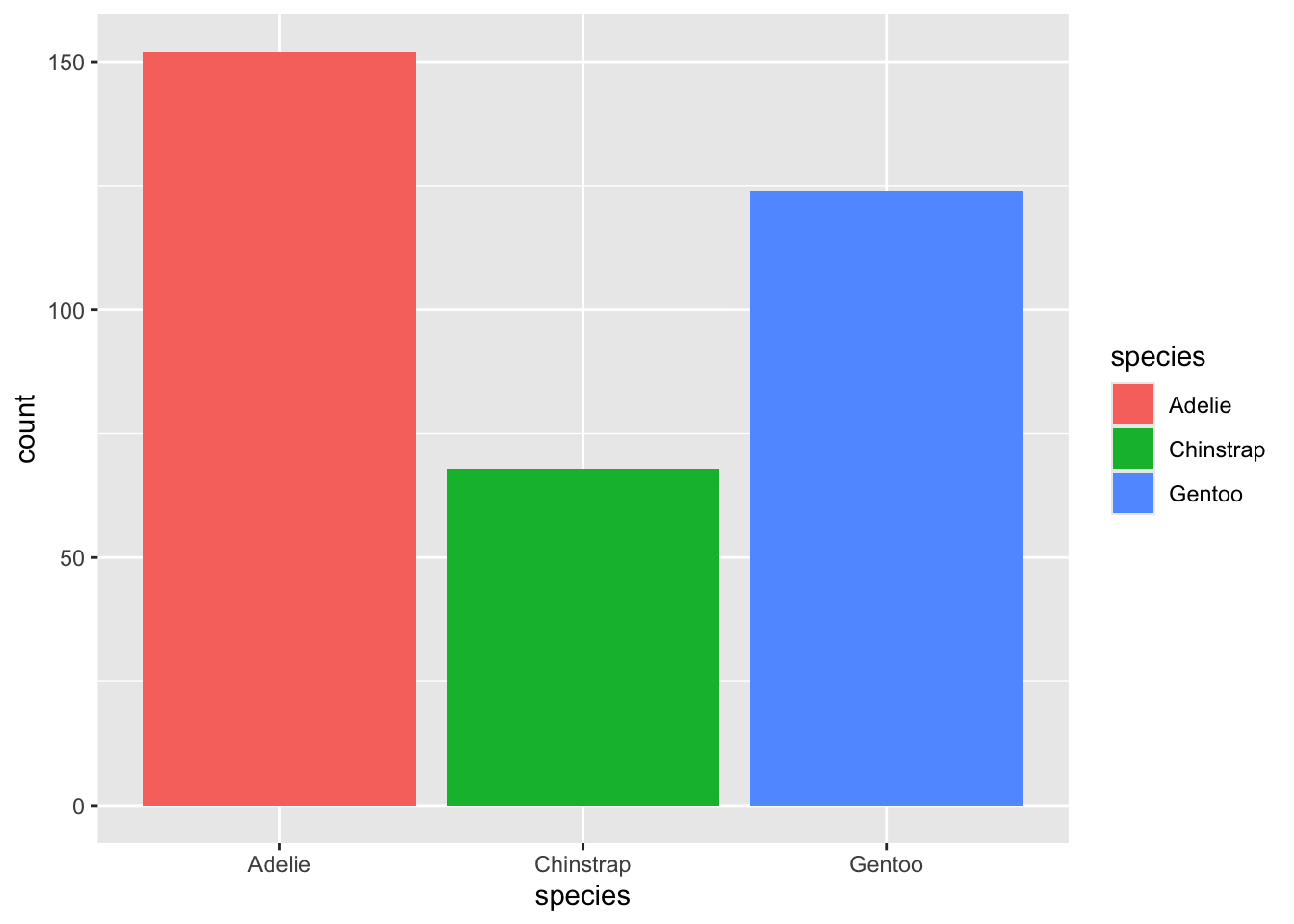
가로 막대그래프를 만들어 보자. 이 경우에는 아래에서 윗쪽으로 레벨의 순서에 따라 막대가 배치된다.
penguins %>%
ggplot() +
geom_bar(aes(x = species, fill = species)) +
coord_flip()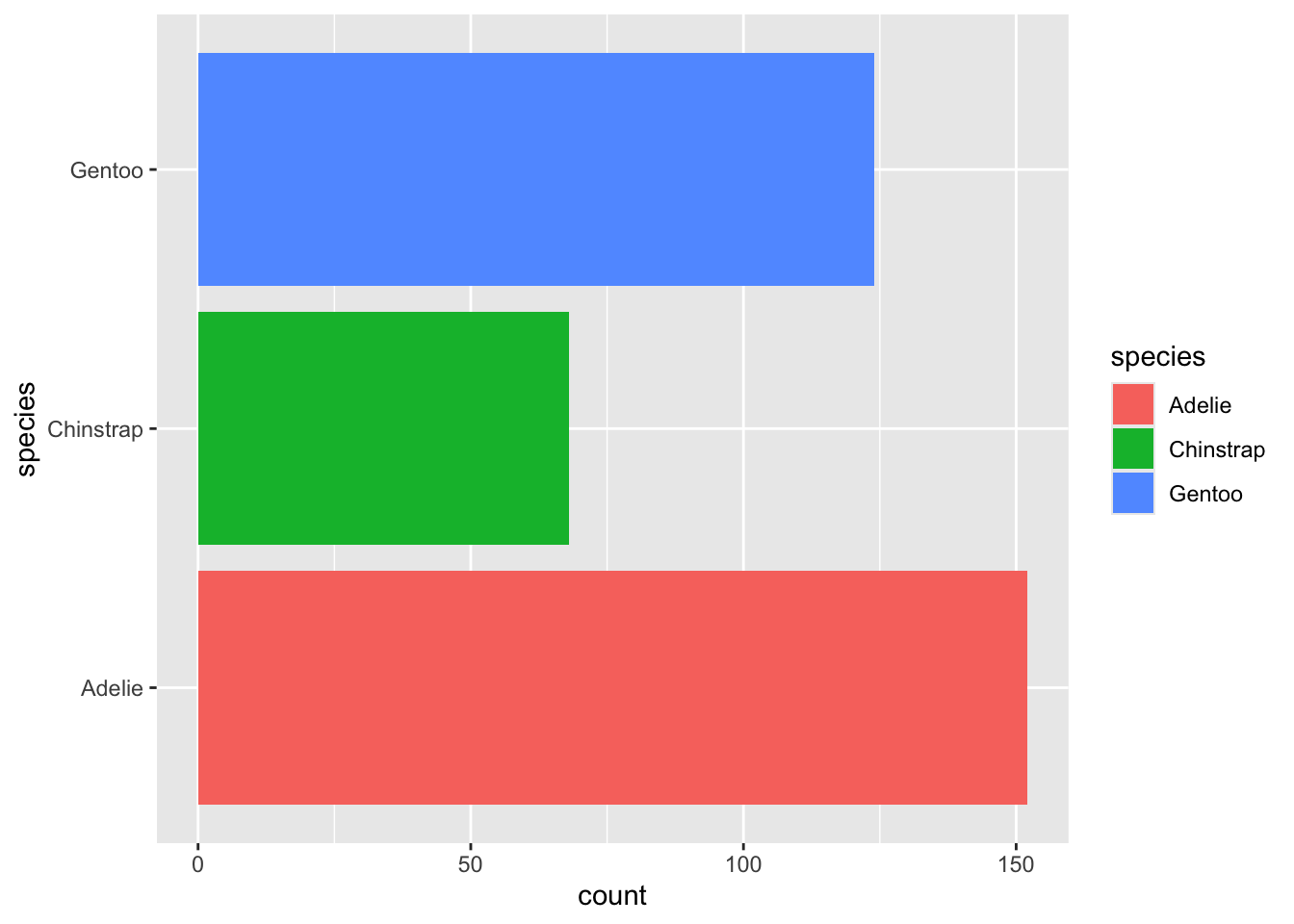
카테고리의 레벨이 많은 경우에는 카운트를 정렬해 주는 것이 좋을 것이다. 이렇게 하려면 팩터의 레벨을 조정해 주어야 한다. 이럴 때 큰 도움을 주는 것이 forcats 패키지이다. 다음 절에서 자세히 설명한다.
library(forcats)
penguins %>%
ggplot() +
geom_bar(aes(x = fct_rev(fct_infreq(species)), fill = species)) +
coord_flip()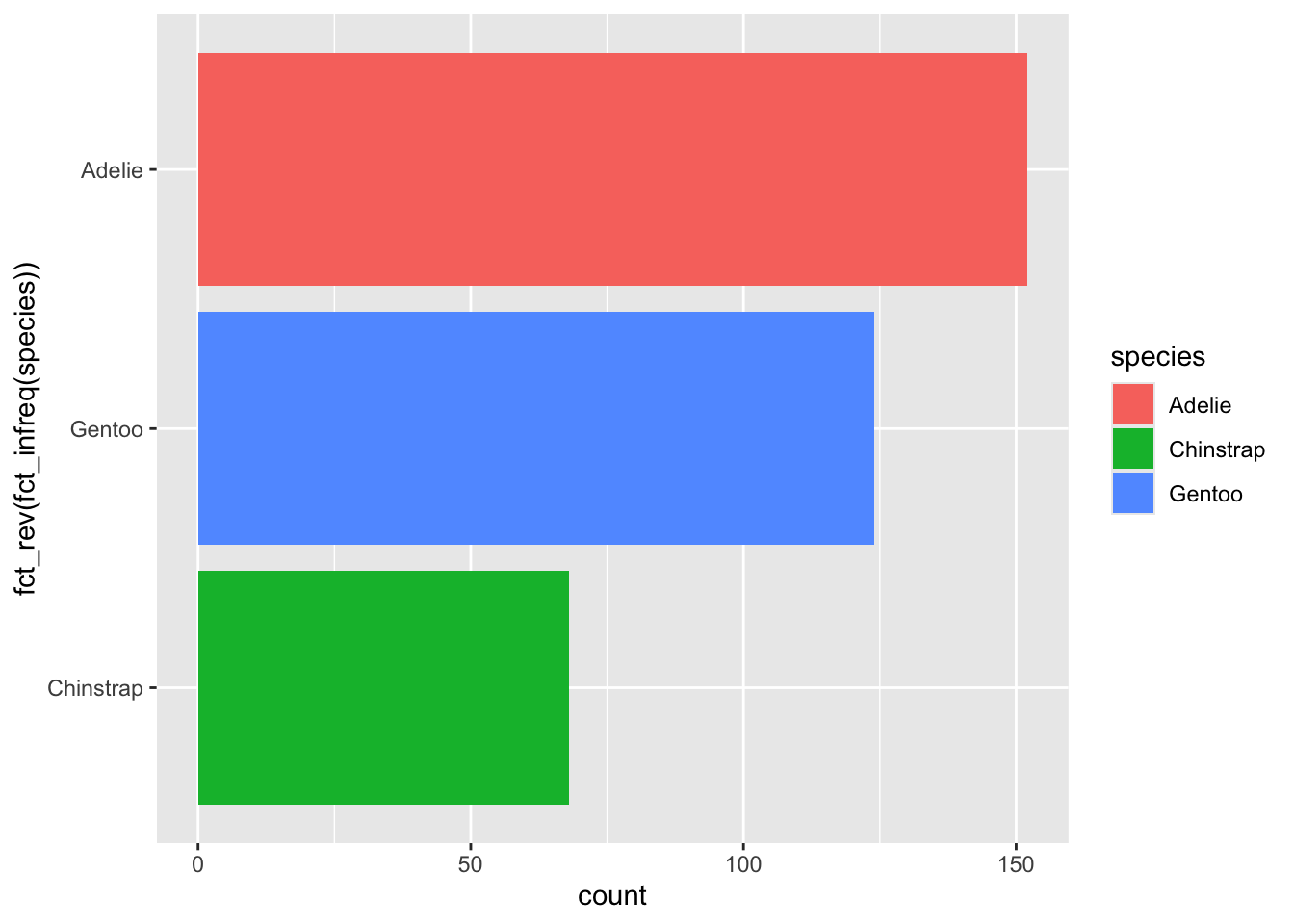
23.3 forcats 패키지로 팩터/그래프 조정
forcats 패키지는 팩터를 다루는 다양한 함수를 제공한다.
-
forcats패키지 함수 가운데fct_relevel()함수는 사용자가 지정한 순서대로 레벨이 정렬된 새로운 팩터를 만들어준다. 따라서 이 함수를 사용하면 순서를 사용자가 원하는 대로 정할 수 있다.
penguins %>%
ggplot() +
geom_bar(aes(x = fct_relevel(species, "Gentoo", "Chinstrap", "Adelie"), fill = species))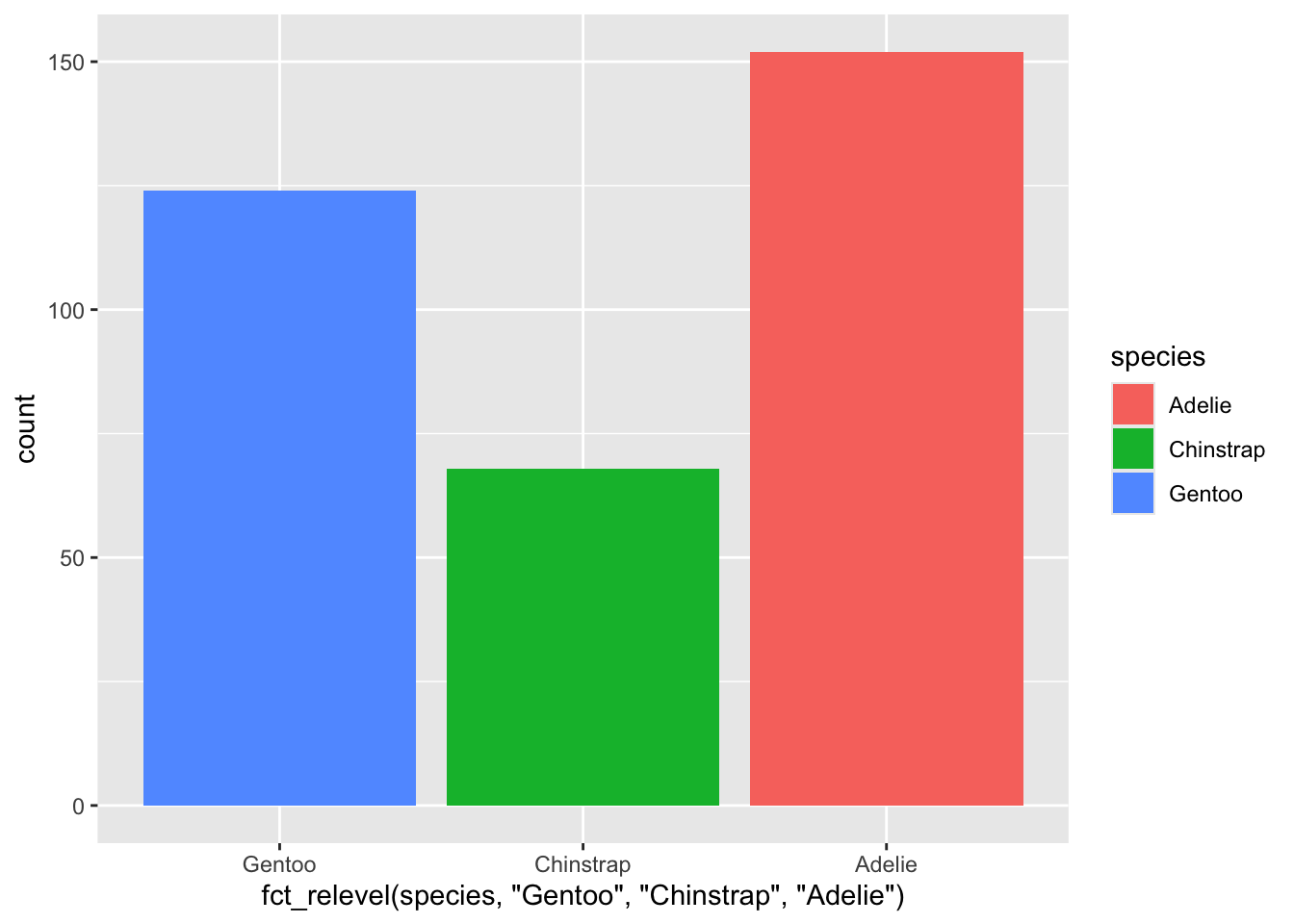
-
fct_infreq()함수는 레벨의 빈도수에 따라 정렬한다. 따라서 이 함수를 사용하면 빈도수가 높은 레벨이 앞에 오게 된다.
penguins %>%
ggplot() +
geom_bar(aes(x = fct_infreq(species), fill = species))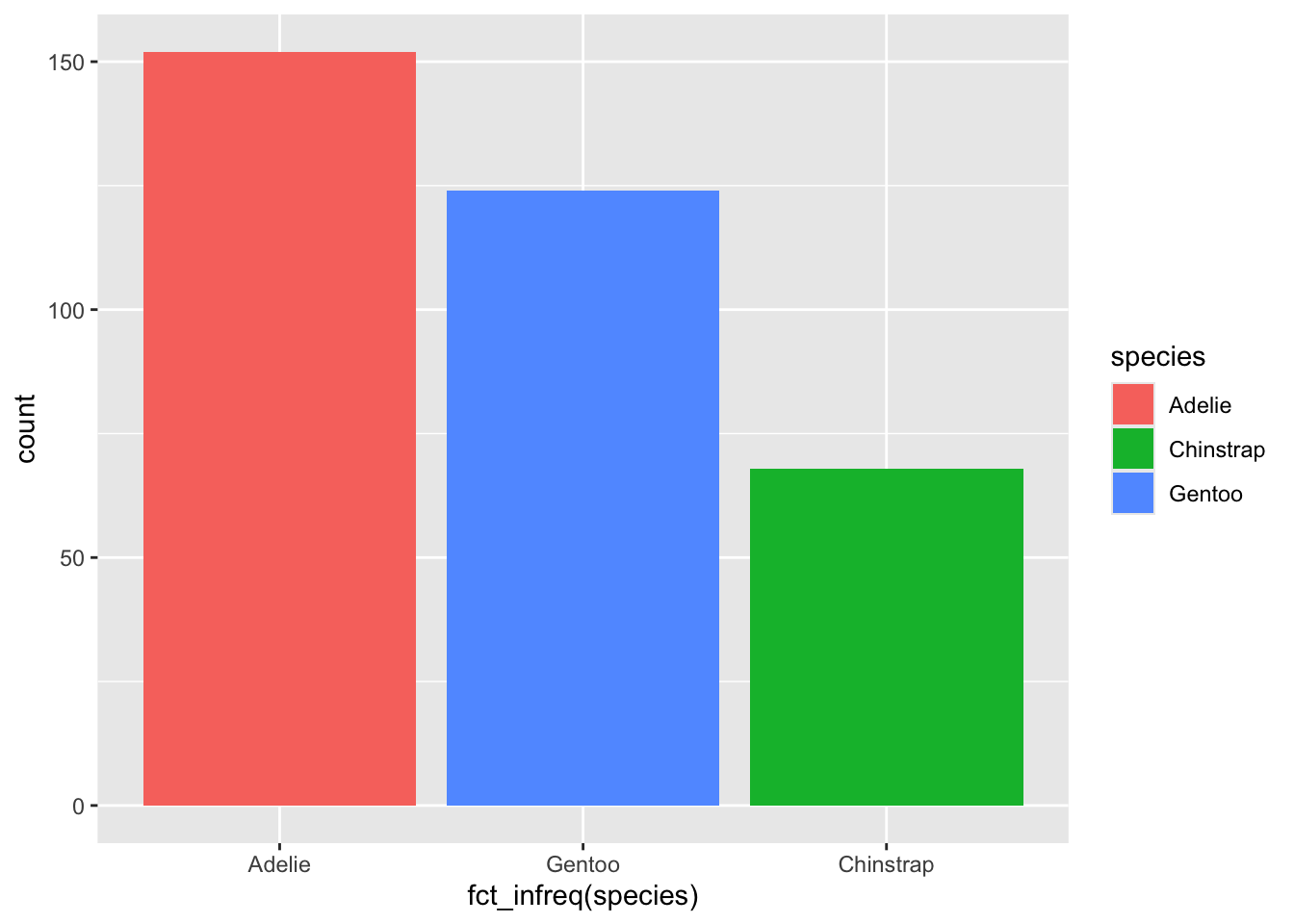
수평 막대그래프에서는 레벨의 빈도가 가장 높은 것이 아래에 있고, 빈도가 가장 낮은 것이 위에 놓인다.
penguins %>%
ggplot() +
geom_bar(aes(x = fct_infreq(species), fill = species)) +
coord_flip()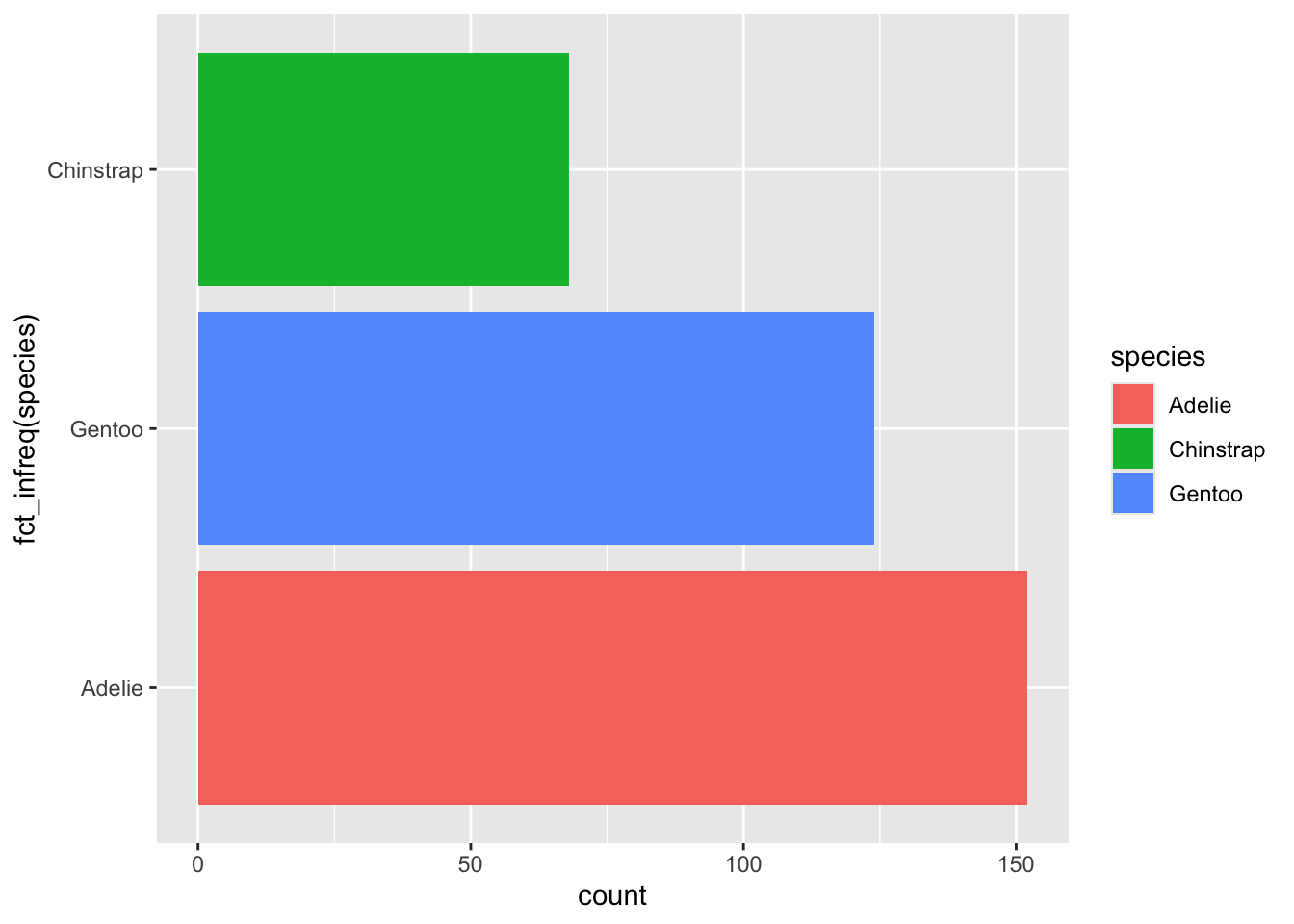
-
fct_rev()함수는 레벨의 순서를 반대로 뒤집는다. 따라서 위의 수평 막대그래프를 다음과 같이 빈도가 높은 것이 위로 가게 하려면 다음과 같이 하면 된다.
penguins %>%
ggplot() +
geom_bar(aes(x = fct_rev(fct_infreq(species)), fill = species)) +
coord_flip()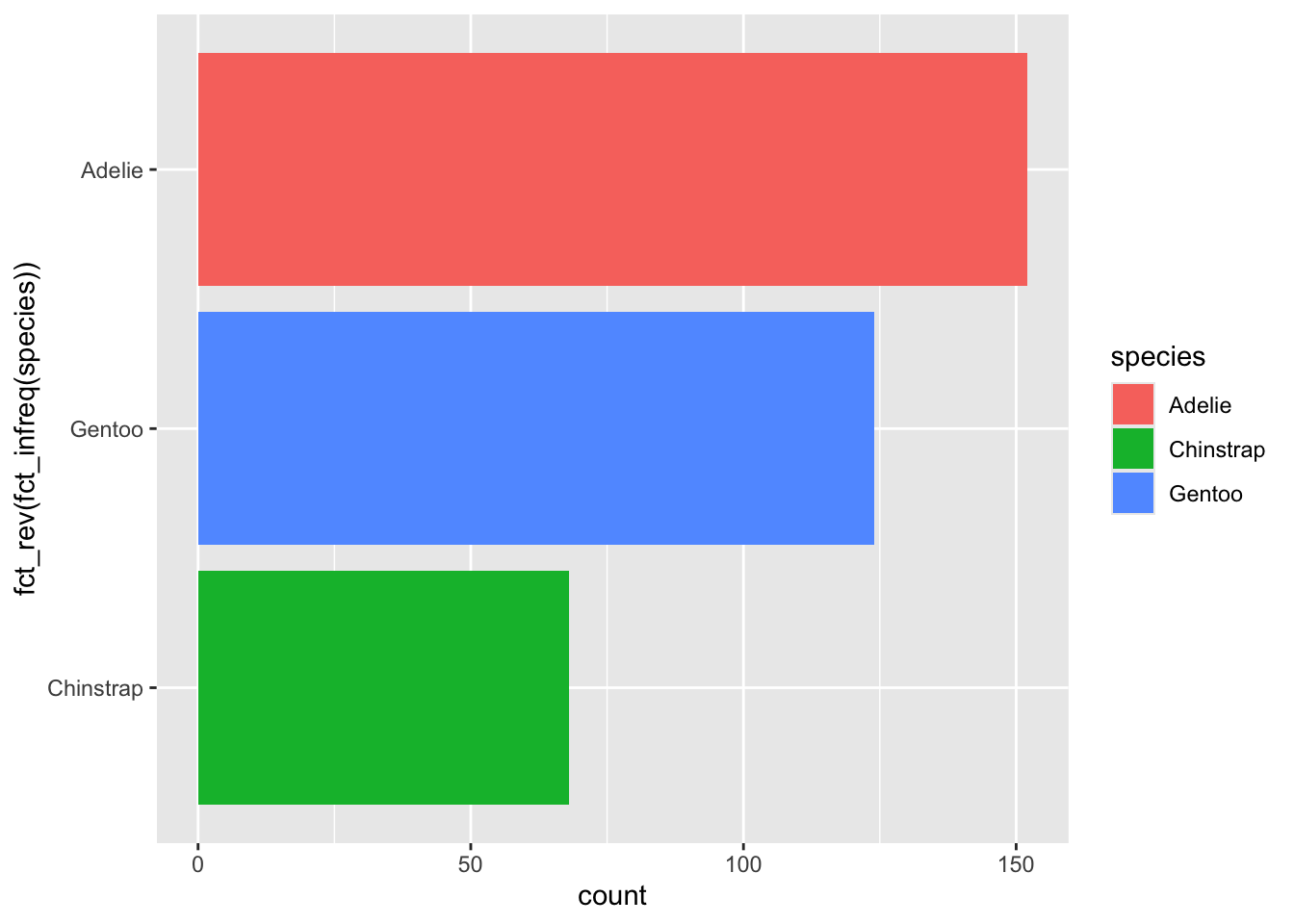
-
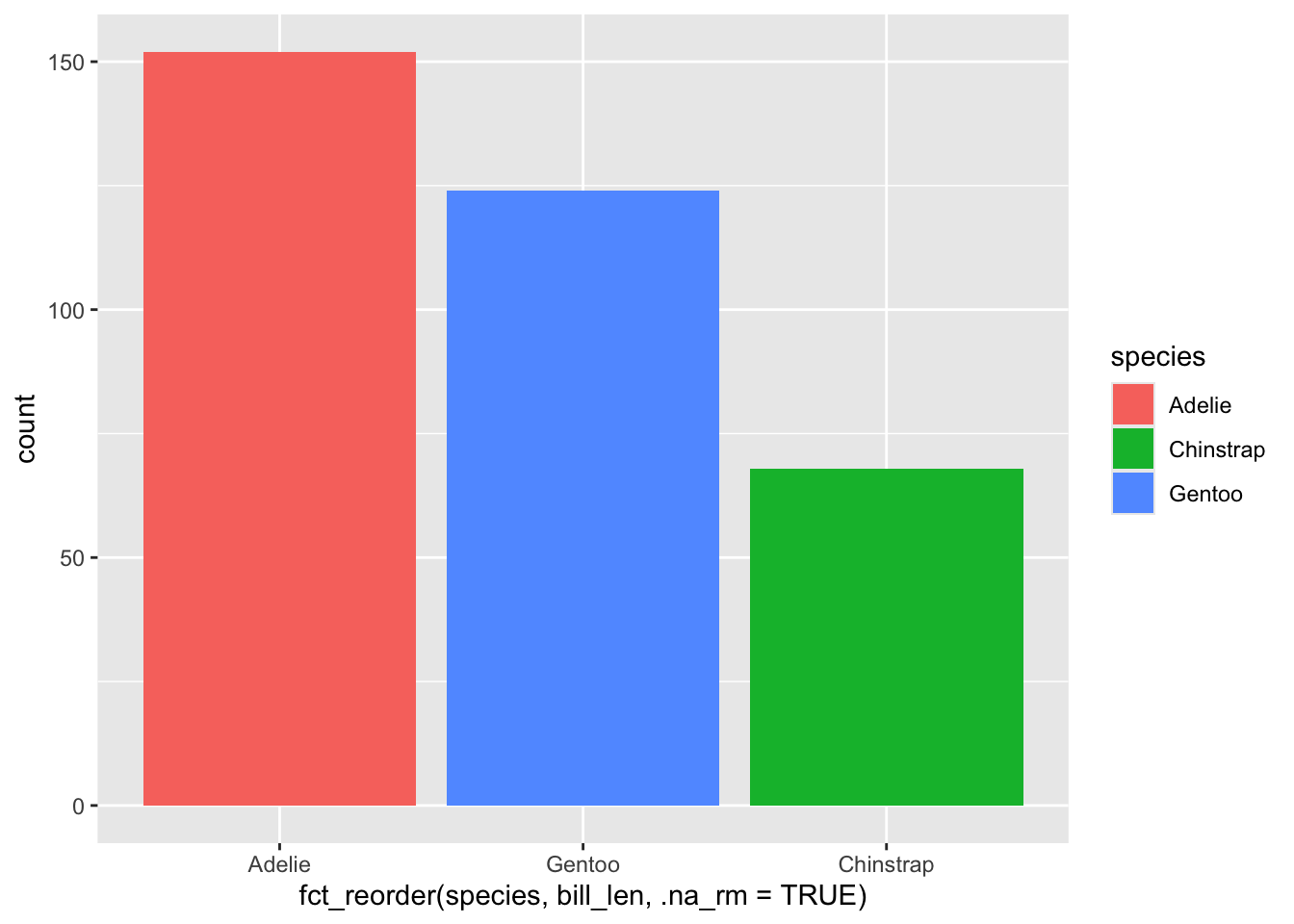
fct_reorder()함수는 특정 변수에 따라 레벨을 정렬하는데, 드폴트는 중앙값(median)을 기준으로 한다. 예를 들어, 다음과 같이 레벨을 정렬할 수 있다.
penguins %>%
ggplot() +
geom_bar(aes(
x = fct_reorder(species, bill_len, .na_rm = TRUE),
fill = species
))
-
fct_lump_*()함수는 여러 기준에 따라서 빈도가 낮은 레벨을 묶어서 “기타”로 묶는다.-
fct_lump_n():n개의 가장 흔한 레벨을 제외하고 나머지를 묶음 -
fct_lump_prop(): 어떤 비율(proportion) 이하의 것들을 기타로 묶음 -
fct_lump_min(): 어떤 빈도수 이하의 것들을 기타로 묶음 -
fct_lump_freq(): 어떤 빈도수 이하의 것들을 기타로 묶음
-
Rows: 1,704
Columns: 6
$ country <fct> "Afghanistan", "Afghanistan", "Afghanistan", "Afghanistan", …
$ continent <fct> Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, …
$ year <int> 1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, 1997, …
$ lifeExp <dbl> 28.801, 30.332, 31.997, 34.020, 36.088, 38.438, 39.854, 40.8…
$ pop <int> 8425333, 9240934, 10267083, 11537966, 13079460, 14880372, 12…
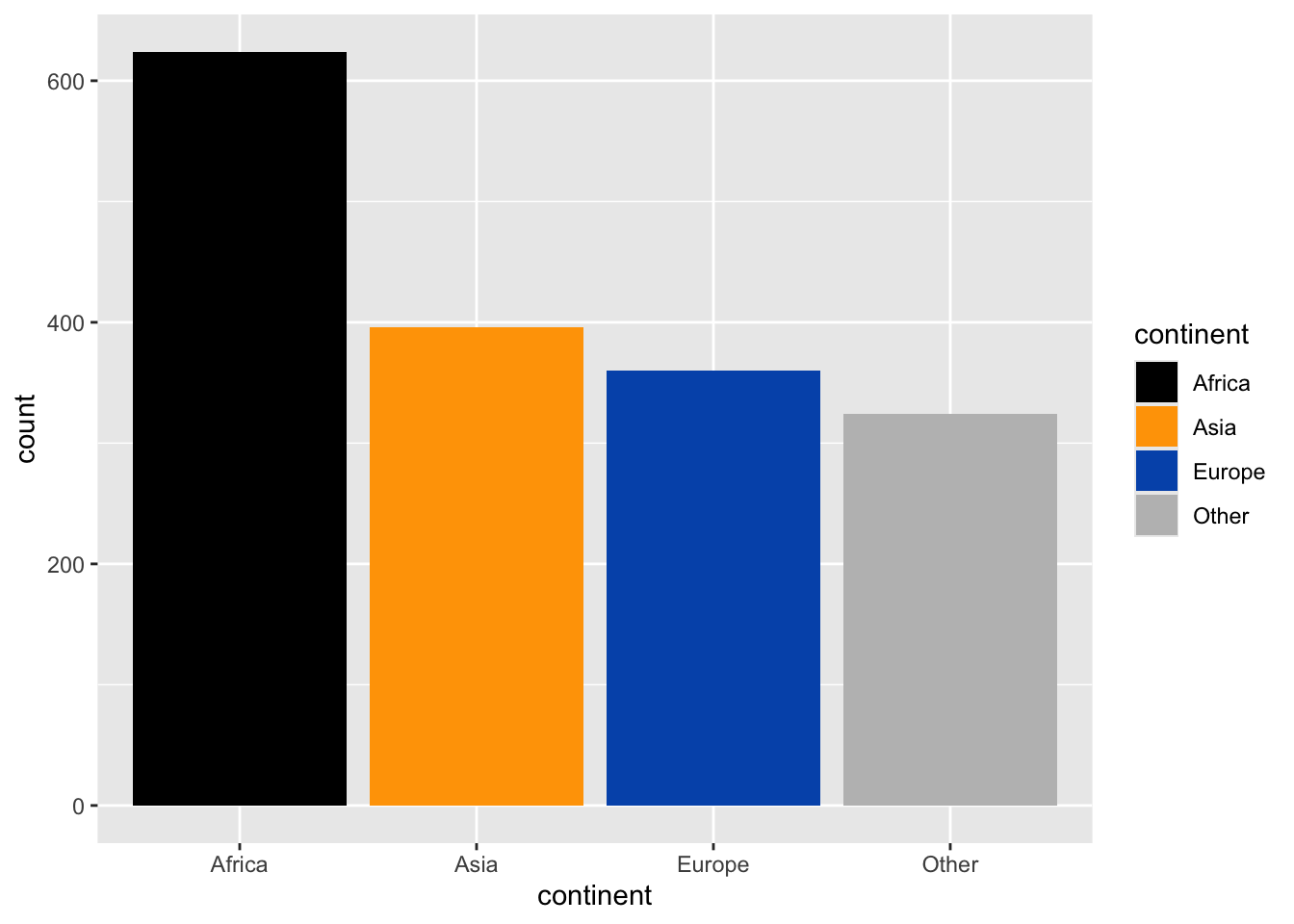
$ gdpPercap <dbl> 779.4453, 820.8530, 853.1007, 836.1971, 739.9811, 786.1134, …이 데이터에서 대륙별 데이터를 묶어서 기타로 묶어 보자.
# 오륜기 색을 사용
gapminder %>%
mutate(continent = fct_lump_n(continent, n = 3)) %>%
ggplot() +
geom_bar(aes(x = continent, fill = continent)) +
scale_fill_manual(
values = c(
"Africa" = "#000000", "Americas" = "steelblue",
"Asia" = "#FFA300", "Europe" = "#0057B8",
"Oceania" = "#009B3A", "Other" = "grey"
)
)