18 lubridate 패키지로 날짜와 시간 처리
프로그래밍 언어에서 날짜, 시간, 날짜/시간 데이터를 처리하는 것은 생각보다 간단하지 않다. 간단하지 않은 것은 여러 이유가 있다.
원래 날짜와 시간은 지구의 자전과 공전에 따른 물리적인 현상인데, 우리는 보통 달력이라는 인위적인 도구를 사용하는 것이 보통이다. 우리 한국만 하더라도 양력과 음력을 사용하고, 단기(檀紀)와 서기(西紀)가 있다. 영어권에서도 1 May, 2025 또는 May 3, 2025 등 표시 방법이 다르다.
우린 보통 1년을 365일로 친다. 하지만 지구 공전 시간은 물리적으로 365.2422일이다 보니 이것을 보정하지 않으면 4, 5년이 지나면 하루 차이가 나게 된다. 그래서 보통 4로 나누어 떨어지는 해를 윤년(閏年, leap year)이라고 하고, 그 해는 2월에 하루를 더 추가하는 것이 우리가 보통 쓰고 있는 그레고리 달력의 기준이다(좀 더 자세한 것은 인터넷을 참고한다). 따라서 2월 15일에서 3월 18일까지 기간을 계산하자면 윤년인지 아닌지를 알아야 된다.
컴퓨터는 물리적인 계산을 하기 때문에 물리적인 것과 인위적인 것을 처리해 주는 도구가 필요하다.
원래는 base R에는 날짜와 시간 처리 도구가 거의 없었다고 해도 과언이 아니다. 이 빈 지점을 채워주는 lubridate 패키지으로, 날짜, 시간, 날짜/시간 데이터를 처리하는 아주 강력한 기능을 제공하기 때문에 많은 사람들이 애용한다. Base R에서 날짜를 처리하는 함수들이 있기는 하지만 여기선 따로 설명하지 않는다.
이 패키지는 tidyverse 패키지 중 하나이며, 따라서 이 패키지를 사용하기 위해서는 tidyverse 패키지나 lubridate 패키지를 로딩하여 사용한다.
또는 다음과 같이 따로 로딩해도 된다.
Attaching package: 'lubridate'The following objects are masked from 'package:base':
date, intersect, setdiff, union18.1 날짜, 시간 데이터와 관련된 문제들
날짜/시간 데이터를 사용하는 것들과 관련해서 흔히 마주칠 수 있는 문제를 생각해 보고 lubridate 패키지를 사용법에 대해 설명하고자 한다.
- 우선 R 언어에서 사용할 수 있게 날짜/시간 데이터로 변환되어야 한다.
- 엑셀 데이터셋을 읽는 경우 문자열을 된 것을 날짜/시간 데이터로 바꿔줘야 한다. 또 그러면서 날짜/시간 표현이 어떻게 되어 있는지를 고려해야 한다. 원 데이터가 문자열로
2025-05-17,2025년 5월 17일,2026/05/17,May 17, 2025등 다양하게 존재할 수 있다.
- 엑셀 데이터셋을 읽는 경우 문자열을 된 것을 날짜/시간 데이터로 바꿔줘야 한다. 또 그러면서 날짜/시간 표현이 어떻게 되어 있는지를 고려해야 한다. 원 데이터가 문자열로
- 날짜와 시간 데이터를 가지고 여러 가지 연산을 수행할 수 있다. 오늘(날짜 데이터)을 기준으로 150일(기간) 뒤의 날짜를 어떻게 계산할지 고민해야 한다.
- 시간대(timezone) 문제가 있다. 나라가 크거나 지구 여러 곳에서 사용한다면 이런 것을 고려해야 한다.
- 어떤 나라에서 Daylight Saving Time(DST, 일광 절약 시간)을 수행한다.
- 사용자가 이해할 수 있게 날짜/시간 데이터를 정확하게 표시해 주어야 한다. 계산한 요일이 “금요일” 또는 “Friday” 등으로 상황에 맞게 표시해 줄 필요가 있다.
이와 같은 여러 문제들을 다루기 위해 lubridate 패키지에는 다양한 함수들이 존재한다.
18.2 텍스트 데이터를 날짜로 변환하기
다음과 같은 데이터프레임으로 시작해 보자.
library(tidyverse)
stroke_time <- tibble::tribble(
~Id, ~StrokeOnset, ~EventRecognition, ~ArrivalTime, ~CtCompleted,
"p1", "23-1-15 오후 2:25", "exact", "2023.1.15 15:00", "2023-1-15 15:56",
"p2", "25-2-20 오전 11:30", "presumed", "2025.2.20 17:00", "2025-2-20 18:05",
"p3", "19-6-5 오후 01:00", "exact", "2019.6.5 14:00", "2019-6-5 15:30"
)
stroke_time# A tibble: 3 × 5
Id StrokeOnset EventRecognition ArrivalTime CtCompleted
<chr> <chr> <chr> <chr> <chr>
1 p1 23-1-15 오후 2:25 exact 2023.1.15 15:00 2023-1-15 15:56
2 p2 25-2-20 오전 11:30 presumed 2025.2.20 17:00 2025-2-20 18:05
3 p3 19-6-5 오후 01:00 exact 2019.6.5 14:00 2019-6-5 15:30 현재 위 데이터프레임에는 날짜/시간 정보가 “문자열”로 저장되어 있다. 이것을 날짜/시간 데이터로 변환하는 문제를 생각해 보자. 프로그래밍에서는 이런 종류의 작업을 파싱(parsing)이라고 한다.
lubridate 패키지에는 파싱에 필요한 다양한 함수들이 준비되어 있다.
-
y(year),m(month),d(day)을 조합하여 날짜 데이터를 변환하는 함수들 - 거기에
h(hour),m(minute),s(second)을 조합하여 시간 데이터를 변환하는 함수들- 예를 들어
ymd_hms()는 문자열을 날짜/시간 데이터로 변환한다.
- 예를 들어
보통 ISO 8601 형식은 날짜/시간을 표현하는 표준 형식인데, 2025-05-17 14:30:00 또는 2025-05-17T14:30:00 등으로 표현한다. 문자열 데이터가 이런 형식으로 저장되어 있으면 다음과 같이 변환할 수 있다.
ymd_hm(stroke_time$CtCompleted)[1] "2023-01-15 15:56:00 UTC" "2025-02-20 18:05:00 UTC"
[3] "2019-06-05 15:30:00 UTC"ymd_hm() 함수를 사용한 이유는 데이터가 연도-월-일 시간:분 형식으로 되어 있기 때문이다. 만약 한국 시간대로 변환하려면 tz 인자에 "Asia/Seoul"을 추가한다.
ymd_hm(stroke_time$CtCompleted, tz = "Asia/Seoul")[1] "2023-01-15 15:56:00 KST" "2025-02-20 18:05:00 KST"
[3] "2019-06-05 15:30:00 KST"만약 010210 문자열이 첫 두개가 날짜, 다음 두개가 월, 마지막 두개가 2자리 연도라면 다음과 같이 dmy() 함수를 사용해서 날짜/시간 데이터로 변환할 수 있다.
dmy(010210)[1] "2010-02-01"StrokeOnset과 ArrivalTime 열은 좀 특이하게 되어 있어서 ymd_hms() 함수를 사용해서 쉽게 변경하기 쉽지 않다. 이런 경우에는 parse_date_time() 함수를 사용해서 변환한다. 이 함수를 사용하려면 표 18.1에 정리된 것과 같은 읽을 문자열에 대한 패턴을 참고해야 한다.
| 패턴 | 의미 | 예시 |
|---|---|---|
%Y |
4자리 연도 | 2025 |
%y |
2자리 연도 | 25 |
%m |
2자리 월 | 01, 02, …, 12 |
%d |
2자리 일 | 01, 02, …, 31 |
%H |
24시간제 시간 | 00, 01, …, 23 |
%I |
12시간제 시간 | 01, 02, …, 12 |
%M |
분 | 00, 01, …, 59 |
%S |
초 | 00, 01, …, 59 |
%p |
AM/PM | AM, PM |
%z |
시간대 오프셋 | +0900 |
%Z |
시간대 이름 | KST, UTC |
예를 들어, “2025-05-17 14:30:45” 형식의 문자열을 파싱하려면:
parse_date_time("2025-05-17 14:30:45", orders = "%Y-%m-%d %H:%M:%S")[1] "2025-05-17 14:30:45 UTC"그래서 위 데이터프레임에서 ArrivalTime 열은 다음과 같이 변환할 수 있다.
parse_date_time(stroke_time$ArrivalTime, orders = "%Y.%m.%d %H:%M", tz = "Asia/Seoul")[1] "2023-01-15 15:00:00 KST" "2025-02-20 17:00:00 KST"
[3] "2019-06-05 14:00:00 KST"그런데 StrokeOnset 열은 좀 특이하다.
stroke_time$StrokeOnset[1] "23-1-15 오후 2:25" "25-2-20 오전 11:30" "19-6-5 오후 01:00" 이 경우에는 “오전”, “오후” 등의 정보가 있어서 %p 패턴을 사용해서 될 것 같지만 잘 되지 않는다.
parse_date_time(stroke_time$StrokeOnset, orders = "%y-%m-%d %p %I:%M")Warning: All formats failed to parse. No formats found.[1] NA NA NA이것은 “오전”, “오후”를 인식하지 못한다. 이런 경우에는 stringr 패키지의 함수를 사용해서 문자열을 변환해야 한다.
library(stringr)
stroke_time$StrokeOnset %>%
str_replace("오전", "AM") %>%
str_replace("오후", "PM") %>%
parse_date_time(orders = "%y-%m-%d %p %I:%M", tz = "Asia/Seoul")[1] "2023-01-15 14:25:00 KST" "2025-02-20 11:30:00 KST"
[3] "2019-06-05 13:00:00 KST"이제 위의 로직을 dplyr 패키지를 사용하여 한번에 정리해 보자.
new_df <- stroke_time %>%
mutate(
StrokeOnset = str_replace(StrokeOnset, "오전", "AM") %>%
str_replace("오후", "PM") %>%
parse_date_time(orders = "%y-%m-%d %p %I:%M", tz = "Asia/Seoul"),
ArrivalTime = parse_date_time(ArrivalTime, orders = "%Y.%m.%d %H:%M", tz = "Asia/Seoul"),
CtCompleted = ymd_hm(CtCompleted, tz = "Asia/Seoul")
)
new_df# A tibble: 3 × 5
Id StrokeOnset EventRecognition ArrivalTime
<chr> <dttm> <chr> <dttm>
1 p1 2023-01-15 14:25:00 exact 2023-01-15 15:00:00
2 p2 2025-02-20 11:30:00 presumed 2025-02-20 17:00:00
3 p3 2019-06-05 13:00:00 exact 2019-06-05 14:00:00
# ℹ 1 more variable: CtCompleted <dttm>이렇게 해야 하는 뒤에서 설명할 날짜/시간 데이터에 대한 연산을 정확하게 할 수 있다.
18.3 날짜/시간 정보를 모으기
날짜/시간 정보가 다음과 같이 수집되어 있다고 생각해 보자. 어떤 치료를 시작한 시점을 말한다.
tx_time <- tibble::tribble(
~Id, ~TxYear, ~TxMonth, ~TxDay, ~TxHour, ~TxMinute,
"p3", 2025L, 1L, 21L, 9L, 24L,
"p4", 2024L, 3L, 30L, 4L, 23L,
"p5", 2023L, 4L, 23L, 15L, 46L
)
tx_time# A tibble: 3 × 6
Id TxYear TxMonth TxDay TxHour TxMinute
<chr> <int> <int> <int> <int> <int>
1 p3 2025 1 21 9 24
2 p4 2024 3 30 4 23
3 p5 2023 4 23 15 46이런 데이터가 주어졌을 때 이것을 “숫자” 그대로 사용하는 것은 나중 계산에 오류가 발생할 수 있다. 날짜/시간 데이터 타입으로 변경해 주어야 한다. 이 경우는 lubridate 패키지의 make_date() 또는 make_datetime() 함수를 사용한다.
make_date(2025, 1, 21)[1] "2025-01-21"tx_time %>%
mutate(
TxDate = make_date(TxYear, TxMonth, TxDay),
TxDateTime = make_datetime(TxYear, TxMonth, TxDay, TxHour, TxMinute)
)# A tibble: 3 × 8
Id TxYear TxMonth TxDay TxHour TxMinute TxDate TxDateTime
<chr> <int> <int> <int> <int> <int> <date> <dttm>
1 p3 2025 1 21 9 24 2025-01-21 2025-01-21 09:24:00
2 p4 2024 3 30 4 23 2024-03-30 2024-03-30 04:23:00
3 p5 2023 4 23 15 46 2023-04-23 2023-04-23 15:46:0018.4 날짜/시간 데이터에서 정보 추출
날짜/시간 데이터에서 연도, 월, 일, 시간, 분, 초, 요일, 분기 등 정보를 추출하는 함수들이 있다.
-
year(),month(),day(): 연, 월, 일 -
hour(),minute(),second(): 시, 분, 초 -
tz(): 시간대 -
wday(): 요일 -
quarter(): 분기 -
semester(): 반기
new_df# A tibble: 3 × 5
Id StrokeOnset EventRecognition ArrivalTime
<chr> <dttm> <chr> <dttm>
1 p1 2023-01-15 14:25:00 exact 2023-01-15 15:00:00
2 p2 2025-02-20 11:30:00 presumed 2025-02-20 17:00:00
3 p3 2019-06-05 13:00:00 exact 2019-06-05 14:00:00
# ℹ 1 more variable: CtCompleted <dttm>year(new_df$StrokeOnset)[1] 2023 2025 2019month(new_df$StrokeOnset)[1] 1 2 6day(new_df$StrokeOnset)[1] 15 20 5hour(new_df$StrokeOnset)[1] 14 11 13minute(new_df$StrokeOnset)[1] 25 30 0second(new_df$StrokeOnset)[1] 0 0 0wday(new_df$StrokeOnset) # 요일[1] 1 5 4quarter(new_df$StrokeOnset) # 분기[1] 1 1 2semester(new_df$StrokeOnset) # 반기[1] 1 1 1wday() 함수는 요일을 숫자로 반환하는 데, label = TRUE 인자를 추가하면 요일을 문자열로 반환해 준다. 윈도우(Windows) 환경에서는 한글로 출력할 것이다.
wday(new_df$StrokeOnset, label = TRUE) # 요일[1] Sun Thu Wed
Levels: Sun < Mon < Tue < Wed < Thu < Fri < Sat이 함수의 도움말을 보면 locale 인자가 있는데, 디폴트 값인 Sys.getlocale("LC_TIME") 값을 사용한다. 이 값은 운영체제에 따라 다르다. 현재 R 세션에서 로캘을 보려면 Sys.getlocale("LC_TIME") 함수를 사용하고, Sys.setlocale("LC_TIME", "ko_KR.UTF-8") 함수를 사용하여 로캘을 변경할 수 있다.ㄴ
Sys.setlocale("LC_TIME", "ko_KR.UTF-8")[1] "ko_KR.UTF-8"Sys.getlocale("LC_TIME")[1] "ko_KR.UTF-8"wday(new_df$StrokeOnset, label = TRUE) # 요일[1] 일 목 수
Levels: 일 < 월 < 화 < 수 < 목 < 금 < 토18.5 날짜/시간 데이터 수정
앞에서 정보를 추출하는 함수를 할당 좌변에 둬서 날짜/시간 데이터를 수정할 수 있다.
the_date <- ymd_hms("2025-05-17 14:30:45", tz = "Asia/Seoul")
the_date[1] "2025-05-17 14:30:45 KST"연도가 2025가 아니라 2024로 바꾸려면 다음과 같이 실행한다.
year(the_date) <- 2024
the_date[1] "2024-05-17 14:30:45 KST"만찬가지로 5월이 아니라 6월로 바꾸려면 다음과 같이 실행한다.
month(the_date) <- 6
the_date[1] "2024-06-17 14:30:45 KST"다른 값들도 마찬가지이다. update() 함수를 사용하여 여러 값을 한번에 수정할 수 있다.
update(the_date, year = 2023, month = 7, hour = 15)[1] "2023-07-17 15:30:45 KST"18.6 기간 연산
lubridate 패키지는 기간을 목적에 따라 3가지 클래스(class)로 제공한다.
-
Duration: 시간 간격을 초 단위로 표현하는 클래스 -
Interval: 시작 시점과 끝 시점을 표현하는 클래스
-
Period: 사람들이 흔히 표현하는 기간
18.6.1 Duration 클래스
Duration 클래스는 시간 간격을 초 단위로 표현하는 클래스이다. 다음과 같은 함수들을 사용한 Duration 클래스를 만든다.
-
duration()함수 -
dseconds(),dminutes(),dhours(),ddays(),dweeks(),dmonths(),dyears()함수
다음 예와 같이 duraiton() 함수에 단위를 추가하여 만들 수도 있고, d로 시작되는 함수를 사용해도 같은 의미의 객체를 만들 수 있다. 어찌되었든 결과는 초 단위로 표현되다는 점을 주목한다.
duration(10) # 10초
## [1] "10s"
dseconds(10) # 10초
## [1] "10s"
duration(10, "minutes") # 10분을 초 단위로 표현
## [1] "600s (~10 minutes)"
dminutes(10) # 10분을 초 단위로 표현
## [1] "600s (~10 minutes)"
duration(0.5, "hours") # 0.5시간을 초 단위로 표현
## [1] "1800s (~30 minutes)"
dhours(0.5) # 0.5시간을 초 단위로 표현
## [1] "1800s (~30 minutes)"
duration(1, "days") # 1일을 초 단위로 표현
## [1] "86400s (~1 days)"
ddays(1) # 1일을 초 단위로 표현
## [1] "86400s (~1 days)"
duration(0.3, "weeks") # 0.3주를 초 단위로 표현
## [1] "181440s (~2.1 days)"
duration(5, "months") # 5개월을 초 단위로 표현
## [1] "13149000s (~21.74 weeks)"
dmonths(5) # 5개월을 초 단위로 표현
## [1] "13149000s (~21.74 weeks)"
duration(1, "years") # 1년을 초 단위로 표현
## [1] "31557600s (~1 years)"
dyears(1) # 1년을 초 단위로 표현
## [1] "31557600s (~1 years)"위에서 본 new_df 데이터프레임에서 StrokeOnset 열과 ArrivalTime 열의 차이를 계산해 보자.
new_df# A tibble: 3 × 5
Id StrokeOnset EventRecognition ArrivalTime
<chr> <dttm> <chr> <dttm>
1 p1 2023-01-15 14:25:00 exact 2023-01-15 15:00:00
2 p2 2025-02-20 11:30:00 presumed 2025-02-20 17:00:00
3 p3 2019-06-05 13:00:00 exact 2019-06-05 14:00:00
# ℹ 1 more variable: CtCompleted <dttm>날짜를 날짜를 빼면 timediff 클래스가 된다.
new_df$ArrivalTime - new_df$StrokeOnsetTime differences in mins
[1] 35 330 60이것을 as.druation() 함수를 사용하여 Duration 클래스로 변환할 수 있다.
as.duration(new_df$ArrivalTime - new_df$StrokeOnset)[1] "2100s (~35 minutes)" "19800s (~5.5 hours)" "3600s (~1 hours)" 이것은 모두 초 단위의 기간이다. 분 단위로 보려면 분 단위로 나누면 된다.
as.duration(new_df$ArrivalTime - new_df$StrokeOnset) / dminutes(1)[1] 35 330 60이것은 분 단위의 기간이다.
분 단위의 평균 시간을 계산해 보자.
mean(as.duration(new_df$ArrivalTime - new_df$StrokeOnset) / dminutes(1))[1] 141.66672025-05-17 14:30:45 시간에서 1시간 50분 후의 시간을 계산해 보자.
18.6.2 Interval 클래스
Interval 클래스는 시작 시점과 끝 시점을 표현하는 클래스이다. 다음과 같은 함수들을 사용한 Interval 클래스를 만든다. Interval 클래스를 설명하기 위해 다음가 같은 페이크 데이터프레임을 사용한다.
admission_discharge <- tibble::tribble(
~Id, ~admission_date, ~discharge_date,
"p34", "2025/01/05", "2025/01/10",
"p64", "2024/12/25", "2025/01/07",
"p87", "2024/11/25", "2025/03/01",
"p79", "2025/01/06", "2025/03/15",
"p99", "2025/02/05", "2025/3/20",
"p100", "2025/02/15", "2025/03/25"
)
admission_discharge# A tibble: 6 × 3
Id admission_date discharge_date
<chr> <chr> <chr>
1 p34 2025/01/05 2025/01/10
2 p64 2024/12/25 2025/01/07
3 p87 2024/11/25 2025/03/01
4 p79 2025/01/06 2025/03/15
5 p99 2025/02/05 2025/3/20
6 p100 2025/02/15 2025/03/25 먼저 날짜/시간 데이터로 변환한다.
ad_df <- admission_discharge %>%
mutate(
admission_date = ymd(admission_date),
discharge_date = ymd(discharge_date)
)
ad_df# A tibble: 6 × 3
Id admission_date discharge_date
<chr> <date> <date>
1 p34 2025-01-05 2025-01-10
2 p64 2024-12-25 2025-01-07
3 p87 2024-11-25 2025-03-01
4 p79 2025-01-06 2025-03-15
5 p99 2025-02-05 2025-03-20
6 p100 2025-02-15 2025-03-25 이 데이터를 가지고 환자의 입원 기간을 ggplot2 패키지에 있는 geom_segment 함수를 사용하여 표현해 보자.
library(ggplot2)
df <- ad_df %>%
mutate(Y = row_number())
ggplot(df) +
geom_segment(aes(x = admission_date, y = Y, xend = discharge_date, yend = Y)) +
geom_vline(xintercept = ymd("2025-01-06"), color = "blue") +
geom_vline(xintercept = ymd("2025-02-10"), color = "red") +
scale_x_date(date_breaks = "2 weeks", date_labels = "%Y-%m") +
labs(x = "Date", y = "RowID")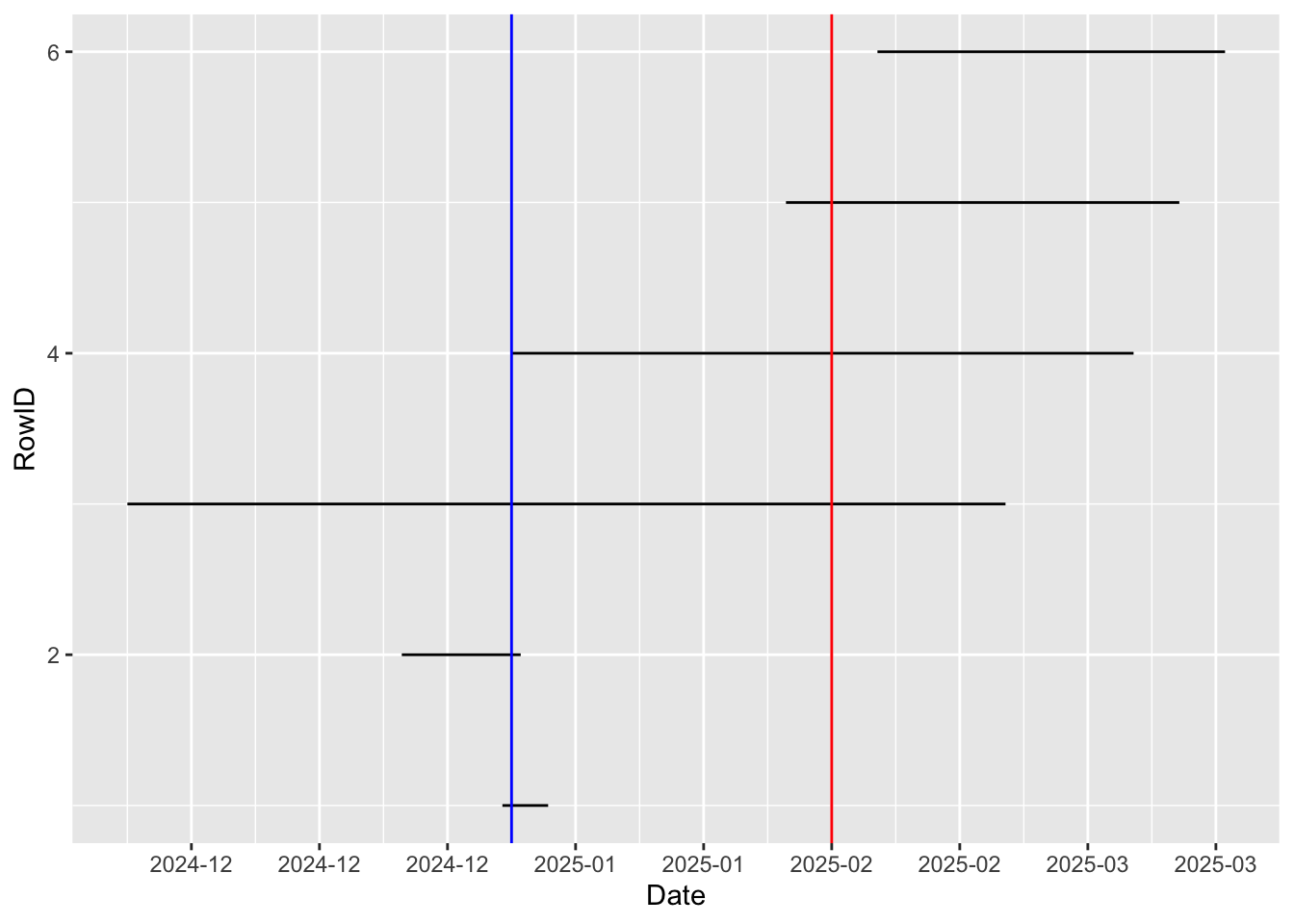
이 데이터프레임에서 2025년 1월 6일과 2025년 2월 10일 입원 환자가 어떻게 되는지 보려고 한다. 이 문제는 위 그래프에서 파란선과 빨간선이 교차하는 지점의 개수를 세는 것과 동일하다.
만약 위 데이터의 Y축이 한 환자가 복용하는 약물들의 ID라고 생각해 보자. 각 약물의 복용 기간을 알고 있다면 우리는 어느 시점에서 어떤 약물들을 복용했는지(몇 개을 복용했는지) 알 수 있을 것이다. 이런 문제를 해결하기 위해서 Interval 클래스를 사용한다.
각 환자의 입원 기간을 표현하는 Interval 클래스를 만든다. inteval(시작일, 마지막일) 함수를 사용하여 만든다.
# A tibble: 6 × 4
Id admission_date discharge_date admission_interval
<chr> <date> <date> <Interval>
1 p34 2025-01-05 2025-01-10 2025-01-05 UTC--2025-01-10 UTC
2 p64 2024-12-25 2025-01-07 2024-12-25 UTC--2025-01-07 UTC
3 p87 2024-11-25 2025-03-01 2024-11-25 UTC--2025-03-01 UTC
4 p79 2025-01-06 2025-03-15 2025-01-06 UTC--2025-03-15 UTC
5 p99 2025-02-05 2025-03-20 2025-02-05 UTC--2025-03-20 UTC
6 p100 2025-02-15 2025-03-25 2025-02-15 UTC--2025-03-25 UTCadmission_interval 열은 Interval 클래스이며, 각 환자의 입원일과 퇴원일 정보를 포함한다. 이런 객체들 사이에는 int_overlaps() 함수를 사용하여 두 기간이 겹치는지 확인할 수 있고, %within% 연산자를 사용하여 특정 날짜/시간 또는 interval 객체가 다른 interval 객체에 포함되는지 확인할 수 있다. 여기서는 이 연산자를 사용하려고 한다.
# 2025년 1월 6일 입원 환자 수
ad_df %>%
mutate(admission_interval = interval(admission_date, discharge_date)) %>%
filter(ymd("2025-01-06") %within% admission_interval) %>%
count()# A tibble: 1 × 1
n
<int>
1 4# 2025년 1월 8일 입원 환자 수
ad_df %>%
mutate(admission_interval = interval(admission_date, discharge_date)) %>%
filter(ymd("2025-02-10") %within% admission_interval) %>%
count()# A tibble: 1 × 1
n
<int>
1 3Interval 객체가 시작 시점과 끝 시점을 표현하는 클래스이기 때문에 두 객체의 차이(초 단위)를 계산할 수 있다.
ad_df %>%
mutate(admission_interval = interval(admission_date, discharge_date)) %>%
mutate(admission_interval_length = int_length(admission_interval)) %>%
select(Id, admission_interval_length)# A tibble: 6 × 2
Id admission_interval_length
<chr> <dbl>
1 p34 432000
2 p64 1123200
3 p87 8294400
4 p79 5875200
5 p99 3715200
6 p100 3283200평균 재원일(일 단위)을 계산해 보자. Duration 클래스를 as.numeric() 함수를 사용하여 숫자로 변환하는 과정을 거쳤다.
ad_df %>%
mutate(admission_interval = interval(admission_date, discharge_date)) %>%
mutate(admission_interval_length = int_length(admission_interval)) %>%
select(Id, admission_interval_length) %>%
summarise(StayDays = mean(admission_interval_length / as.numeric(ddays(1))))# A tibble: 1 × 1
StayDays
<dbl>
1 43.818.6.3 Period 클래스
Period 클래스는 사람들이 흔히 표현하는 기간을 표현하는 클래스이다. 예를 들어 윤년이냐 아니냐에 상관없이 2월 14일 1년후 날짜를 계산할 수 있다. 보통 4로 나누어 떨어지는 해를 윤년이라고 하는데, 이 경우에는 2월 29일이 있는 해이다.
# 1개월
dd + months(1) # 1개월 후[1] "2024-03-14" "2025-03-14"18.7 기타 날짜 등 계산
18.7.1 분기/계절/월의 첫 날 계산하기
floor_date() 함수는 날짜를 지정된 단위(“quarter”, “season”, “semester” 등)로 내림하여 해당 기간의 첫 날을 반환한다. 이 함수는 다음과 같은 단위를 지원한다.
- “year”: 연초
- “quarter”: 분기 초
- “month”: 월초
- “week”: 주초
- “day”: 일초
- “season”: 계절 초
- “halfyear”: 반기 초
# 분기 초
dates <- ymd(c("2024-01-15", "2024-05-20", "2024-08-10", "2024-12-25"))
floor_date(dates, "quarter")[1] "2024-01-01" "2024-04-01" "2024-07-01" "2024-10-01"# 계절 초
floor_date(dates, "season")[1] "2023-12-01" "2024-03-01" "2024-06-01" "2024-12-01"floor_date(dates, "halfyear")[1] "2024-01-01" "2024-01-01" "2024-07-01" "2024-07-01"floor_date(dates, "month")[1] "2024-01-01" "2024-05-01" "2024-08-01" "2024-12-01"18.7.2 연속된 날짜 데이터 생성하기
어떤 경우는 일정한 간격으로 날짜 데이터를 생성해야 할 필요가 있다. 예를 들어 2025년 1월 1일부터 2025년 12월 31일까지 주 단위로 날짜 데이터를 생성해야 할 필요가 있다. 이런 경우에는 seq() 함수를 사용하여 생성할 수 있다.
[1] "2025-01-01" "2025-01-08" "2025-01-15" "2025-01-22" "2025-01-29"
[6] "2025-02-05" "2025-02-12" "2025-02-19" "2025-02-26" "2025-03-05"
[11] "2025-03-12" "2025-03-19" "2025-03-26" "2025-04-02" "2025-04-09"
[16] "2025-04-16" "2025-04-23" "2025-04-30" "2025-05-07" "2025-05-14"
[21] "2025-05-21" "2025-05-28" "2025-06-04" "2025-06-11" "2025-06-18"
[26] "2025-06-25" "2025-07-02" "2025-07-09" "2025-07-16" "2025-07-23"
[31] "2025-07-30" "2025-08-06" "2025-08-13" "2025-08-20" "2025-08-27"
[36] "2025-09-03" "2025-09-10" "2025-09-17" "2025-09-24" "2025-10-01"
[41] "2025-10-08" "2025-10-15" "2025-10-22" "2025-10-29" "2025-11-05"
[46] "2025-11-12" "2025-11-19" "2025-11-26" "2025-12-03" "2025-12-10"
[51] "2025-12-17" "2025-12-24" "2025-12-31"3주 단위로 날짜 데이터를 생성해 보자.
[1] "2025-01-01" "2025-01-22" "2025-02-12" "2025-03-05" "2025-03-26"
[6] "2025-04-16" "2025-05-07" "2025-05-28" "2025-06-18" "2025-07-09"
[11] "2025-07-30" "2025-08-20" "2025-09-10" "2025-10-01" "2025-10-22"
[16] "2025-11-12" "2025-12-03" "2025-12-24"1개월 단위로 날짜 데이터를 생성해 보자.
18.8 정리
이 장에서는 날짜/시간 데이터를 처리하는 방법을 설명했다.