R 언어의 핵심을 구성하는 base R은 크기도 얼마되지 않는다. 반면 여러 용도로 개발된 수많은 패키지들이 있어 효용성이 증폭된다. R의 이러한 organic한 특성은 다양한 방법으로 확장되는 장점이 있는 반면, 일관성이라는 부분에서는 취약하다.
R tidyverse는 tidy data라는 일관된 철학을 바탕으로 개발된 여러 패키지들을 일컫는 패키지로, 패키지들을 모은 일종의 메타패키지이다. 이 패키지들은 데이터 과학 작업 흐름 전반에 걸쳐 다양하게 사용되며, 나머지 R 세계에도 지대한 영향을 미쳤다. 초기 개념은 해들리 위캄의 Tidy Data(Wickham 2014)이라는 article에서 찾을 수 있다.
위 논문에서 소개된 핵심 내용은 바뀌지 않았지만, 도구는 많이 바뀌었다. 현대판 설명문은 tidyr 패키지에 포함된 비니에트는 Tidy data에 나와 있으므로, 이것을 번역하여 같이 읽어보고자 한다. 다음은 비니에트의 번역이다.
9.0.1 Data Tidying
데이터 분석의 80%는 data cleaning을 통해 데이터를 정리하는 데 사용된다. 그럼에도 불구하여 아직 이 분야에 대한 연구가 잘 되어 있지 않았다. 저자는 이런 측면의 일부를 논의하려고 하는데, 분석을 촉진시킬 수 있도록 데이터를 구조화하는 방법이고, 이것을 “data tidying”라고 부르려 한다.
tidy data 원리는 데이터 안에서 데이터를 재구성하는 표준화된 방법을 제시한다. 이런 표준을 통해서 사용자들은 새로운 것을 다시 만들고, 새로 시작하거나 하는 등의 수고를 덜 수 있다. tidy dataset와 tidy data tools의 조합으로 데이터 분석을 쉽게 할 수 있다.
9.0.2 Defining tidy data
레오 톨스토이는 “행복한 집안은 대체로 비슷한다. 반대로 불행한 집안은 각자의 방식으로 불행하다.”라고 했다.
가족 문제처럼, 정돈된 데이터셋은 모두 비슷한데, 정돈되지 않은 모든 데이터셋은 각자의 방식으로 문제가 있다. Tidy dataset은 데이터긔 구조와 믜미를 연결하는 표준적인 방법을 제공한다.
9.0.2.1 Data structure
대부분의 통계 데이터셋은 행(rows)과 열(columns)로 구성된 데이터프레임이다. 열은 항상 레이블이 있고, 행은 레이블이 있는 경우도 있고, 없는 경우도 있다. 같은 데이터셋이라고 해도 여러 가지 방식으로 다른 레이아웃을 취할 수 있다.
# A tibble: 3 × 5
assessment Billy Suzy Lionel Jenny
<chr> <chr> <chr> <chr> <chr>
1 quiz1 <NA> F B A
2 quiz2 D <NA> C A
3 test1 C <NA> B B
같은 데이터이지만 레이아웃은 다르다. 왜 이 두 테이블이 같은 데이터인지를 설명하기에 충분한 행과 열에 대한 개념적인 단어가 충분하지 않다. 겉보기에 더해서, 우리는 테이블에 표시되는 값들의 의미론(semamantic, 의미)을 기술할 수 있는 방법이 필요하다.
9.0.2.2 Data Semantics
중요
하나의 데이터셋은 값(values)의 집합이고, 그 값들은 숫자(양적인 경우) 또는 문자열(질적인 경우)이다. 값은 두 가지 방향으로 구성되는데, 하나의 값은 하나의 변수(variable)와 하나의 관측(observation)에 속한다. 변수는 전체 관측 단위(observational units)에 대하여 키, 온도, 기간과 같은 똑같은 속성에 대한 측정값을 가진다. 하나이 관측(observation)은 하나의 관측 대상에 대하여 모든 속성에 대한 값을 가진다(한 사람, 하루, 하나의 경주 등).
# A tibble: 12 × 3
name assessment grade
<chr> <chr> <chr>
1 Billy quiz1 <NA>
2 Billy quiz2 D
3 Billy test1 C
4 Jenny quiz1 A
5 Jenny quiz2 A
6 Jenny test1 B
7 Lionel quiz1 B
8 Lionel quiz2 C
9 Lionel test1 B
10 Suzy quiz1 F
11 Suzy quiz2 <NA>
12 Suzy test1 <NA>
이렇게 하면 값, 변수, 관측이 좀 더 명확해진다. 이 데이터셋은 3개의 변수와 12개의 관측을 가진 총 36개의 값을 포함한다. 그 변수는 다음과 같다.
name: 4개의 가능한 값
assessment: 3개의 가능한 값
grade: 결측값을 어떻게 취급하지에 따라 5 또는 6개의 값
tidy 데이터프레임은 하나의 관측이 무엇을 의미하는지 명확하게 말해준다. 이 경우 이름(name)과 평가(assessment)의 모든 조합이 단 하나의 측정된 관측을 의미한다.
데이터셋은 결측값이 무엇을 의미하는지에 대한 정보도 제공한다. 그것이 가능하진지, 어떤 의미를 갖는지를 말이다. 예를 들어 Billy는 첫 번째 퀴즈에 불참했는데, 점수를 만회하기 위해서 노력한 것으로 보인다. Suzy는 첫 번째 퀴즈에서 낙방해서 수업을 듣지 않기로 결정했다. Billy의 최종 점수를 계산하려면 우리는 결측값에 F로 채워야할 수도 있다(아니면 그가 두 번째 퀴즈를 볼 기회를 얻을 수도 있다). 그렇지만, 만약 우리가 이 수업의 Test 1에 평균을 구하고자 할 때는 Suzy의 구조적인 결측값은 적절한 새로운 값으로 대처하는(impute) 대신 이 값을 제외하는 것이 바람직할 수도 있다.
주어진 데이터셋에서 어떤 것이 관측이고 어떤 것이 변수인지 구분하는 것은 쉽다. 하지만 일반적으로 변수와 관측을 정확하게 정의하는 것은 놀랍도록 어렵다.
Table 1의 열이 height, weight라면 우리는 쉽게 이것을 변수라고 부를 것이다. 그런데 이것이 dimension(차원) 변수의 값들이라면 어떻게 처리해야 할까?
……중략
어떤 경우에는 관측에서 복수의 레벨이 존재할 수 있다. 새로운 알러지 약물 임상 시험인 경우 3 종류의 관측 형태가 존재할 수 있다. 개인에 대한 인구학적 특성 데이터(age, sex, race), 각 환자에서 매일 측정되는 의학 데이터((number of sneeze, rendness of eye), 매일 측정되는 기상학적 데이터(temperatoure, pollen count) 등이 있다
변수들은 분석이 진행되면서 바뀔 수 있다. 종종 원 데이터의 변수들은 매우 세밀하게 쪼개져 있어서, 모델 설명에 대한 이득은 거의 없으면서 복잡성만 더 부여할 수도 있다. 예를 들어, 많은 설문지들은 내재된 특성을 더 잘 파악하기 위해서 같은 질문을 반복하곤 한다. 분석 초기 단계에서는 변수들이 질문에 대응한다. 나중에 가면, 분석자는 여러 질문들을 합계한 평균을 계산한 특성들에 초점을 맞출 수도 있다. 이렇게 하면 hierachical model을 필요로 하지 않기 때문에 분석을 간편하게 만든다. 어떤 경우 이산값이 아니라 연속형인 것처럼 다루기도 한다.
9.0.3 Tidy data
Tidy data는 데이터셋에 내장된 의미를 그것의 구조에 매핑하는 표준적인 방법을 말한다. 행, 열, 테이블이 관측, 변수, 관측 타입과 어떻게 매칭되는지에 따라 messy인지 tidy인지 결정된다. Tidy data는 다음과 같은 특성을 가진다.
하나의 변수는 하나의 열을 구성한다.
하나의 관측은 하나의 행을 구성한다.
관측 단위의 각 형태는 하나의 테이블을 구성한다.
이것은 Codd가 말한 3rd normal form인데, 이것을 통계학적인 언어로 재설정한 것으로, 관계형 데이터베애스에서 흔히 보는 여러 연결된 데이터셋이 아니라 단 하나의 데이터셋에 초점을 주는 점이 다르다. Messy data란 이 규칙에 어긋나는 것을 말한다.
Tidy data는 데이터셋을 구성하는 표준적인 방법을 제공하기 때문에 컴퓨터가 필요한 변수를 추출하는 것을 쉽게 해 준다. Table 3을 Table 1과 비교해 보자. Table 1을 사용한다면 서로 다른 변수를 추출하기 위해서 여러 전략들을 구사해야 한다. 이렇게 하다 보면 분석이 느려지고 오류가 생긴다.
실험 설계에 따라 fixed variable들이 먼저, measured variables들은 뒤에 두는 것이 일반적이다.
9.0.4 Tidying messy datasets
실제 데이터들은 tidy data가 갖춰야 하는 3가지 규칙을 갖가지 방법으로 종종 어긴다. 바로 분석에 사용할 수 있는 데이터셋을 접하는 경우보다는 그렇지 않은 경우가 대부분이다. 이 절에서는 messy dataset의 가장 흔하게 발견되는 5가지 패턴과 수정하는 방법을 설명하고자 한다. 5가지 경우는 다음과 같다.
열 헤더에 변수 이름이 아닌 값이 들어가는 경우
여러 개의 변수들이 하나의 열에 저장되는 경우
변수가 행과 열에 함께 저장되는 경우
다양한 형태의 관측 단위가 같은 테이블로 저장되는 경우
하나의 관측 단위가 여러 개의 테이블에 저장되는 경우
놀랍게도, 대부분 messy datasets은 몇 가지 도구 집합을 가지고도 쉽게 정렬할 수 있다. 도구는 Pivoting(longer and wider)과 Separtint이다. 다음 절에서 실제 messy 데이터셋을 보여주고, 이것을 정리하는 방법을 설명하려고 한다.
9.0.4.1 열 헤더에 변수 이름이 아닌 값이 들어가는 경우
흔히 볼 수 있는 messy dataset 가운데 하나는 주로 발표를 위해 만들어진 테이블로, 변수가 행과 열을 구성하고 있고, 열 이름이 변수 이름이 아닌 값으로 구성된 경우이다. 내가 이런 배치를 messy라고 부르지만, 어떤 경우에는 이런 방식이 극도로 유용하다. 특히 완전 교차(crossed) 설계를 가진 경우 효율적인 저장법을 제공하고, 원하는 연산들을 행렬 연산으로 표현할 수 있는 경우 매우 효율적이 된다.
노트
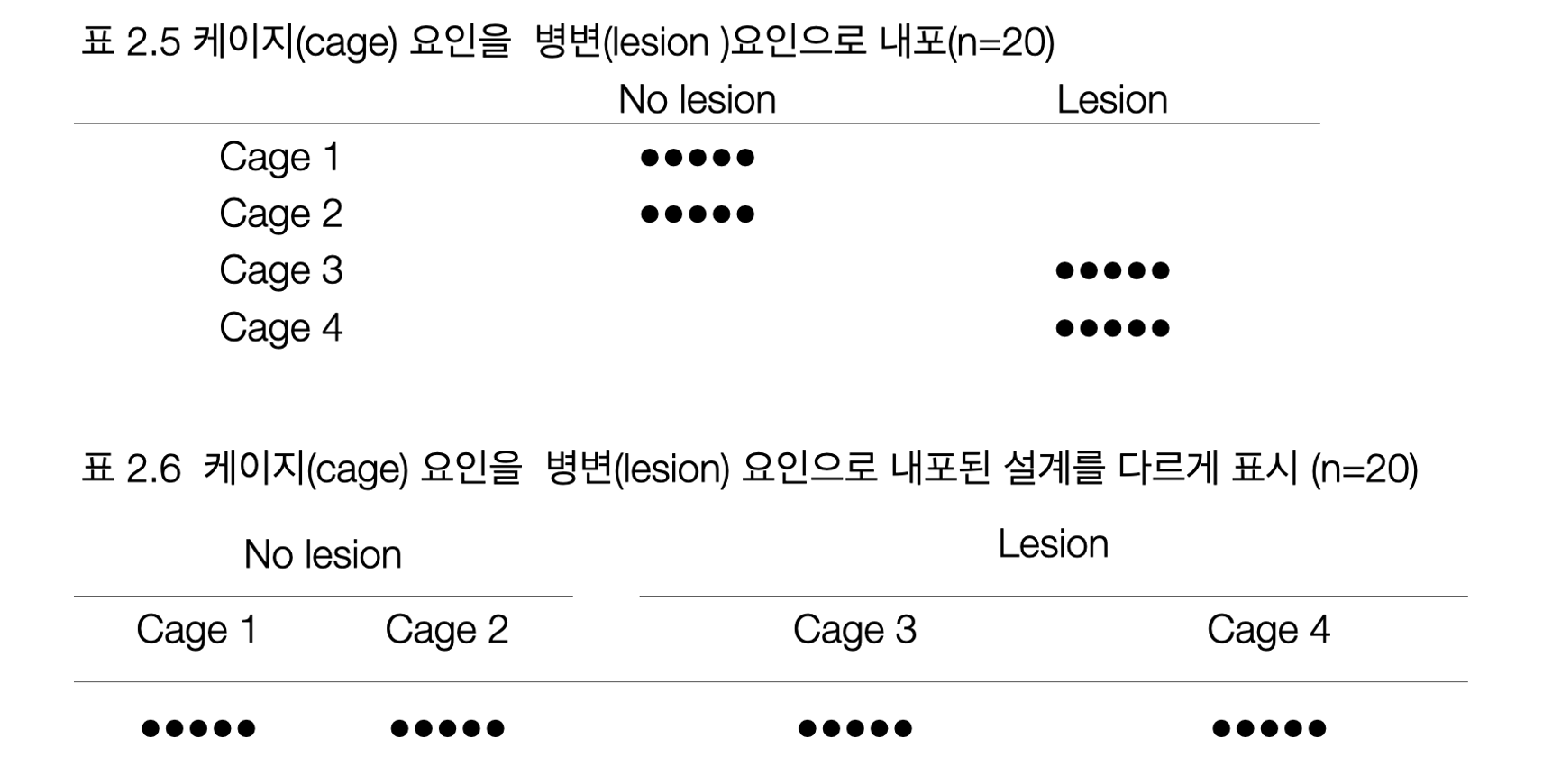
요인 배치 방법의 하나: Crossed(교차) vs Nested(내포)
표 2.4는 두 요인을 교차한 실험이다. 점(‘•’)으로 표시한 20마리의 랫들은 랜덤한 방법으로 병변을 받거가 받지 않도록 할당하고, 다시 약물을 투여하거나 투여받지 않은 군으로 구분한다. 이 경우 요인들은 요인의 모든 수준을 조합한 경우에 대하여 관찰되므로 교차(crossed)되었다고 말한다.
교차와 반대되는 개념: Nested(내포)
요인이 내포되지도 교차되지도 않을 때 중첩되었다(confounded)고 말한다.
다음 코드는 이런 유형의 전형을 보여준다. 이 표는 퓨 리서치 센터의 자료로, 미국에서 종교와 수입 사이의 관계를 연구한 데이터셋이다.
이 데이터셋은 religion, income, frequency라는 세 변수를 가지고 있다. 이 데이터셋을 정리하기 위해서, 우리는 변수 역할을 하지는 않는 열들을 피벗팅하여 키-값 쌍을 구성하는 2개이 열로 피벗팅할 필요가 있다. 이런 작업을 종종 넓은(wide) 데이터셋을 긴(long or tall) 데이터셋으로 바꾼다라고 말한다.
변수들을 피벗팅할 때, 우리는 새롭게 만들 키-값 열에 대한 이름을 줄 필요가 있다. 피벗에 사용할 열들을 정의하고 나서(이 경우 religion을 제외한 모든 열), 키가 되는 열에 이름을 줄 필요가 있는데 이것은 열 헤더의 값들에 의해서 정의되는 변수의 이름이다. 이 경우에는 income이라고 했다. 두 번재는 값 열에 대한 이름으로 frequency롤 정했다.
이렇게 변형된 데이터셋은 tidy dataset이라고 할 수 있다. 왜냐하면 각 열이 하나의 변수를, 각 행이 하나의 관측을 나타내기 때문이다. 이 경우 하나의 관측이란 religion과 income 조합으로 이뤄지는 하나의 인구학적 단위를 의미한다.
여기서 설명하는 데이터폼은 시간 흐름에 따라 일정한 간격으로 값을 기록하는데도 사용될 수 있다. 예를 들어, 아래 빌보드 데이터셋은 톱 100에 처음으로 등재된 날을 보여준다. 각 주별 순위는 75개의 열로 기록했고 wk1에서 wk75까지 열이 그것이다. 이런 형태는 tidy 하지 않지만 데이터 수집/입력에서는 유용하다. 이렇게 하면 하나의 노래가 하나의 행만을 차지하기 때문이다.(일부 번역 생략)
이제 열들을 피봇팅하고 나면, 종종 키가 되는 열은 여러 개 변수 이름의 조합이 되는 경우가 있다. 무슨 뜻인고 하니 아래 tb 결핵 데이터셋에서 이런 현상이 나타난다. 이 데이터셋은 세계보건기구의 데이터로 여러 국가에서 결핵 발생을 기록한 것이다. 인구 그룹을 성(m, f)과 나이 조합(0-14, 15-25, 25-34, 35-44, 45-54, 55-64, unknown)으로 나눠서 정리했다.
# tidyr github 사이트에 있는 tb.csv를 읽도록 코드를 변경함tb<-as_tibble(read.csv("https://raw.githubusercontent.com/tidyverse/tidyr/refs/heads/main/vignettes/tb.csv", stringsAsFactors =FALSE))tb
# A tibble: 5,769 × 22
iso2 year m04 m514 m014 m1524 m2534 m3544 m4554 m5564 m65 mu f04
<chr> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 AD 1989 NA NA NA NA NA NA NA NA NA NA NA
2 AD 1990 NA NA NA NA NA NA NA NA NA NA NA
3 AD 1991 NA NA NA NA NA NA NA NA NA NA NA
4 AD 1992 NA NA NA NA NA NA NA NA NA NA NA
5 AD 1993 NA NA NA NA NA NA NA NA NA NA NA
6 AD 1994 NA NA NA NA NA NA NA NA NA NA NA
7 AD 1996 NA NA 0 0 0 4 1 0 0 NA NA
8 AD 1997 NA NA 0 0 1 2 2 1 6 NA NA
9 AD 1998 NA NA 0 0 0 1 0 0 0 NA NA
10 AD 1999 NA NA 0 0 0 1 1 0 0 NA NA
# ℹ 5,759 more rows
# ℹ 9 more variables: f514 <int>, f014 <int>, f1524 <int>, f2534 <int>,
# f3544 <int>, f4554 <int>, f5564 <int>, f65 <int>, fu <int>
# A tibble: 35,750 × 4
iso2 year demo n
<chr> <int> <chr> <int>
1 AD 1996 m014 0
2 AD 1996 m1524 0
3 AD 1996 m2534 0
4 AD 1996 m3544 4
5 AD 1996 m4554 1
6 AD 1996 m5564 0
7 AD 1996 m65 0
8 AD 1996 f014 0
9 AD 1996 f1524 1
10 AD 1996 f2534 1
# ℹ 35,740 more rows
이런 형태의 데이터셋들은 종종 특수한 문자(예를 들어, 하이픈, 언더스코어, 콜론 등)로 구분되는 열 이름을 가지거나 이 경우처럼 고정된 폭을 가지는 경우가 많다. separate() 함수는 복합 변수를 개별 변수로 분리하는 데 사용된다. 값의 분리를 위해 정규 표현식(regular expression)을 사용할 수도 있고, 디폴트로 이와 같은 비-알파벳-또는-숫자로 나누도록 설정되어 있다. 또는 어떤 문자의 위치를 벡터로 지정할 수 있다. 이 경우에는 첫 번재 문자 바로 다음을 기준으로 쪼개도록 한다.
# A tibble: 35,750 × 5
iso2 year sex age n
<chr> <int> <chr> <chr> <int>
1 AD 1996 m 014 0
2 AD 1996 m 1524 0
3 AD 1996 m 2534 0
4 AD 1996 m 3544 4
5 AD 1996 m 4554 1
6 AD 1996 m 5564 0
7 AD 1996 m 65 0
8 AD 1996 f 014 0
9 AD 1996 f 1524 1
10 AD 1996 f 2534 1
# ℹ 35,740 more rows
이렇게 해 놓으면 전체 인구수 population을 결합시킨 발생률을 계산하기도 편리하다. 원래의 표에는 값이 들어갈 열이 없다.
# A tibble: 35,750 × 5
iso2 year sex age n
<chr> <int> <chr> <chr> <int>
1 AD 1996 m 014 0
2 AD 1996 m 1524 0
3 AD 1996 m 2534 0
4 AD 1996 m 3544 4
5 AD 1996 m 4554 1
6 AD 1996 m 5564 0
7 AD 1996 m 65 0
8 AD 1996 f 014 0
9 AD 1996 f 1524 1
10 AD 1996 f 2534 1
# ℹ 35,740 more rows
9.0.4.3 변수가 행과 열에 함께 저장되는 경우
Messy data에서 가장 복잡한 형태는 변수들이 행고 열 모두에 저장되는 경우이다. 아래 데이터셋은 2010년 멕스코의 어느 기상 센터에서 수집된 날씨 정보로 Global Historical Climatology Network에서 가져왔다.
# A tibble: 22 × 35
id year month element d1 d2 d3 d4 d5 d6 d7 d8
<chr> <int> <int> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 MX17004 2010 1 tmax NA NA NA NA NA NA NA NA
2 MX17004 2010 1 tmin NA NA NA NA NA NA NA NA
3 MX17004 2010 2 tmax NA 27.3 24.1 NA NA NA NA NA
4 MX17004 2010 2 tmin NA 14.4 14.4 NA NA NA NA NA
5 MX17004 2010 3 tmax NA NA NA NA 32.1 NA NA NA
6 MX17004 2010 3 tmin NA NA NA NA 14.2 NA NA NA
7 MX17004 2010 4 tmax NA NA NA NA NA NA NA NA
8 MX17004 2010 4 tmin NA NA NA NA NA NA NA NA
9 MX17004 2010 5 tmax NA NA NA NA NA NA NA NA
10 MX17004 2010 5 tmin NA NA NA NA NA NA NA NA
# ℹ 12 more rows
# ℹ 23 more variables: d9 <lgl>, d10 <dbl>, d11 <dbl>, d12 <lgl>, d13 <dbl>,
# d14 <dbl>, d15 <dbl>, d16 <dbl>, d17 <dbl>, d18 <lgl>, d19 <lgl>,
# d20 <lgl>, d21 <lgl>, d22 <lgl>, d23 <dbl>, d24 <lgl>, d25 <dbl>,
# d26 <dbl>, d27 <dbl>, d28 <dbl>, d29 <dbl>, d30 <dbl>, d31 <dbl>
이 데이터셋에는 변수가 id, year, month와 같이 개별 열에, d1-d31로 된 것과 같이 여러 열들에, tmin, tmax 처럼 행에 걸쳐 존재한다. 31일을 채우지 못하는 달은 마지막 날 이후 구조적인 결측값을 가진다.
이 데이터셋은 거의 정돈되어 가고 있으나, element 열은 아직 하나의 변수가 아니다. 이 열은 변수들의 이름을 저장하고 있다. 이 문제를 해결하기 위해서는 데이터를 넓게 만드는 pivot_wider() 함수가 필요하다. 이 함수는 pivot_longer()와 정반대의 일을 해서, element를 피벗팅하여 그 값들을 여러 행으로 펼친다.
데이터셋들은 종종 여러 수준에서 또는 서로 다른 관측 단위에서 수집되기도 한다. Tidying할 때는 각각의 관측 단위는 서로 다른 테이블에 저장되어야 한다. 이것은 각각의 팩트는 단 한 곳에서 표현되어 한다는 데이터베이스 정규화와 밀접하게 연관되어 있다. 이렇게 하지 않으면 불-일관성이 발생할 수 있기 때문이다,
앞에서 본 빌보드 데이터셋은 실제로 두 종류의 관측 단위를 가지고 있다. 노래와 그 노래의 주별 순위이다. 아티스트의 이름이 여러 번 반복되는 것을 통해서도 이게 드러난다.
이 데이터셋을 아티스트와 곡명을 저장하는 노래 데이터셋과 주별 해당 곡의 순위를 나타내는 랭킹 데이터셋으로 나눠보자. 먼저 song 데이테셋을 추출하자.
우리는 음반 판매량과 같은 “인구학적” 정보 비슷한 내용을 담은 해당 주에 대한 배경 정보를 포함하는 한 주의 데이터셋도 생각해 볼 수 있겠다.
정규화(normalization)은 데이터 정돈에 유용하고 일관성이 흩트러지는 것을 막는다. 그런데 관계형 데이터를 직접 다룰 수 있는 데이터 분석 도구들은 흔하지 않가여, 분석을 할 때 정규화 해제(denormalization) 또는 데이터셋의 머징을 통해 하나의 테이블으로 만들 필요가 생긴다.
9.0.4.5 하나의 관측 단위가 여러 개의 테이블에 저장되는 경우
단 한 종류의 관측 단위에 대한 데이터가 여러 개의 표나 파일로 나눠져 있는 경우도 흔하다. 이런 테이블이나 파일들은 또다른 변수에 의해서 분리되는 경우도 많다. 특정 연도, 특정 사람, 특정 위치에 대한 정보만을 담을 수 있다. 모두 같은 포맷으로 되어 있다면, 이 문제를 해결하는 것은 쉽다.
파일들을 하나의 테이블 리스트로 읽는다.
각 테이블에 대하여, 원본 파일 이름을 저장할 새로운 열을 추가한다(보통 파일 이름이 중요한 변수가 되기도 한다).
모든 테이블의 결합하여 하나의 테이블을 만든다.
R purrr 패키지는 R로 이런 일을 하는데 안성맞춤이다. 다음 (가상) 코드는 data 디렉터리에 있는 .csv 확장자를 가지는 파일들을 하나의 벡터로 구성한다. 그런 다음 벡터의 요소마다 파일의 이름을 가져다 붙인다. 이렇게 하는 이유는 최종 데이터프레임의 각 행들이 원 소스에 따라 레이블이 붙여지도록 하기 위함이다. 마지막 map() 함수를 통한 루프를 사용하여 paths에 있는 요소마다 read_csv가 실행되고, 그 결과들이 list_rbind() 함수를 통해서 하나의 데이터프레임으로 만들어진다.