여기서는 회귀(regression)의 원리 중 하나인 최소제곱법(least squares)에 대해 설명한다. 최소제곱법은 주어진 데이터에 가장 잘 맞는 직선(또는 곡선)을 찾는 방법으로 아주 널리 사용되고 역사도 깊다.
선형 회귀는 통계학에서 반응 변수(response variable)와 설명 변수들(explanatory variables) 사이의 관계를 모델링하는 방법으로, 반응 변수가 연속 변수인 경우에 사용되는 방법이다. 선형 회귀는 반응 변수와 설명 변수 사이의 선형 관계를 가정하고, 이 관계를 수학적으로 표현하는 방법이다.
반응 변수가 하나이고 설명 변수 역시 하나인 경우를 단순 선형 회귀(simple linear regression)라고 하며, 반응 변수가 하나이고 설명 변수가 여러 개인 경우를 다중 선형 회귀(multiple linear regression)라고 한다.
여기선 가장 간단한 단순 선형 회귀(simple linear regression) 방법과 회귀에 관련된 용어들을 설명하고자 한다.
로지스틱 회귀는 회귀(regression)가 아니다.
로지스틱 회귀(logistic regression)는 반응 변수가 범주형(categorical)인 경우에 사용되는 방법으로, 선형 회귀와는 다른 방법이다. 로지스틱 회귀는 반응 변수가 범주형일 때, 그 범주를 예측하는 방법으로, 확률을 모델링하는 데 사용된다. 따라서 로지스틱 회귀는 선형 회귀와는 다른 방법이다. 최근에는 머신러닝/딥러닝 분야에서는 다음과 같이 용어를 사용하는 경향이 있다.
회귀(regression): 반응 변수가 연속형인 경우
분류(classification): 반응 변수가 범주형인 경우
38.1 데이터와 그래프
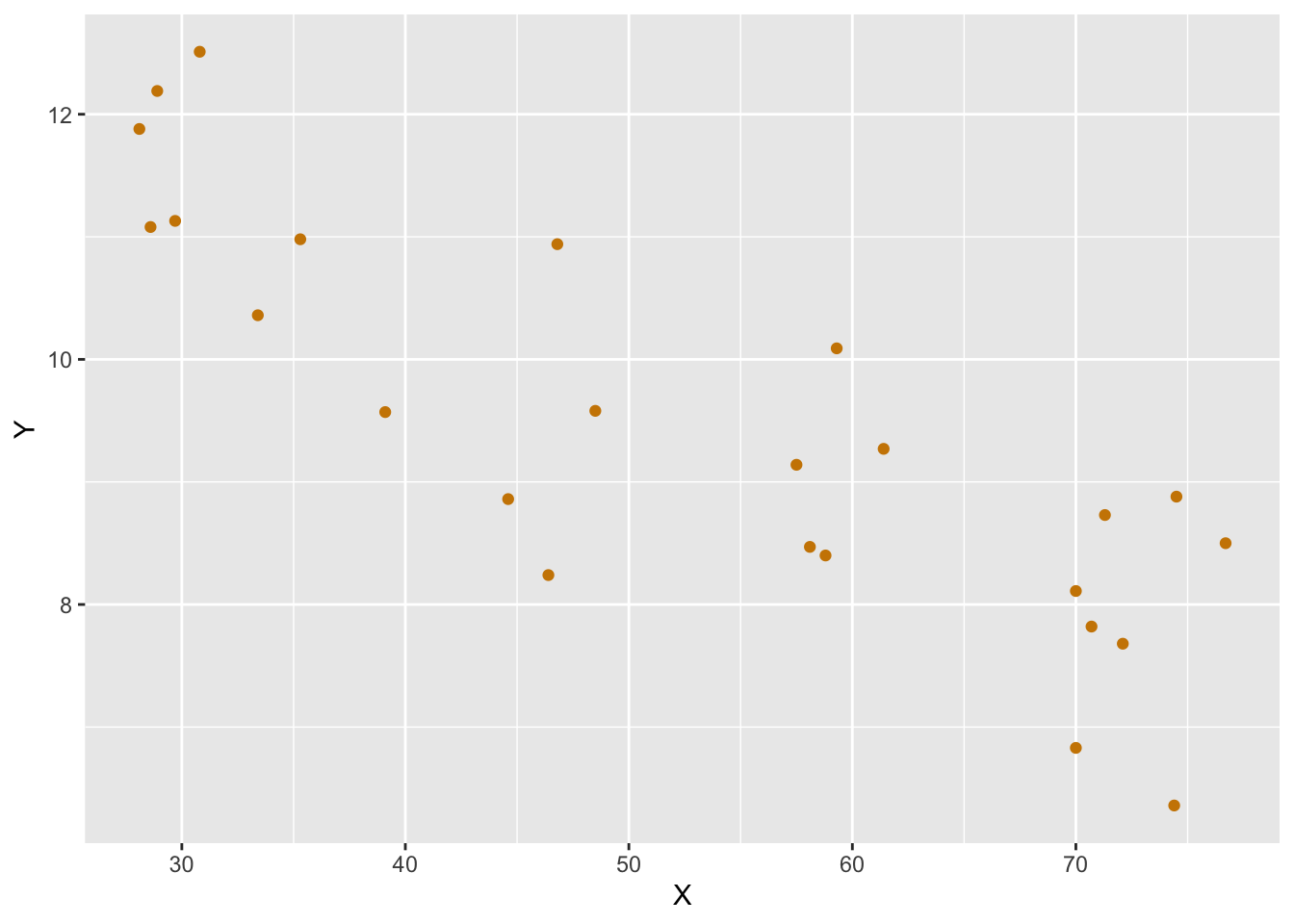
다음과 같은 데이터가 있다고 가정하자. 이 데이터는 설명 변수 \(X\)와 반응 변수 \(Y\)로 이루어져 있다. 이 데이터를 사용하여 단순 선형 회귀를 수행할 것이다(Draper and Smith 1998).
이 데이터는 \(X\)와 \(Y\)의 관측값(observation)으로 이루어져 있다. \(X\)는 설명 변수이고, \(Y\)는 반응 변수이다. 이 데이터를 사용하여 단순 선형 회귀를 수행할 것이다. 여기서는 최소제곱법(least squares)을 사용하여 회귀선을 찾는 방법을 설명할 것인데, 이 방법으로만 선형 회귀를 수행하는 것은 아니다. 다른 여러 가지 방법들이 있다.
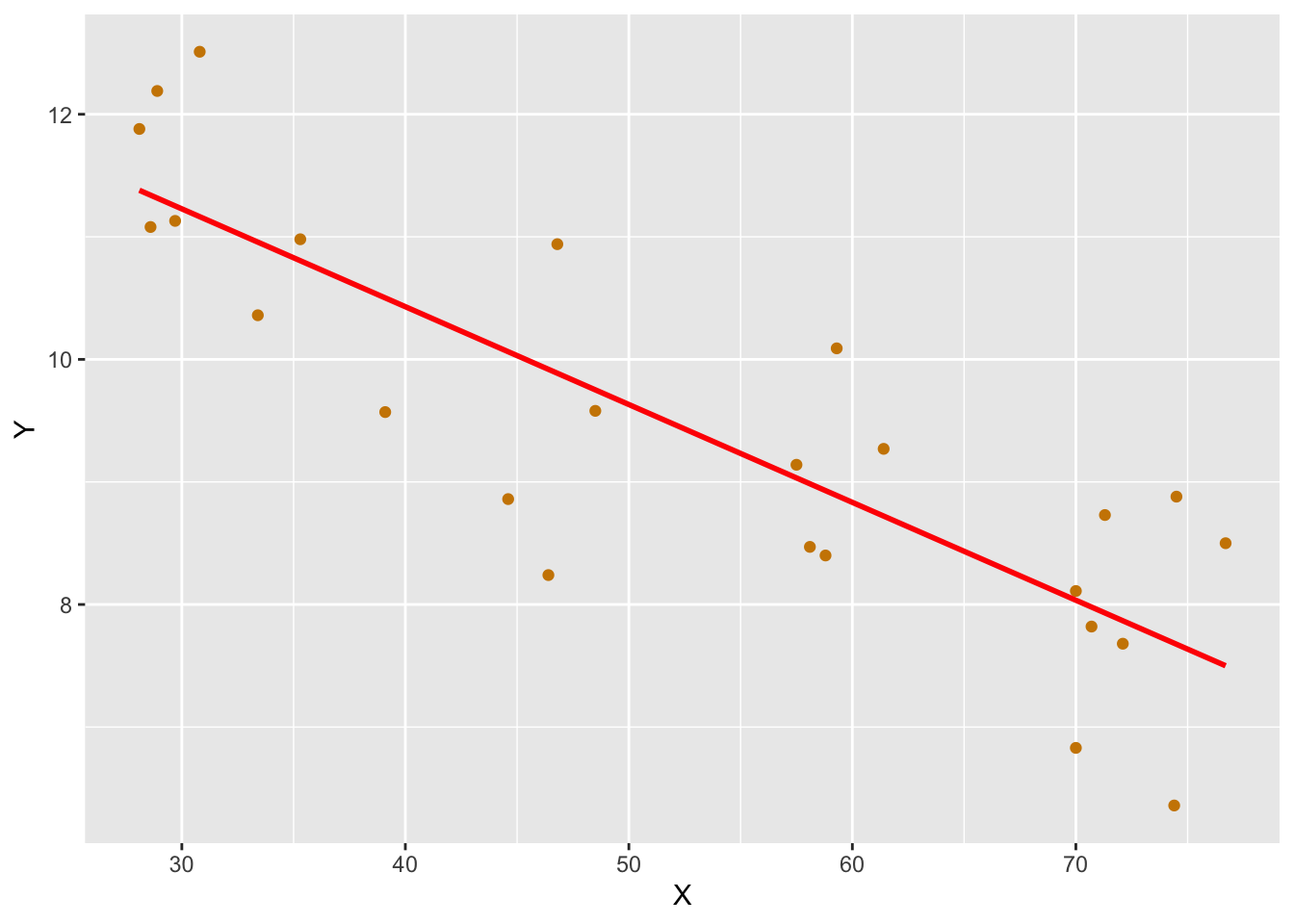
38.2 최소제곱법을 사용한 단순 선형 회귀
설명 변수 \(X\)와 반응 변수 \(Y\)가 있을 때, 다음과 같은 단순 선형 모델을 가정한다.
\[
Y = \beta_0 + \beta_1 X + \epsilon
\tag{38.1}\]
여기서 \(\beta_0\)는 절편(intercept), \(\beta_1\)은 기울기(slope)이며 이것들을 합쳐 모델의 파라미터(parameter)라고 부른다. \(\epsilon\)은 오차항(error term)으로, 모델이 설명하지 못하는 부분을 나타낸다.
수식을 한번 구경하는 것은 나쁘지 않다.
베이스 R에서는 lm() 함수를 사용하여 회귀 분석을 바로 할 수 있다. 최소제곱법의 원리를 개념적으로 이해하는 것은 중요하다. 이 개념을 알면 머신러닝/딥러닝 등 최신 기술을 이해하는 데도 도움이 많이 된다.
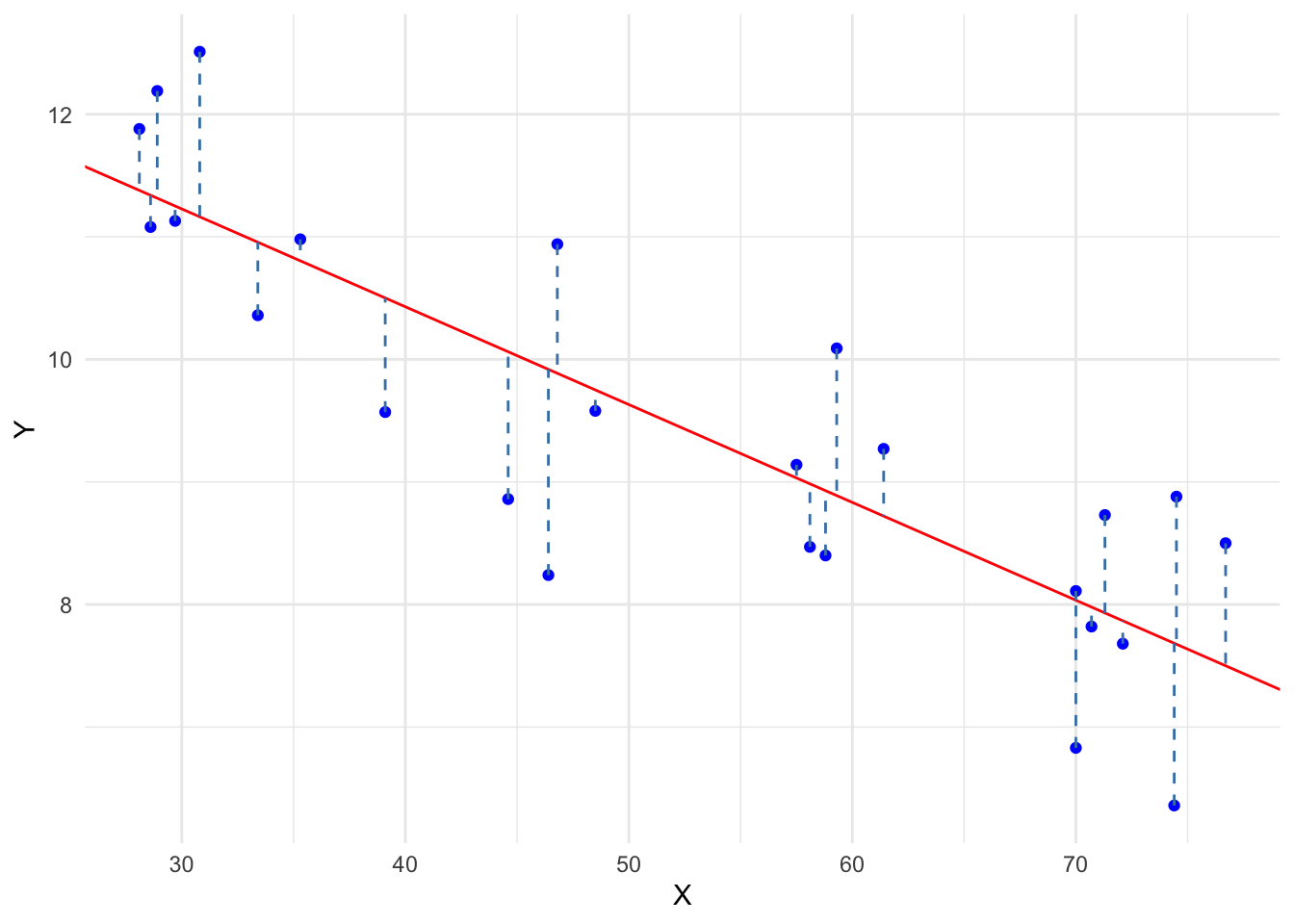
관측값의 쌍을 \((X_1, Y_1)\), \((X_2, Y_2)\), …, \((X_n, Y_n)\)이라고 하면 다음과 같이 쓸 수 있다.
이 오차항의 제곱합은 다음과 같이 쓸 수 있다. \[
S = \sum_{i=1}^{n} \epsilon_i^2 = \sum_{i=1}^{n} (Y_i - (\beta_0 + \beta_1 X_i))^2
\tag{38.4}\]
제곱하여 합하는 이유
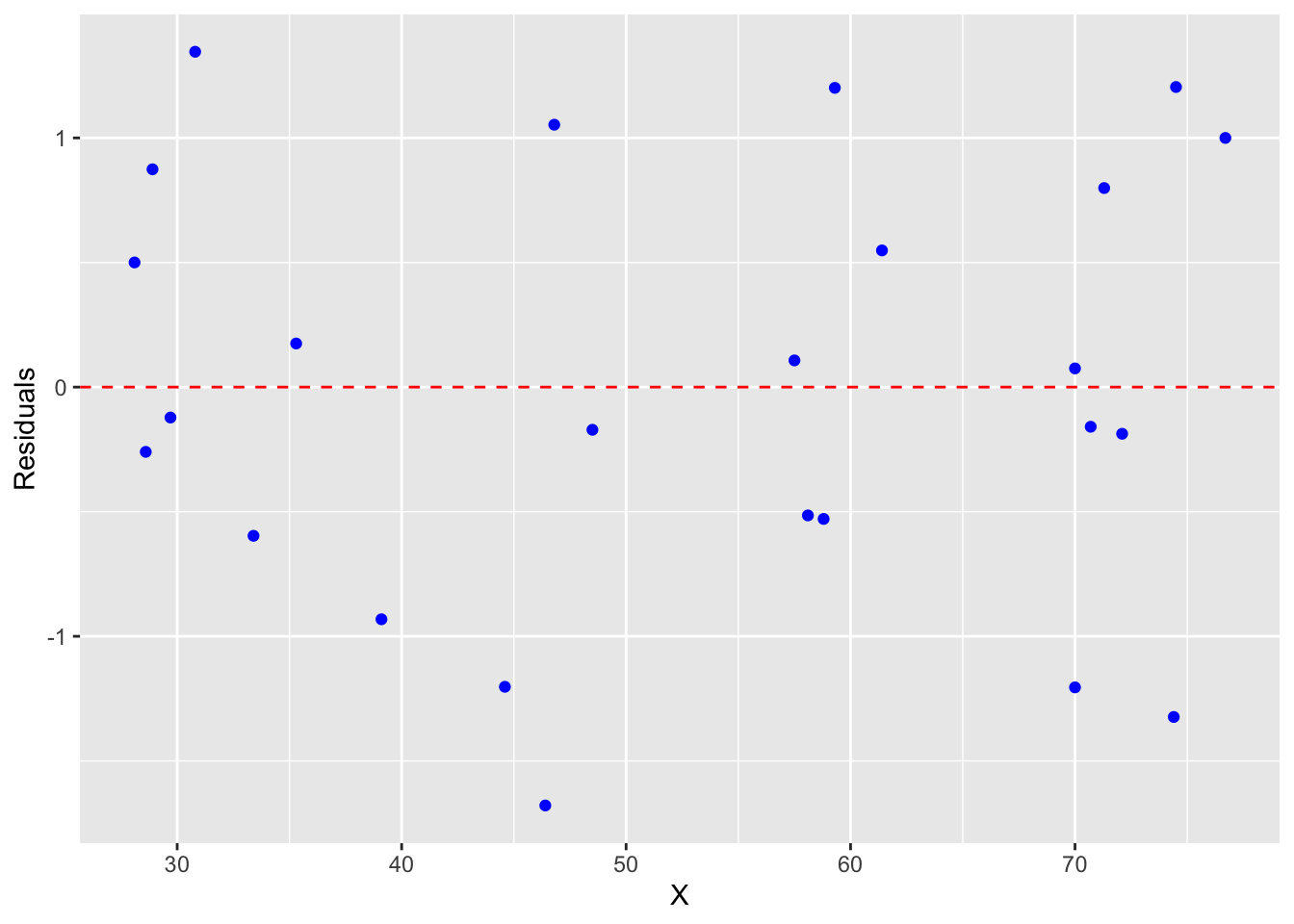
오차항을 제곱하여 합하는 이유는 오차의 부호(sign)에 관계없이 오차의 크기를 반영하기 위함이기도 하고, 제곱을 하기 때문에 오차가 큰 경우 더 큰 패널티를 주기 위함이기도 하다. 또한, 제곱을 하면 오차항이 서로 상쇄되는 것을 방지할 수 있다. 만약 오차항을 단순히 합한다면, 양수와 음수가 서로 상쇄되어 오차가 작게 나타날 수 있다.
이제 이 식을 \(\beta_0\)와 \(\beta_1\)에 대해 최소화해야 한다. (함수의 최솟값을 구했던 것을 상기하자.) 이를 위해 편미분(partial derivative)을 사용하여 각각의 파라미터에 대한 최적 조건을 구한다. 즉, 편미분을 통해 각 파라미터에 대한 기울기를 구하고, 이를 0으로 설정하여 최적의 파라미터 값을 찾는다.
편미분
편미분(partial derivative)은 다변수 함수에서 특정 변수에 대한 변화율을 구하는 방법이다. 예를 들어, 함수 \(f(x, y)\)의 \(x\)에 대한 편미분은 \(y\)를 상수로 간주하고 \(x\)에 대한 변화율을 구하는 것이다. \(f(x, y)\)의 \(x\)에 대한 편미분은 \(\frac{\partial f}{\partial x}\)로 표기한다. 또한 \(y\)에 대한 편미분은 \(x\)를 상수로 놓고 변화율을 구하고, \(\frac{\partial f}{\partial y}\)로 표기한다.
\(\beta_0\)에 대한 편미분을 실행하여, 그 값을 0으로 설정하면 다음과 같은 식을 얻는다.
F-검정은 자유도를 포함시켜 다음과 같이 정의된다. \[
F = \frac{\text{Regression Variation} / \text{df}_{\text{Regression}}}{\text{Residual Variation} / \text{df}_{\text{Residual}}}
\tag{38.12}\]
이 경우 F-통계량은 다음과 같이 계산된다. 계산된 p-값은 위에서 설명한 t-검정과 동일하다.
Df Sum Sq Mean Sq F value Pr(>F)
X 1 45.59 45.59 57.54 1.05e-07 ***
Residuals 23 18.22 0.79
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
결정 계수(coefficient of determination) \(R^2\)는 회귀 모델이 설명하는 변동의 비율을 나타내며, 다음과 같이 계산된다. 이 값은 0과 1 사이의 값을 가지며, 값이 클수록 회귀 모델이 데이터를 잘 설명한다는 것을 의미한다. 즉 Residual Variation이 거의 없어 0으로 근접한다는 것을 의미하고, 이것은 모델에 데이터를 잘 맞춘다(goodness of fit)고 한다.
물론 회귀식을 구하는 방법은 최소제곱법(least squares)만 있는 것은 아니지만, 회귀의 원리를 이해하는 데는 많은 도움이 되고 많이 사용되므로 알아두면 좋을 것 같다. 베이스 R에서는 lm() 함수를 사용하여 쉽게 계산할 수 있다. 그리고, 회귀에서 사용되는 개념들을 정리해 보았다.
Draper, Norman Richard, and H. Smith. 1998. Applied Regression Analysis. 3rd ed. Wiley Series in Probability and Statistics. New York Chichester Weinheim [etc.]: J. Wiley & sons.