library(pROC)
data(aSAH, package = "pROC")
roc_obj <- roc(aSAH$outcome, aSAH$s100b)
plot(roc_obj, main = "ROC Curve", col = "blue", lwd = 2)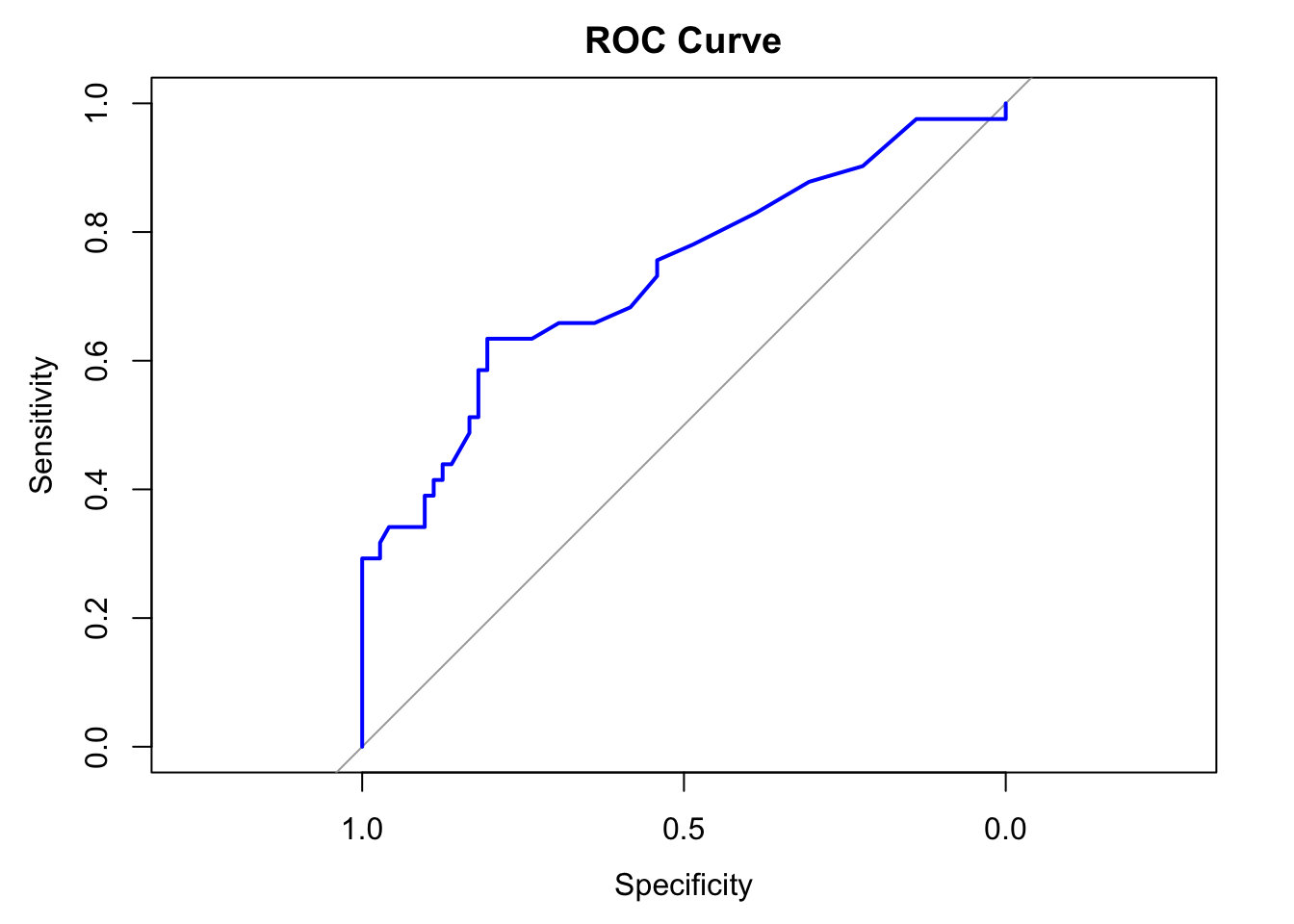
auc_value <- auc(roc_obj)
auc_valueArea under the curve: 0.7314어떤 진단 도구의 민감도(sensitivity)가 99%라고 할 때, 이 검사 결과가 양성일 때 이 환자가 해당 질환을 가질 확률이 99%가 아닌 이유에 대해서 이야기하려고 한다.
이것을 이해하려면 확률, 특히 조건부 확률(conditional probability)을 이해해야 한다. 그런데 조건부 확률은 직관적으로 이해하기 어려운 경우가 많기 때문에 항상 분석적인 방법으로 접근할 필요가 있다.
확률을 잠깐 리뷰해 보자.
우리는 직관적으로 다음과 같이 확률을 이해한다.
여기에 “앞면이 나오는 것”, “1이 나오는 것”은 각각 사건(event)이라고 한다. “동전의 앞면이 나오는 사건”에 대한 확률을 P(앞면)이라고 하고, “주사위에서 1이 나오는 사건”에 대한 확률을 P(1)이라고 쓴다. 단순한 하나의 사건의 대한 확률을 단순 확률(simple probability)이라고 한다.
나올 수 있는 모든 경우를 합쳐, 전체 사건(sample space)이라고 부른다. 동전의 경우 전체 사건은 앞면과 뒷면이므로 S = {앞면, 뒷면}이다. 주사위의 경우 전체 사건은 S = {1, 2, 3, 4, 5, 6}이 된다. 전체 사건에 대한 확률은 항상 1이 된다. 즉, P(S) = 1이다.
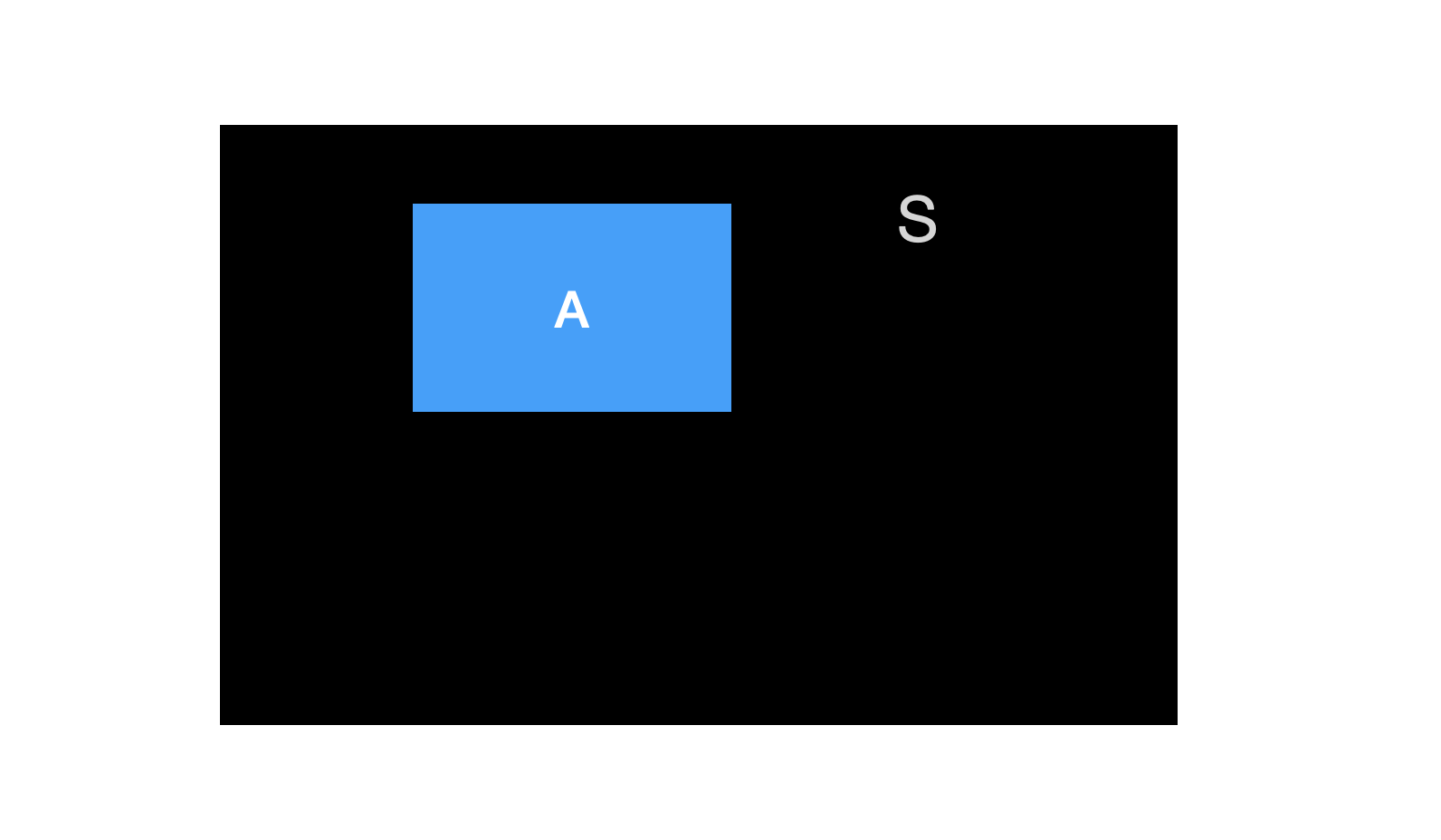
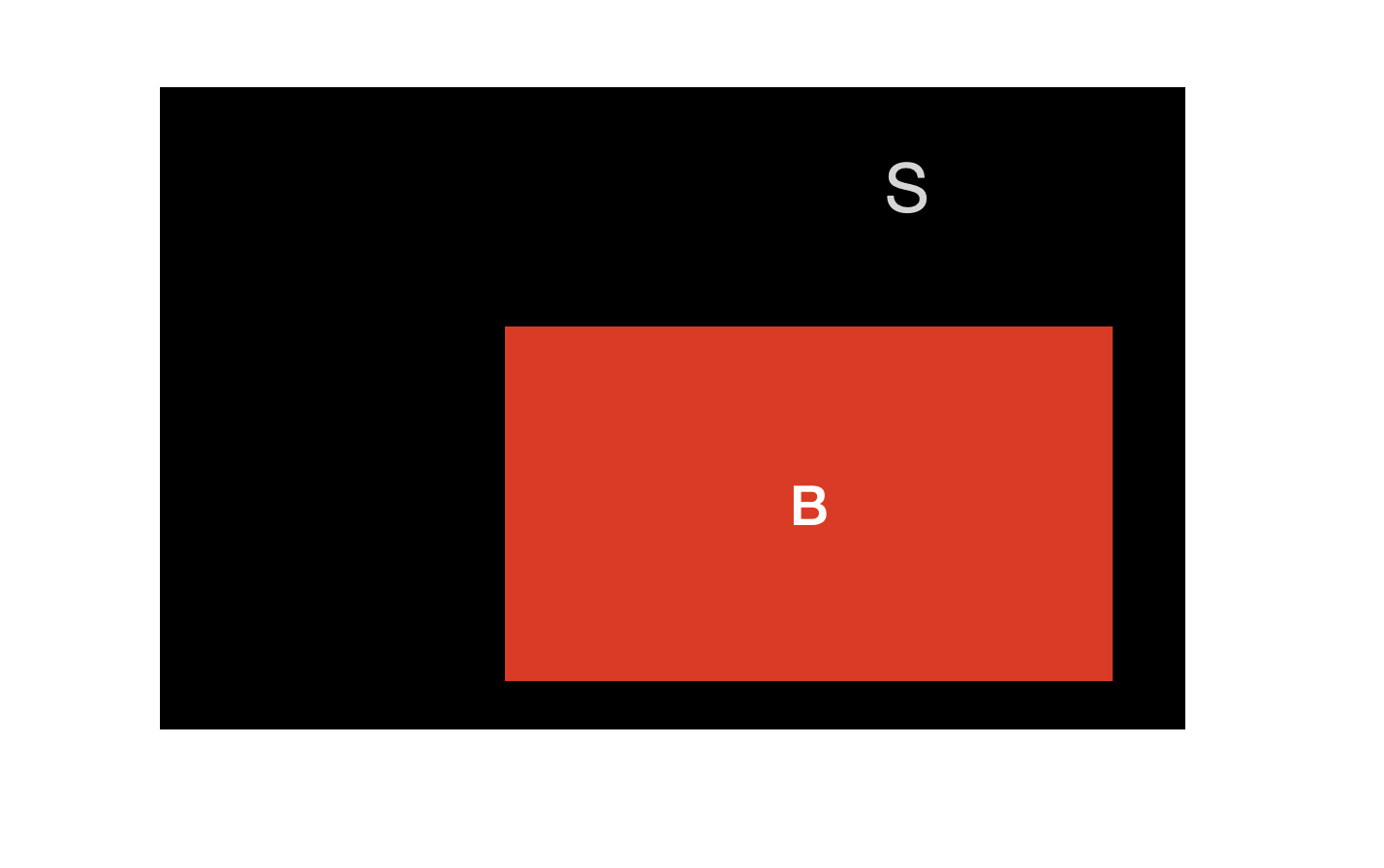
A와 사건 B의 면적을 각각 \(A\)와 \(B\)라고 하고, 전체 사건의 면적을 \(S\)라고 하자.
사건 A와 사건 B를 같이 고려해 보자. 이 사건들은 다음과 같은 관계를 가질 수 있다.
A와 B가 아무런 관련이 없을 때를 독립(independent)이라고 한다.A가 발생하는 것과 사건 B와 관련이 있는 경우, 즉 서로 영향을 주는 경우를 종속(dependent)이라고 한다.사건 A와 사건 B가 독립인 경우 다음과 같이 표현할 수 있다.
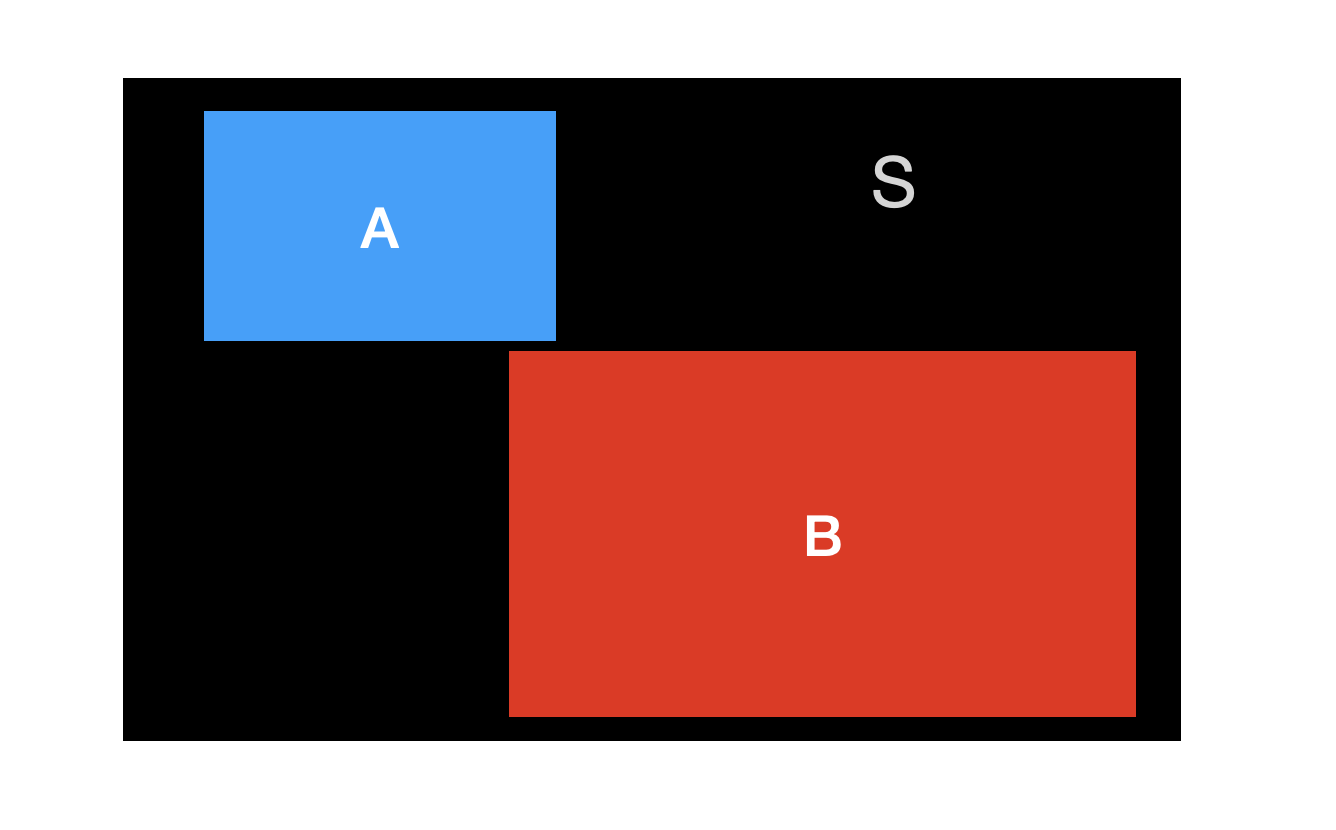
사건 A와 사건 B가 독립이 아니어서 서로 영향을 주는 경우, 즉 종속인 경우 다음과 같이 표현할 수 있다.
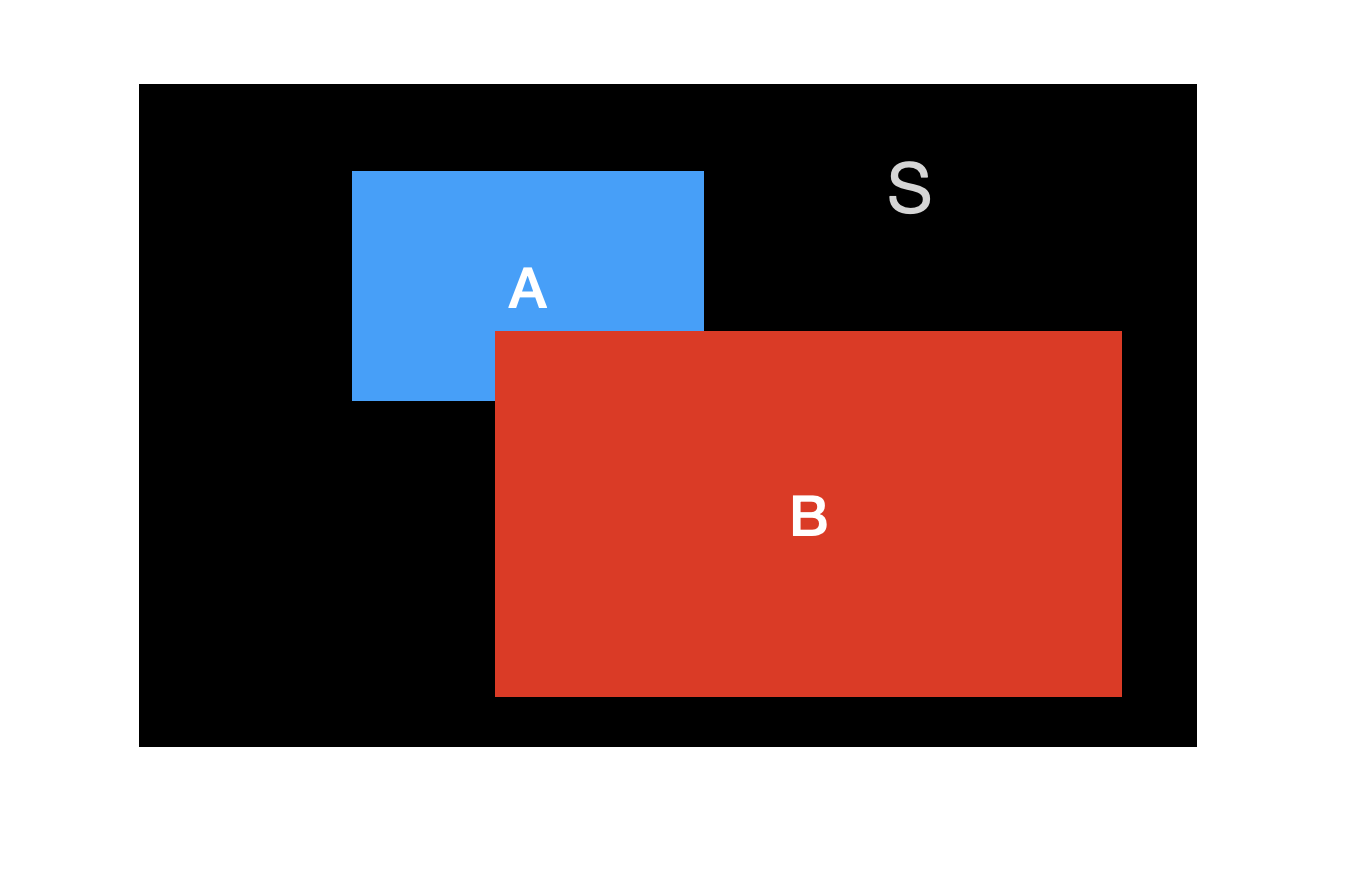
우리는 때론 어떤 사건이 발생했다는 정보를 이미 알고 있는 경우가 있다. 이런 정보에 바탕을 두고 다른 사건이 발생할 확률을 조건부 확률(conditional probability)이라고 한다. 예를 들어, 어떤 사람의 진단 검사 결과가 양성이라고 할 때, 이 환자가 실제로 질병을 가지고 있을 확률을 알고 싶다면 조건부 확률을 사용해야 한다. 반대로 민감도의 개념을 보면, 어떤 질병을 가지고 있는 환자(이미 알고 있는 정보)가 진단 검사 결과가 양성이 나올 확률이다. 이 역시도 조건부 확률이다.
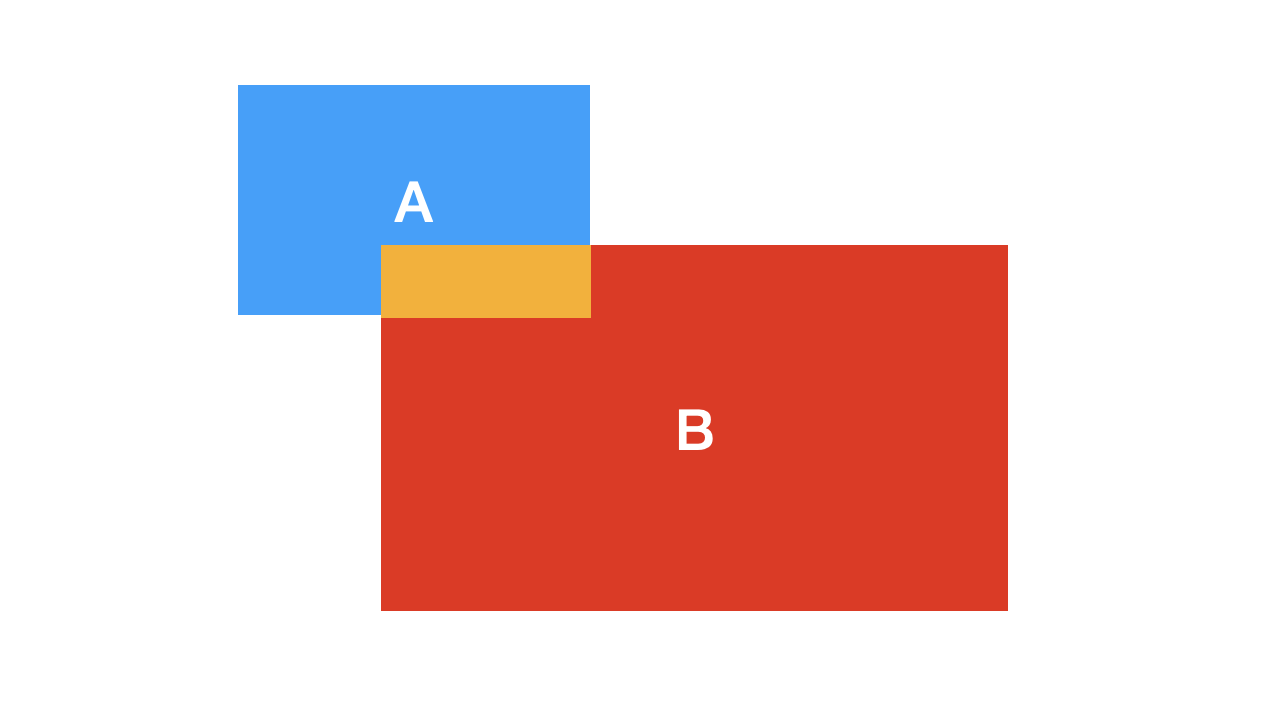
사건 A가 발생했다는 정보가 주어졌을 때, 사건 B가 발생할 확률을 \(P(B|A)\)라고 쓴다. 이때 \(P(B|A)\)는 “사건 A가 발생한 조건 하에서 사건 B가 발생할 확률”이라고 읽는다.
반대로 사건 B가 발생했다는 정보가 주어졌을 때, 사건 A가 발생할 확률은 \(P(A|B)\)라고 쓴다. 이때 \(P(A|B)\)는 “사건 B가 발생한 조건 하에서 사건 A가 발생할 확률”이라고 읽는다.
즉, | 다음에 이미 알고 있는 사건이 온다. 그 이미는 사건 공간이 주어진 상태에서 다른 사건의 확률을 보는 것이다. 다음은 조건부 확률을 그림으로 표현해 본 것이다. “C”라는 사건은 “사건 A와 B가 모두 발생한 사건”이라고 하자. 그림에서 보는 바와 같이 일반적으로 P(A|B)와 P(B|A)는 서로 다르다.
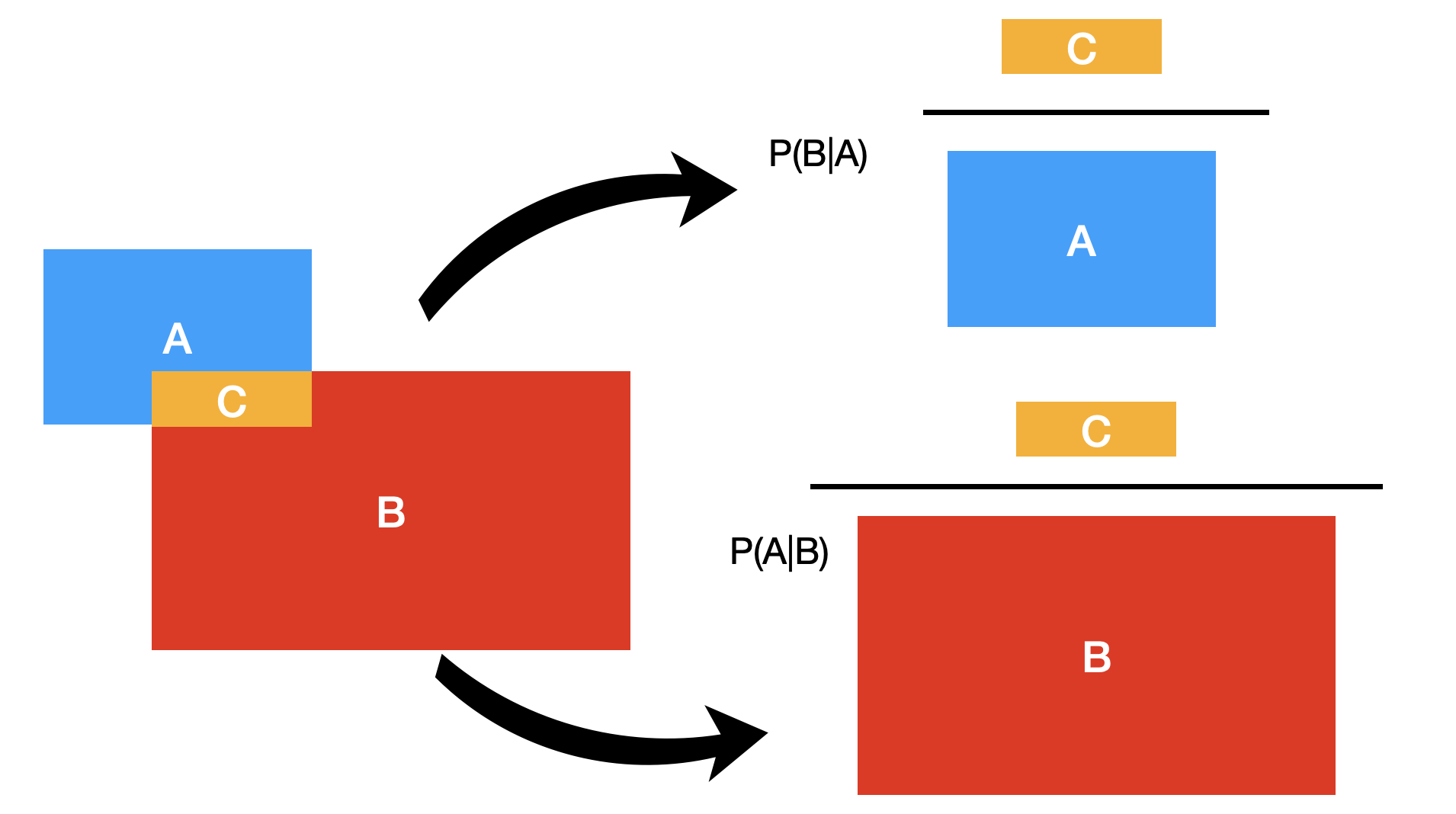
따라서 어떤 환자에서 진단 검사가 양성일 확률과 진단 검사가 양성일 때 환자가 실제로 질병을 가지고 있을 확률은 다음과 같이 서로 다르다.
앞에서 사건 C는 “사건 A와 B가 모두 발생한 사건”이라고 했다. 이때 사건 C의 확률을 결합 확률(joint probability)라고 하고, \(P(A,B)\), \(P(A \cap B)\), 또는 \(P(A \text{ and } B)\) 등으로 표현한다. 이 확률을 그림으로 표현하면 다음과 같다.
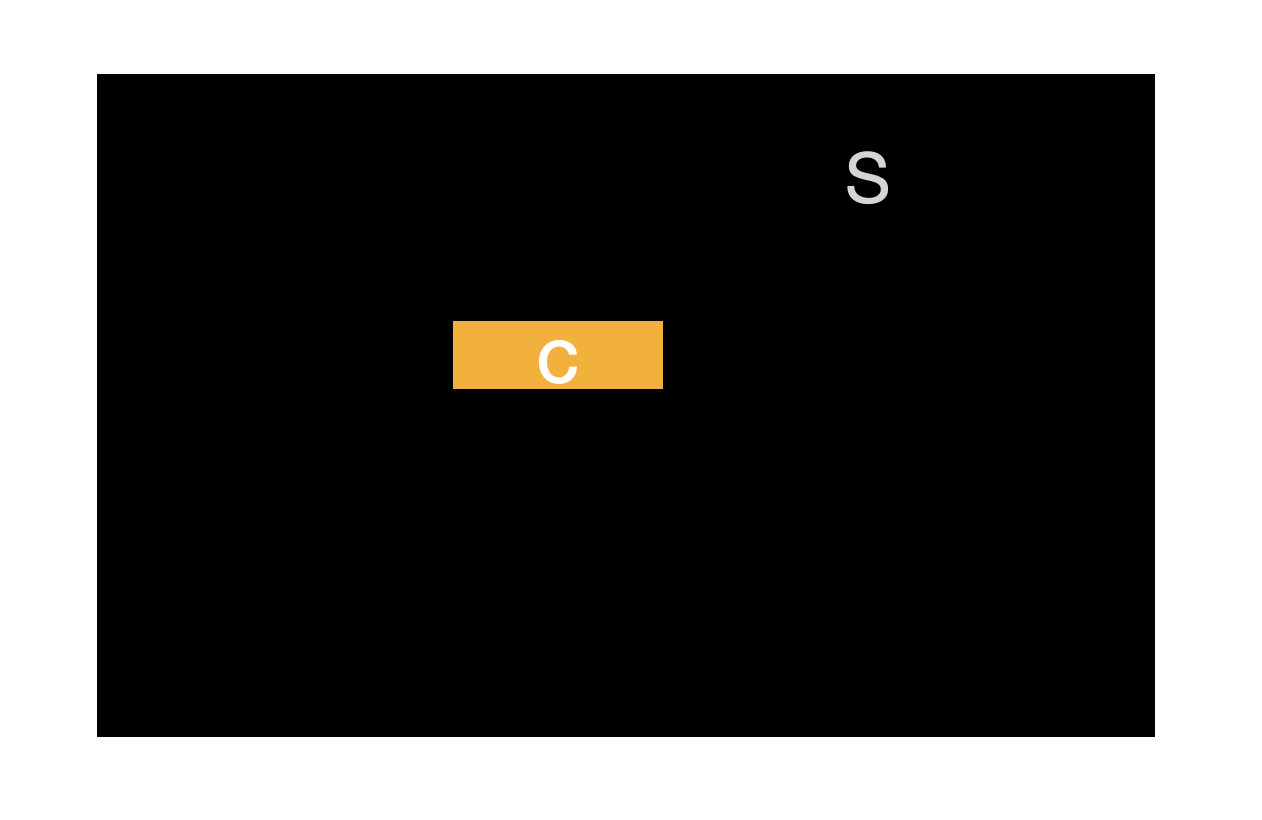
결합 확률과 조건부 확률의 관계를 살펴 보자. 먼저 P(B|A)와 관계를 볼 것이다.
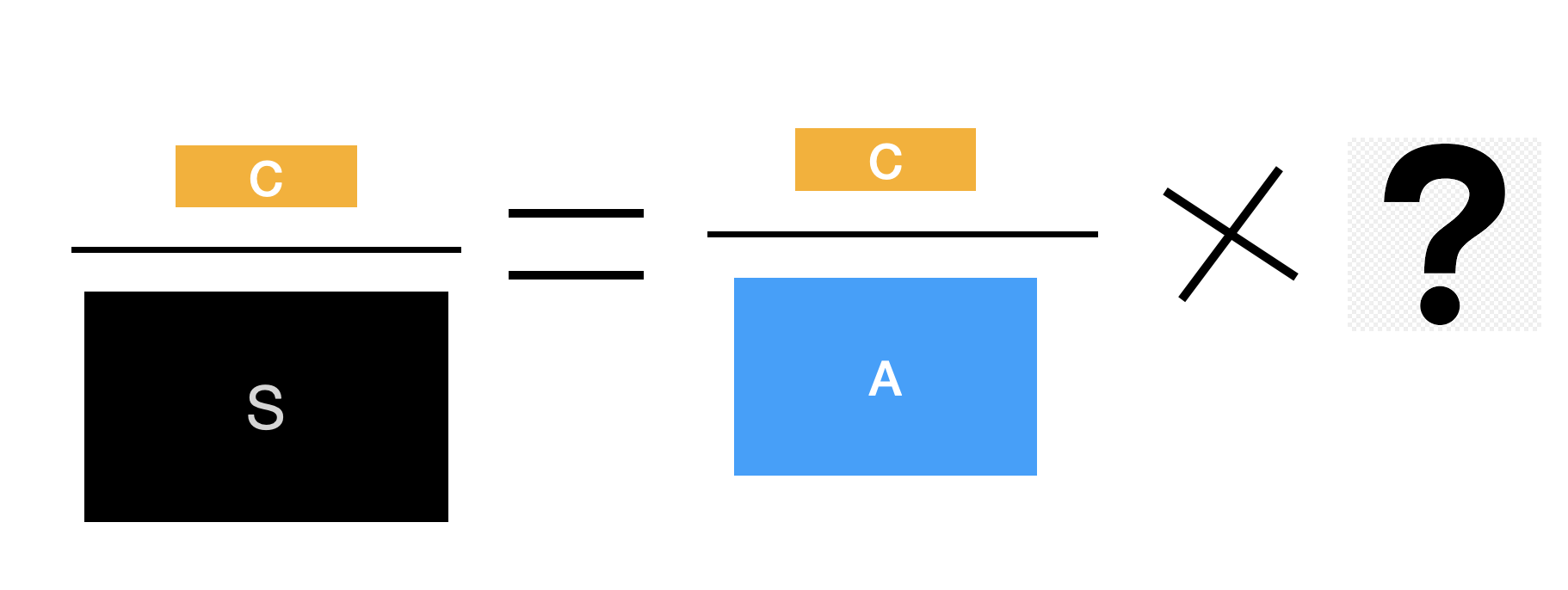
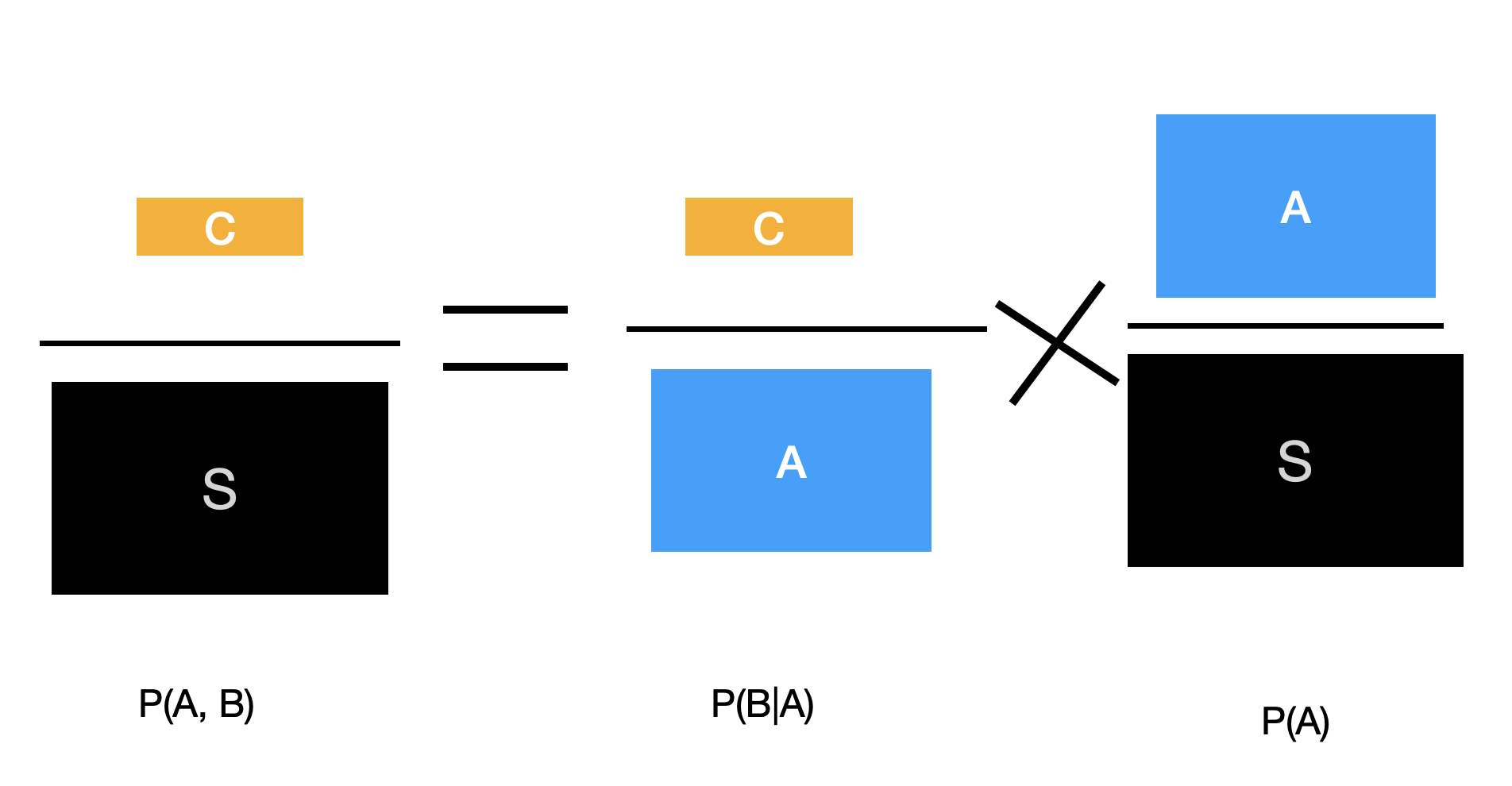
정답은 아래와 같다. 즉, \(P(A,B) = P(B|A) \times P(A)\)이다.
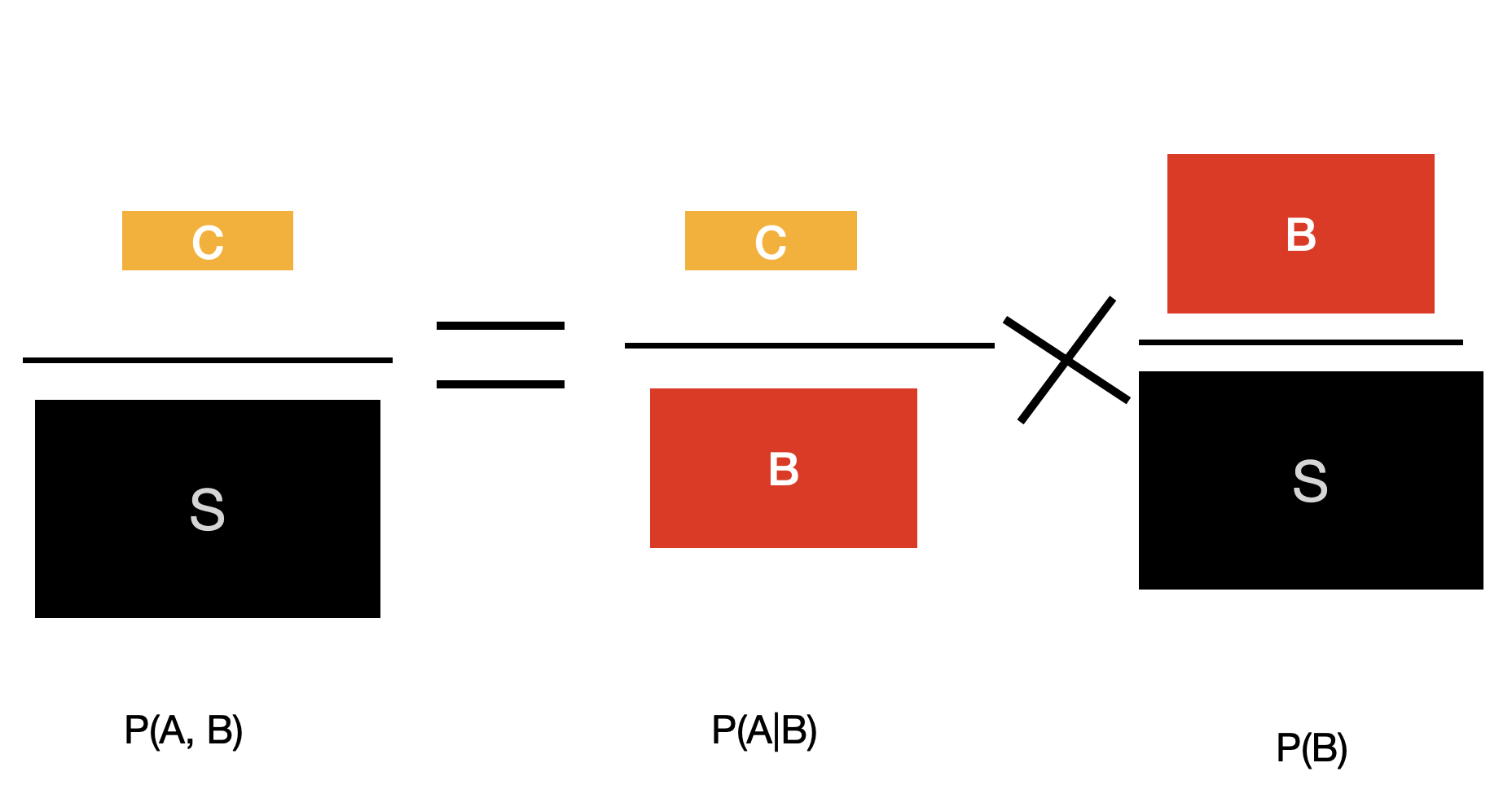
다음은 P(A|B)와 관계를 보자. 위에서 A를 B로 바꾸기면 하면 될 것이다. 수식으로 표현하면 \(P(A, B) = P(A|B) \times P(B)\)이다.
위해서 결합 확률을 2가지 방법으로 표현할 수 있음을 보았다. 따라서 결합 확률은 다음과 같이 표현할 수 있다.
\[ P(A,B) = P(B|A) \times P(A) = P(A|B) \times P(B) \]
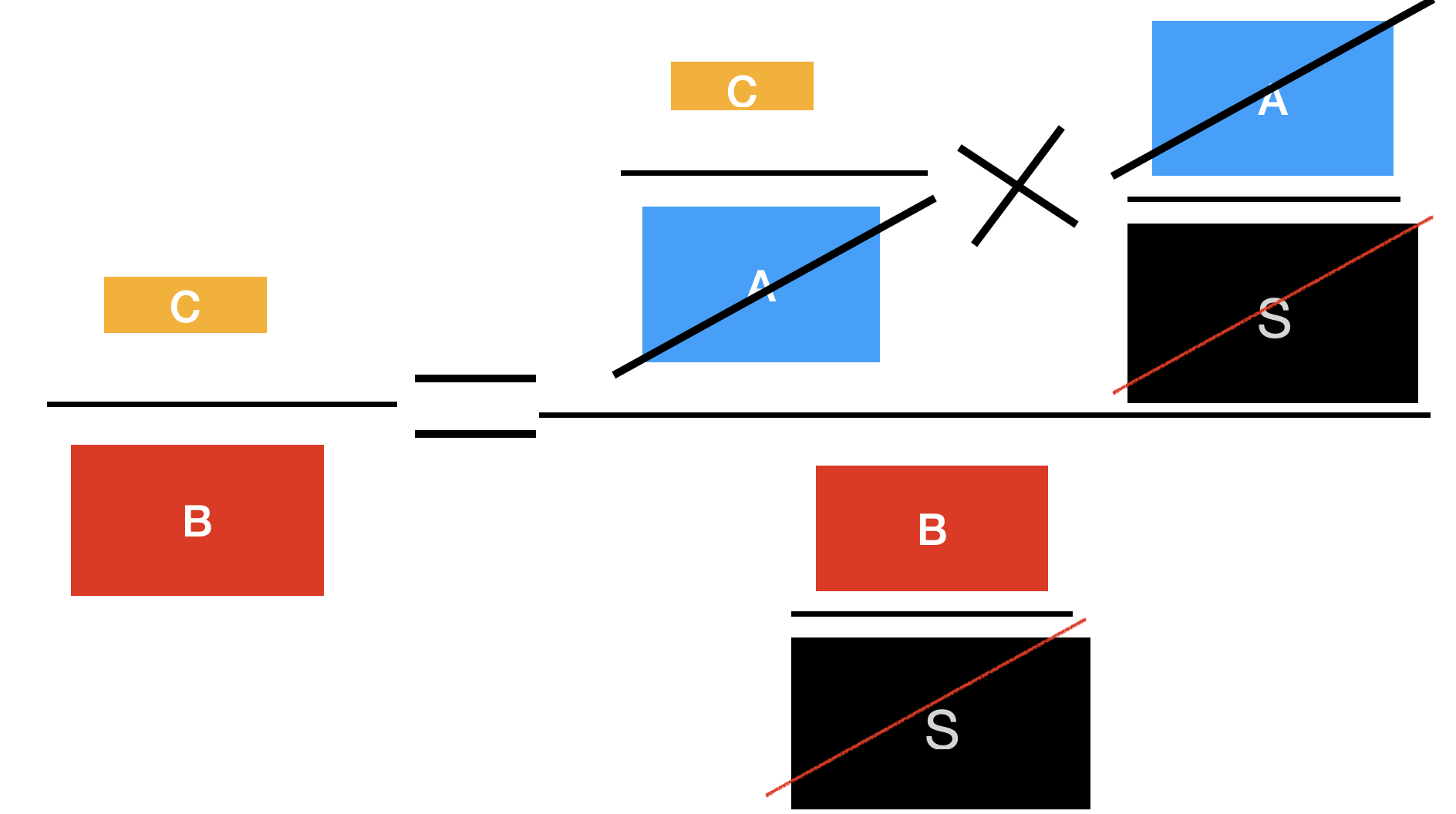
그래서 조건부 확률은 다음과 같이 표현할 수 있다.
\[ P(A|B) = \frac{P(B|A) \times P(A)}{P(B)} \]
굳이 위 그림으로 표현하면 다음과 같다.
또는 다음과 같이 표현할 수도 있다.
\[ P(B|A) = \frac{P(A|B) \times P(B)}{P(A)} \]
이것을 베이즈의 정리(Bayes’ theorem)라고 한다.
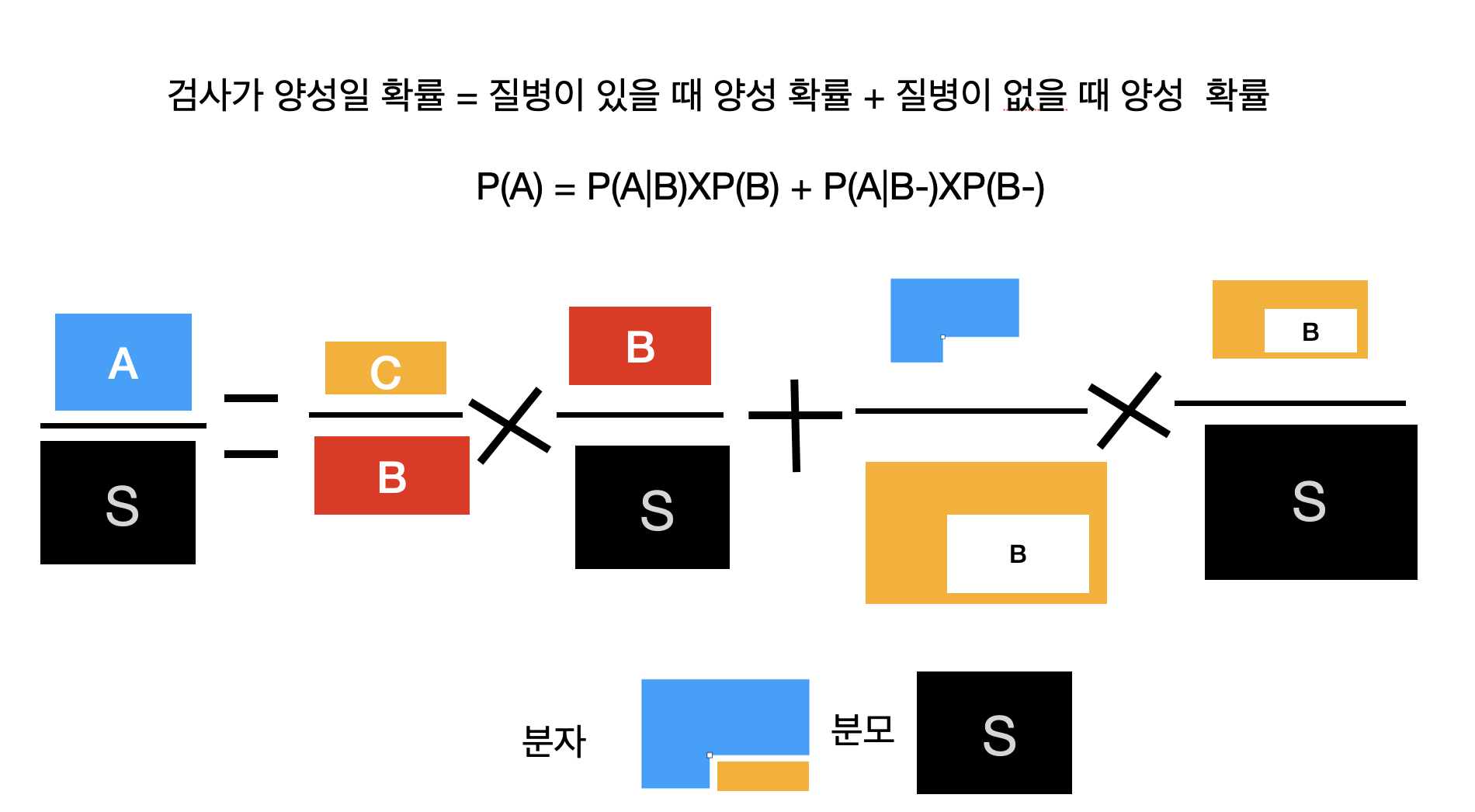
그리고 어떤 사건의 확률은 전체 사건의 확률의 합으로 표현할 수 있다. 즉,
\[
P(A) = P(A|B) \times P(B) + P(A|\neg B) \times P(\neg B)
\] 여기서 \(\neg B\)는 사건 B가 발생하지 않는 사건을 의미한다.
그림으로 표현하면 다음과 같다.
처음의 예로 돌아가서, 민감도가 99%인 검사 도구로 시행한 검사가 양성이었을 때, 이 환자가 실제로 질병을 가지고 있을 확률이 99%가 아닌 이유를 이해해 보자.
P(질병)과 \(P(양성|\neg 질병)\)이라는 추가 정보가 필요한데, 이것은 진단 도구의 특이도(specificity)와 관련이 있다. P(질병)은 질병이 있는 환자의 비율로 유병률(prevalence)이라고도 한다.다음은 ChatGPT가 작성해 준 내용이다.
진단 도구의 민감도(sensitivity)와 특이도(specificity)를 이해하기 위해, 다음과 같은 상황을 가정해 보자.
이제 이 진단 도구를 사용한 검사가 양성으로 나왔을 때, 이 환자가 실제로 질병을 가지고 있을 확률을 계산해 보자. 먼저, 다음과 같이 사건을 정의하자.
A: 환자가 질병을 가지고 있다.B: 진단 도구가 양성으로 나왔다.이때, 다음과 같은 확률을 구할 수 있다.
P(A): 환자가 질병을 가지고 있을 확률 = 1%P(B|A): 환자가 질병을 가지고 있을 때 진단 도구가 양성으로 나올 확률 = 99%P(B|\neg A): 환자가 질병을 가지고 있지 않을 때 진단 도구가 양성으로 나올 확률 = 5% (즉, 특이도가 95%이므로 음성으로 나올 확률은 5%이다.)이제, P(A|B)를 구하기 위해 베이즈의 정리를 사용하자.
\[
P(A|B) = \frac{P(B|A) \times P(A)}{P(B)}
\] 먼저 P(B)를 구해야 한다. P(B)는 다음과 같이 계산할 수 있다. \[
P(B) = P(B|A) \times P(A) + P(B|\neg A) \times P(\neg A)
\]
여기서 \(P(\neg A)\)는 환자가 질병을 가지고 있지 않을 확률로, 99%이다. 따라서 P(B)는 다음과 같이 계산할 수 있다. \[
P(B) = P(B|A) \times P(A) + P(B|\neg A) \times P(\neg A)
\] \[
P(B) = 0.99 \times 0.01 + 0.05 \times 0.99
\] \[
P(B) = 0.0099 + 0.0495 = 0.0594
\] 이제 P(A|B)를 구할 수 있다. \[
P(A|B) = \frac{P(B|A) \times P(A)}{P(B)} = \frac{0.99 \times 0.01}{0.0594} \approx 0.1667
\] 즉, 진단 도구가 양성으로 나왔을 때, 이 환자가 실제로 질병을 가지고 있을 확률은 약 16.67%이다.
이것을 양성 예측도(Positive Predictive Value, PPV)라고 한다. 양성 예측도는 진단 도구가 양성으로 나왔을 때, 환자가 실제로 질병을 가지고 있을 확률을 의미한다.
진단 도구의 성능을 평가할 때, 혼동 행렬(confusion matrix)을 사용한다.
| 검사 양성 (Positive) | 검사 음성 (Negative) | |
|---|---|---|
| 질병 양성 (Positive) | True Positive (TP) | False Negative (FN) |
| 질병 음성 (Negative) | False Positive (FP) | True Negative (TN) |
Confusion matrix에서 각 칸에 들어가는 값은 카운트(count)라는 사실을 잊지 않아야 한다. 즉, 각 칸에 들어가는 값은 해당 조건을 만족하는 환자의 수를 의미한다. 예를 들어, TP는 질병이 있는 환자 중에서 검사 결과가 양성인 환자의 수를 의미한다. 만약 Sensitivity를 99%라고 했을 때 TP에 0.99, FN에 0.1 등으로 입력했을 것은 잘못된 것이다. 개수를 세서 입력해서 한다.
이 혼돈 행렬을 사용하여 진단 도구의 민감도와 특이도를 계산할 수 있다.


예를 들어, 다음과 같은 혼동 행렬이 있다고 가정해 보자.
| 검사 양성 (Positive) | 검사 음성 (Negative) | |
|---|---|---|
| 질병 양성 (Positive) | 90 | 10 |
| 질병 음성 (Negative) | 5 | 95 |
이 경우 민감도와 특이도는 다음과 같다.
양성 예측도(Positive Predictive Value, PPV)와 음성 예측도(Negative Predictive Value, NPV)도 혼동 행렬을 사용하여 계산할 수 있다.

위 예에서는 양성 예측도는 다음과 같이 계산된다. \[ PPV = \frac{90}{90 + 5} = \frac{90}{95} \approx 0.9474 \]

위 예에서는 음성 예측도는 다음과 같이 계산된다.
\[ NPV = \frac{95}{95 + 10} = \frac{95}{105} \approx 0.9048 \]
이 경우 양성 예측도가 약 94.74%로 나왔는데 이전 절에서 계산한 16.67%와는 차이가 있다. 이런 차이는 유병률과 관련이 있다. 이번 경우에는 질병이 있는 군이 100명, 없는 군이 100명으로 유병률이 50%인 반면, 이전 예에서는 질병이 있는 군이 1명, 없는 군이 99명으로 유병률이 1%였다. 유병률이 높으면 양성 예측도가 높아지고, 유병률이 낮으면 양성 예측도가 낮아진다.
앞에서 베이즈 정리를 사용하여 양성 예측도를 구했는데, 이번에는 혼동 행렬을 사용하여 풀어 보자.
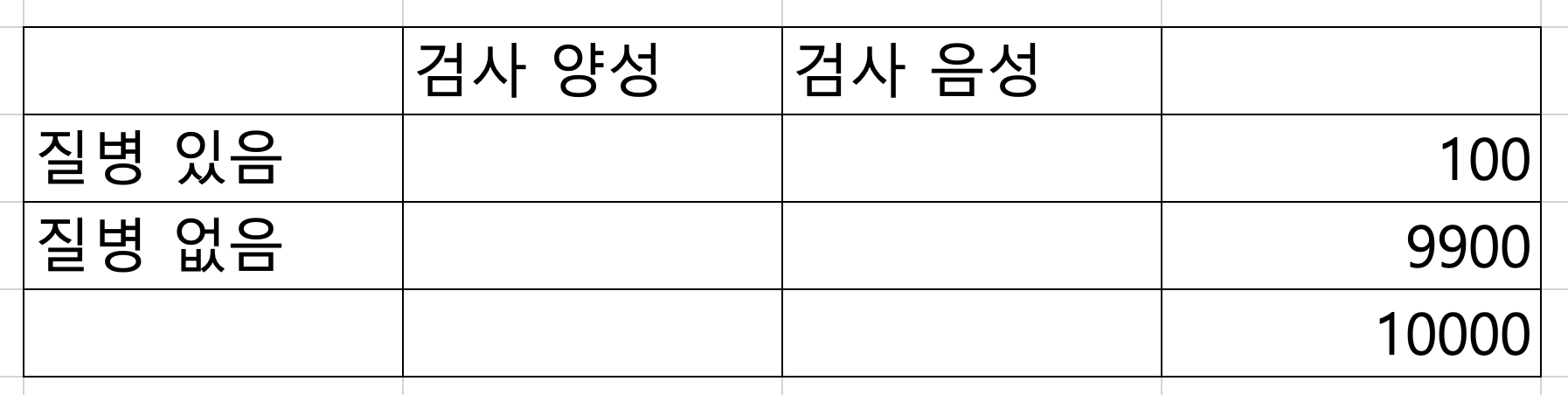
먼저 혼동 행렬을 그린다. 전체가 10,000명이라고 가정하자.

유병률이 1%라고 했으므로, 질병이 있는 환자는 100명, 없는 환자는 9,900명이다.
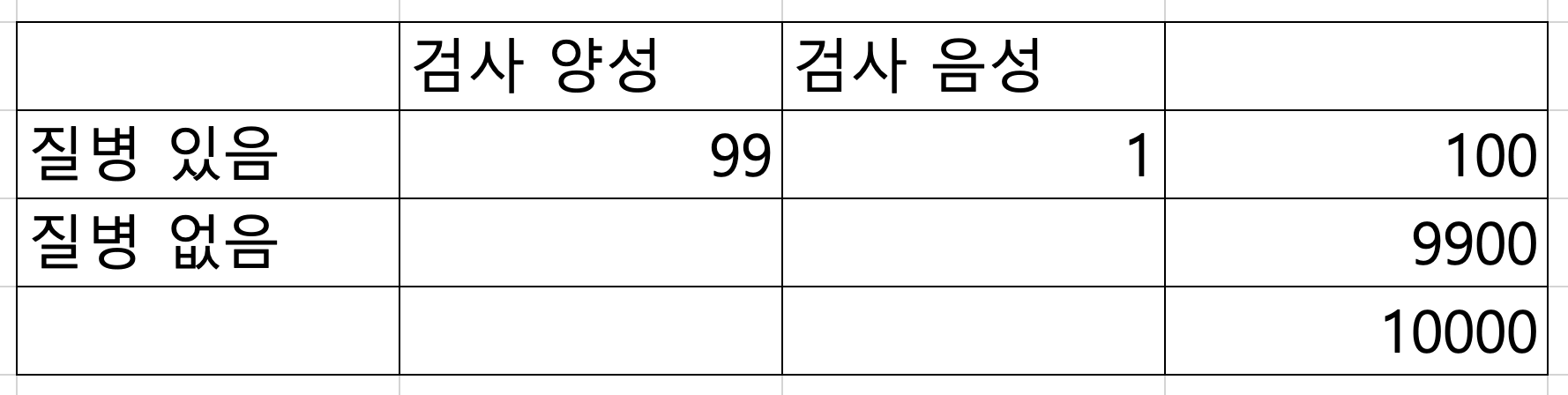
민감도가 99%라고 했으므로, 질병이 있는 환자 100명 중 99명이 양성으로 나올 것이다. 없는 환자 1명은 음성으로 나온다.
특이도가 95%라고 했으므로, 질병이 없는 환자 9,900명 중 9,405명이 음성으로 나온다. 양성으로 나온 환자는 495명이다.
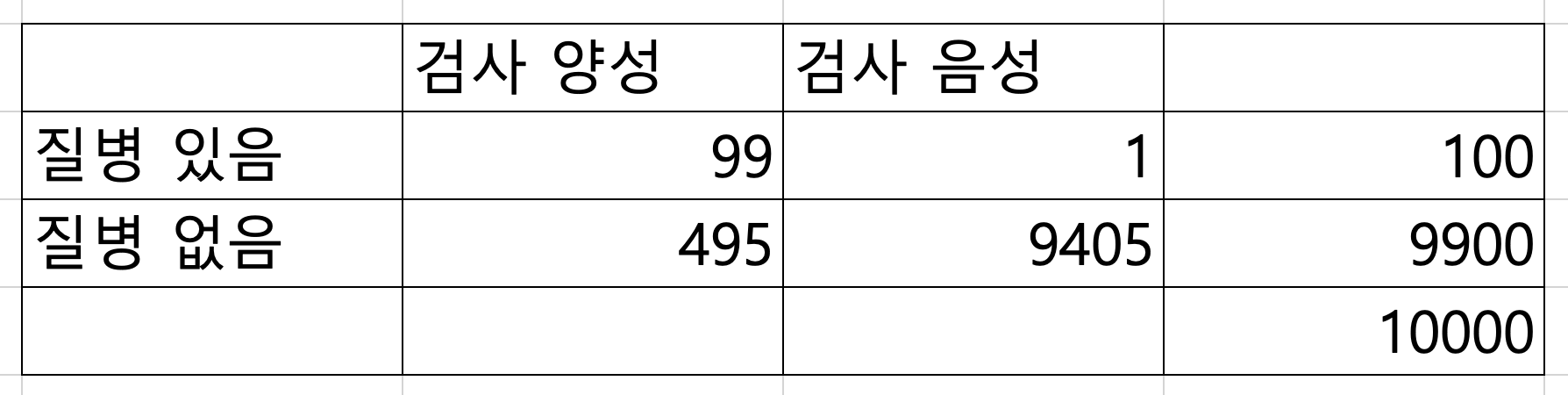
이렇게 해서 혼동 행렬이 완성되었다. 이제 양성 예측도를 구할 수 있다.
\[ \frac{99}{99 + 495} = \frac{99}{594} \approx 0.1667 \]
혼동 행렬을 사용하여 수많은 지표들이 많들 수 있다. 여기 그걸들을 다 언급할 필요는 없을 것이다. 공식을 보고 그 의미를 이해는 데 초점을 맞출 필요가 있다.
| 검사 양성 (Positive) | 검사 음성 (Negative) | |
|---|---|---|
| 질병 양성 (Positive) | True Positive (TP) | False Negative (FN) |
| 질병 음성 (Negative) | False Positive (FP) | True Negative (TN) |
다음은 우도비(Likelihood Ratio)이다. 우도비는 진단 도구의 성능을 평가하는 데 사용된다. 양성 우도비와 음성 우도비가 있다. 양성 우도비의 공식을 보면 질병이 있는 환자와 없는 환자에서 검사가 양성일 확률의 비율을 나타낸다. 음성 우도비는 질병이 있는 환자와 없는 환자에서 검사가 음성일 확률의 비율을 나타낸다. 양성 우도비가 높으면 진단 도구가 양성 결과를 잘 식별한다는 의미이고, 음성 우도비가 낮으면 음성 결과를 잘 식별한다는 의미이다. 여러 검사법을 비교하여 채택하거나 배제할 때 유용하다.
양성 우도비(Positive Likelihood Ratio, LR+): \(LR+ = \frac{P(양성|질병)}{P(양성|\neg 질병)} = \frac{TP/(TP + FN)}{FP/(FP + TN)}\)
음성 우도비(Negative Likelihood Ratio, LR-): \(LR- = \frac{P(음성|질병)}{P(음성|\neg 질병)} = \frac{FN/(TP + FN)}{TN/(FP + TN)}\)
이것을 sensitivity와 specificity로 표시할 수도 있다.
양성 우도비: \(LR+ = \frac{Sensitivity}{1 - Specificity} = \frac{TP/(TP + FN)}{FP/(FP + TN)}\)
음성 우도비: \(LR- = \frac{1 - Sensitivity}{Specificity} = \frac{FN/(TP + FN)}{TN/(FP + TN)}\)
이외에도 다양한 지표들이 있다. 의료인들인 경우 혼돈 행렬을 진단 도구에 대해서 주로 사용하는데, 실은 이런 지표들은 머신러닝 등 AI 분야에서도 널리 사용된다. 그 의미는 거의 동일하다.
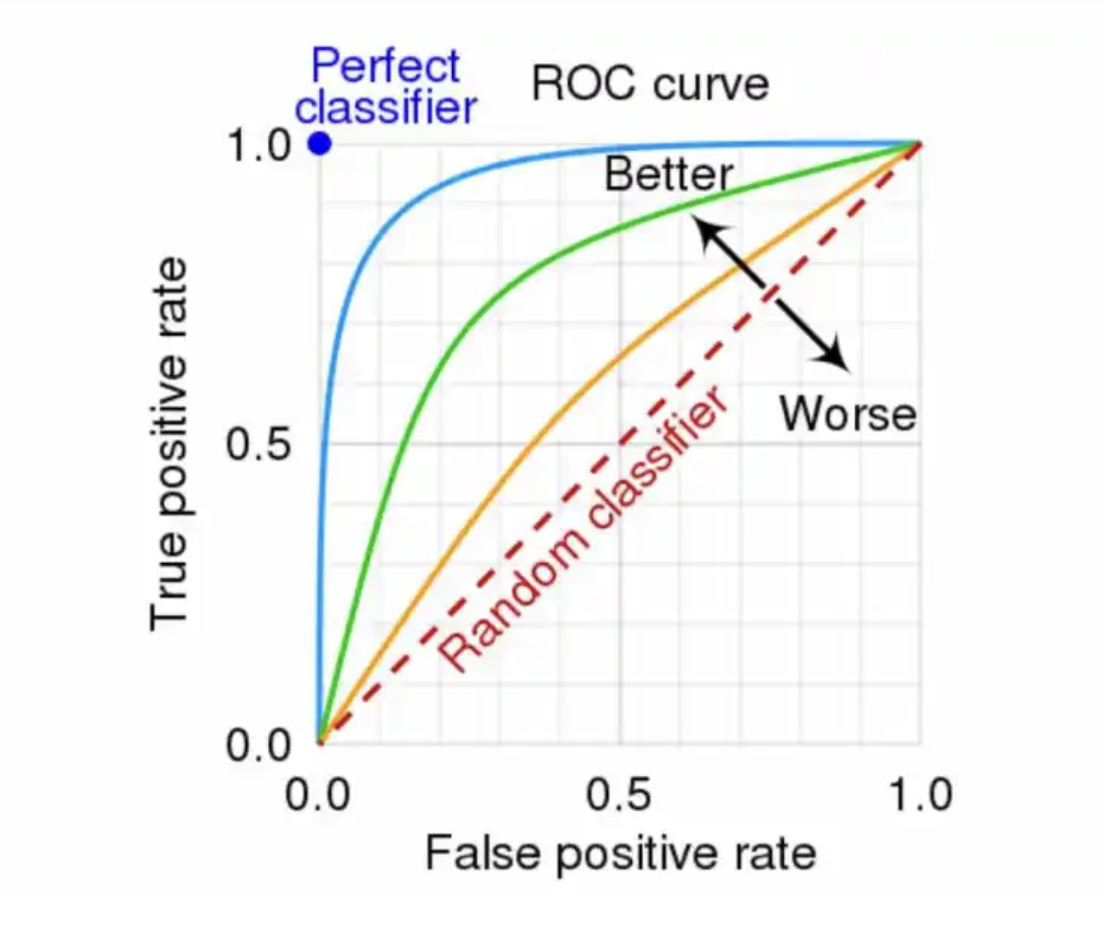
ROC 커브는 진단 도구의 민감도와 특이도를 시각적으로 나타낸 것이다.

일반적으로 기준을 강화하면 민감도는 높아지고, 특이도는 낮아진다. 즉, 민감도와 특이도 사이의 트레이드오프(trade-off)가 있다. ROC 커브는 이 트레이드오프를 시각적으로 나타낸 것이다.
ROC 커브는 기준(threshold, 역치)를 변화시키면서, 각 역치에서의 민감도와 특이도를 계산하여 그래프를 만든다. 민감도와 특이도 값을 그대로 사용하는 대신 보통 x축에는 1 - 특이도(1 - Specificity)를 사용하여 ROC 커브를 그린다. 그렇지만 반드시 그런 것은 아니다. pROC R 패키지와 같은 경우에는 x축에 특이도(Specificity)를 사용하는데, 0에서 1(100%)로 증가하는 것이 아니라, 1(100%)에서 0으로 감소하는 형태로 표현한다. 같은 의미이고, 단지 표현 방식이 다를 뿐이다.
그리고 이 곡선 아래의 면적(AUC, Area Under the Curve)은 진단 도구의 성능을 평가하는 데 사용된다. AUC가 1에 가까울수록 진단 도구의 성능이 우수하다는 것을 의미한다. AUC가 0.5이면 무작위로 선택한 것과 같다는 의미이다.
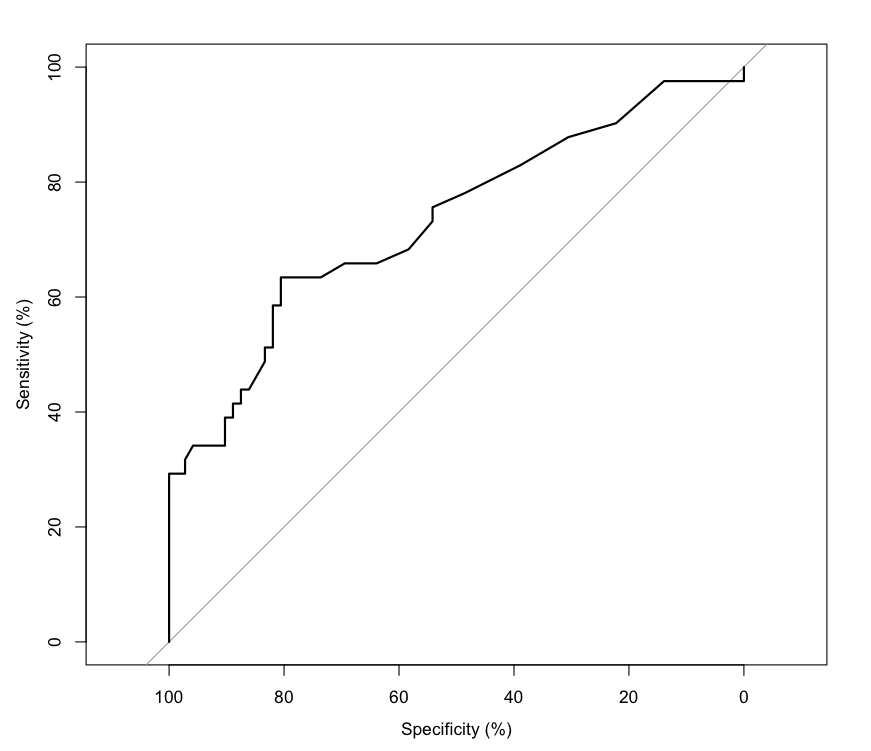
pROC 패키지를 사용하여 ROC 커브를 그릴 수 있다. 다음은 pROC 패키지를 사용하여 ROC 커브를 그리는 예시 코드이다. 앞에서 설명했듯이 이 패키지는 100%에서 0으로 감소하는 특이도를 x축으로 사용한다.
여기서는 조건부 확률과 결합 확률을 이해하고, 베이즈의 정리를 통해 진단 도구의 민감도와 특이도를 이해하는 법을 설명했다. 관련된 혼돈 행렬과 그 사용법, ROC 커브와 AUC에 대해서도 설명했다.